

«`html
Retrieval-augmented generation (RAG) в области обработки естественного языка
Retrieval-augmented generation (RAG) — техника, которая повышает эффективность больших языковых моделей (LLM) в обработке обширных объемов текста, критически важна в обработке естественного языка, особенно в приложениях, таких как вопросно-ответные системы, где сохранение контекста информации имеет решающее значение для генерации точных ответов. По мере развития языковых моделей исследователи стремятся расширить границы, улучшая способы обработки и извлечения соответствующей информации из обширных текстовых данных.
Проблема длинных контекстов
Одной из основных проблем существующих LLM является их сложность в управлении длинными контекстами. По мере увеличения длины контекста модели нуждаются в помощи для сохранения четкой фокусировки на соответствующей информации, что может привести к существенному снижению качества их ответов. Эта проблема особенно остро проявляется в задачах вопросно-ответной системы, где важна точность. Модели часто перегружаются объемом информации, что может привести к извлечению нерелевантных данных, разбавляя точность ответов.
Новые разработки в области LLM
В последние годы LLM, такие как GPT-4 и Gemini, были разработаны для обработки гораздо более длинных текстов, с некоторыми моделями, поддерживающими до 1 миллиона токенов в контексте. Однако эти достижения сопровождаются своими собственными вызовами. Длинные контексты LLM теоретически могут обрабатывать более крупные входные данные, но часто вносят ненужные или нерелевантные фрагменты информации в процесс, что приводит к снижению точности. Таким образом, исследователи по-прежнему ищут лучшие решения для эффективного управления длинными контекстами, сохранения качества ответов и эффективного использования вычислительных ресурсов.
Предложение от исследователей NVIDIA
Исследователи из NVIDIA предложили подход order-preserve retrieval-augmented generation (OP-RAG) для решения этих проблем. OP-RAG предлагает существенное улучшение по сравнению с традиционными методами RAG, сохраняя порядок извлеченных текстовых фрагментов для обработки. В отличие от существующих систем RAG, которые определяют приоритет фрагментов на основе оценок релевантности, механизм OP-RAG сохраняет исходную последовательность текста, обеспечивая сохранение контекста и последовательности в процессе извлечения. Это позволяет более структурированно извлекать соответствующую информацию, избегая недостатков традиционных систем RAG, которые могут извлекать высокорелевантные, но не в контексте данные.
Преимущества метода OP-RAG
Метод OP-RAG вводит инновационный механизм перестройки обработки информации. Во-первых, большой текст разбивается на более мелкие последовательные фрагменты. Затем эти фрагменты оцениваются на основе их релевантности для запроса. Вместо того чтобы ранжировать их исключительно по релевантности, OP-RAG обеспечивает сохранение фрагментов в их исходном порядке, в котором они появлялись в исходном документе. Это последовательное сохранение помогает модели сосредоточиться на извлечении наиболее контекстуально релевантных данных без введения нерелевантных отвлечений. Исследователи продемонстрировали, что этот подход значительно повышает качество генерации ответов, особенно в сценариях с длинным контекстом, где важна сохранение последовательности.
