

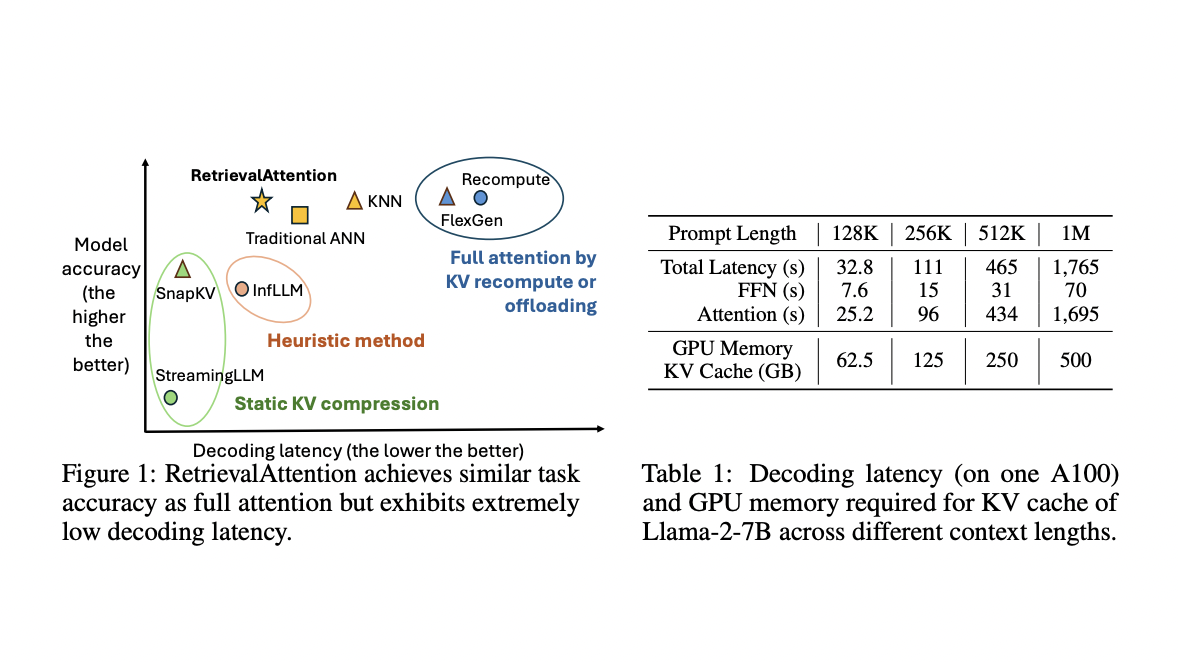
RetrievalAttention: Решение для Ускорения Вычислений Внимания и Снижения Использования Памяти GPU
Проблема:
Большие языковые модели (LLM) имеют сложности с эффективностью вывода из-за высокой сложности вычислений внимания. Решение Llama-2-7B требует огромного объема памяти GPU.
Решение:
Использование динамической разреженности в механизме внимания позволяет снизить затраты на доступ и хранение токенов, улучшая эффективность вывода.
Преимущества:
— Ускорение вывода LLM за счет динамической разреженности внимания.
— Снижение нагрузки на GPU путем переноса большинства векторов KV в память ЦП.
— Повышение точности и эффективности вывода за счет эффективного поиска критически важных токенов.
Результаты:
RetrievalAttention демонстрирует высокую производительность и точность по сравнению с существующими методами, обеспечивая сравнимую точность с полным вниманием при существенном снижении вычислительных затрат и задержек.
Применение в бизнесе:
Используйте RetrievalAttention для улучшения процессов обработки данных и повышения эффективности вывода LLM. Постепенно внедряйте ИИ-решения, начиная с малых проектов и анализируя результаты.
Если вам нужна консультация по внедрению ИИ в ваш бизнес, обращайтесь к нам!

















