

«`html
Neural Magic Releases LLM Compressor: A Novel Library to Compress LLMs for Faster Inference with vLLM
LLM Compressor: Оптимизация больших моделей языков для более быстрого вывода
Neural Magic выпустила LLM Compressor — передовой инструмент для оптимизации больших языковых моделей, который обеспечивает гораздо более быстрый вывод через более продвинутое сжатие моделей. Этот инструмент является важным кирпичиком в стремлении Neural Magic предоставить высокопроизводительные open-source решения сообществу глубокого обучения, особенно внутри vLLM-фреймворка.
Основные технические преимущества
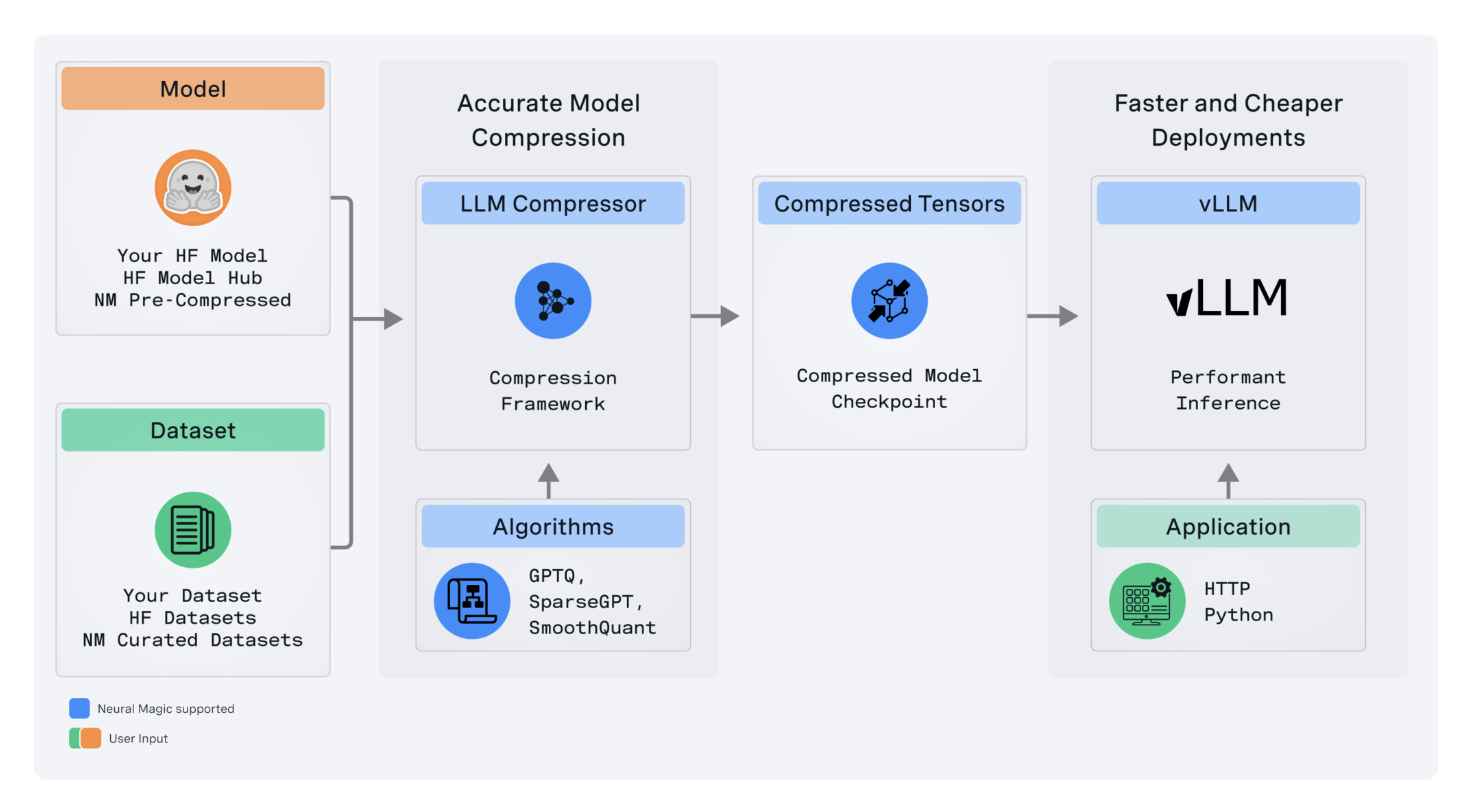
LLM Compressor устраняет трудности, возникающие из фрагментированного ландшафта инструментов сжатия моделей, где пользователи должны были разрабатывать несколько специальных библиотек, подобных AutoGPTQ, AutoAWQ и AutoFP8, для применения определенных алгоритмов квантования и сжатия. Данные фрагментированные инструменты объединены в одну библиотеку LLM Compressor для простого применения передовых алгоритмов сжатия, таких как GPTQ, SmoothQuant и SparseGPT.
Вторым ключевым техническим преимуществом, которое предоставляет LLM Compressor, является поддержка квантования активации и веса. Это важная возможность ускорения вычислений при высоконагруженных рабочих нагрузках, где вычислительный бутылочный горлышко уменьшается за счет использования арифметических устройств меньшей точности.
Более того, LLM Compressor поддерживает передовую структурированную разреженность веса с помощью SparseGPT, что позволяет уменьшить память и обеспечивает развертывание на ресурсоемком оборудовании для LLMs.
Интеграция и расширяемость
LLM Compressor был разработан для легкой интеграции в любую open-source экосистему, особенно в Hugging Face model hub. Инструмент также поддерживает различные схемы квантования с тонкой настройкой, что позволяет очень тонко настраивать квантование с учетом требований к производительности и точности из различных моделей и сценариев развертывания.
Перспективы развития
Технически LLM Compressor предназначен для работы с различными архитектурами моделей с возможностью расширения. В планах развития инструмента — расширение поддержки до MoE моделей, моделей видео-языка и платформ не от NVIDIA. Также запланировано развитие расширенных техник квантования и инструментов для создания неоднородных схем квантования, что позволит дальше увеличить эффективность моделей.
Заключение
LLM Compressor становится важным инструментом для исследователей и практиков в оптимизации LLMs для развертывания в производство. Открытый и с передовыми функциями, он облегчает сжатие моделей и улучшение производительности без ущерба для интегрированных моделей. Инструменты подобные LLM Compressor, будут играть очень важную роль в ближайшем будущем, когда ИИ продолжит масштабироваться и эффективно применять крупные модели на различных аппаратных платформах, делая их более доступными для применения во многих других областях.
«`


