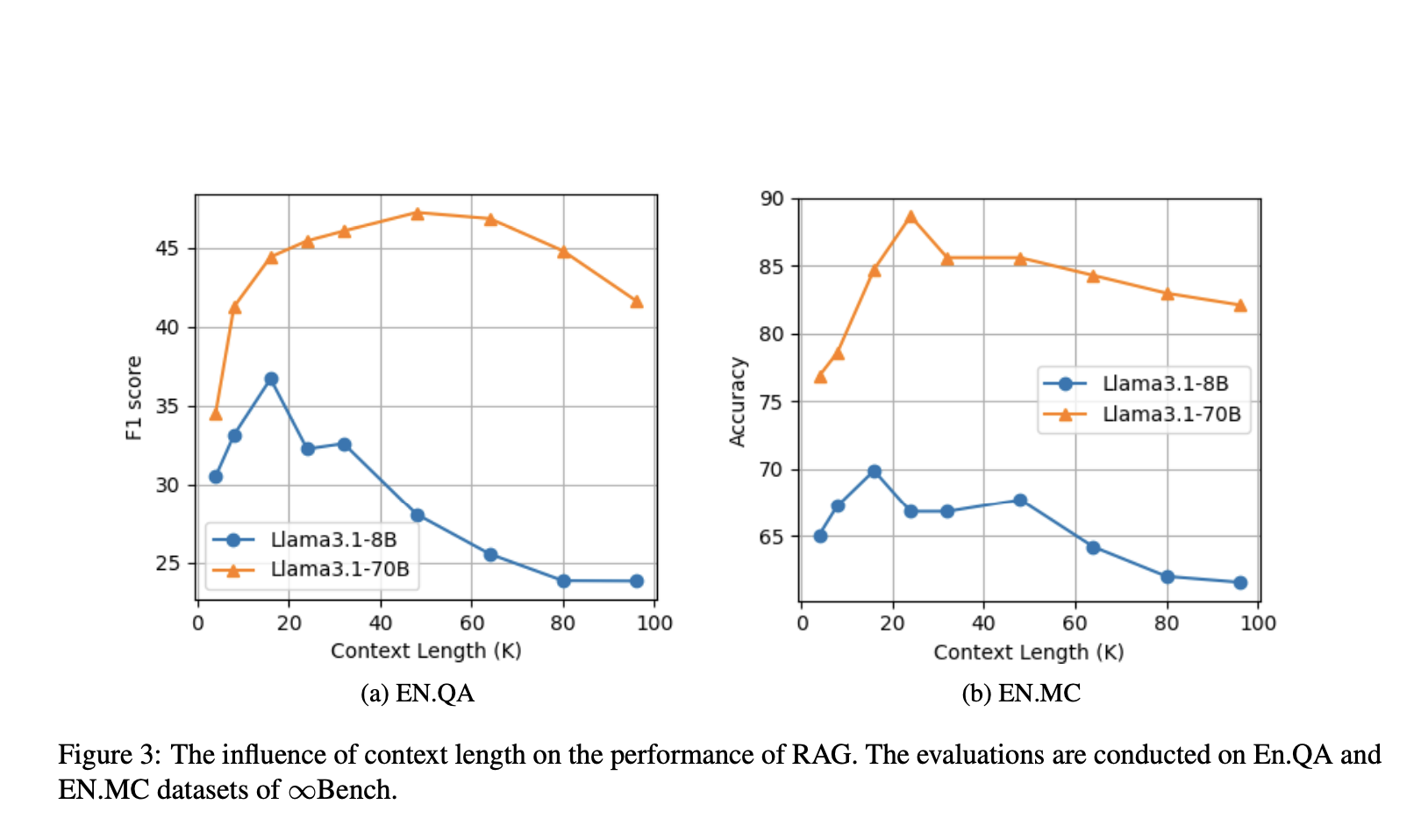
Результаты тестирования метода OP-RAG
Производительность метода OP-RAG была тщательно протестирована по сравнению с другими ведущими моделями. Исследователи из NVIDIA провели эксперименты с использованием общедоступных наборов данных, таких как наборы EN.QA и EN.MC из ∞Bench. Их результаты показали значительное улучшение как в точности, так и в эффективности по сравнению с традиционными длинными контекстами LLM без RAG.
Заключение
OP-RAG представляет собой значительный прорыв в области retrieval-augmented generation, предлагая решение ограничений длинных контекстов LLM. Путем сохранения порядка извлеченных текстовых фрагментов метод позволяет более последовательно и контекстно генерировать ответы, даже в задачах вопросно-ответной системы с большим контекстом. Исследователи из NVIDIA показали, что этот инновационный подход превосходит существующие методы по качеству и эффективности, что делает его многообещающим решением для будущих разработок в области обработки естественного языка.
«`



















