

Решение задач в робототехнике
Решение последовательных задач, требующих выполнения нескольких шагов, представляет существенные вызовы в робототехнике, особенно в реальных приложениях, где роботы действуют в неопределенных средах. Эти среды часто являются стохастическими, что означает, что роботы сталкиваются с изменчивостью в действиях и наблюдениях. Одной из основных целей в робототехнике является повышение эффективности робототехнических систем, позволяя им выполнять долгосрочные задачи, требующие продолжительного размышления в течение длительного времени. Принятие решений дополнительно осложняется ограниченными датчиками роботов и частичной наблюдаемостью окружающей среды, что ограничивает их способность полностью понимать окружающую среду. В результате исследователи постоянно ищут новые методы для улучшения способности роботов воспринимать, учиться и действовать, делая их более автономными и надежными.
Проблема и решение
Основная проблема исследователей в этой области заключается в неспособности робота эффективно учиться на основе прошлых действий. Роботы полагаются на методы, такие как обучение с подкреплением (RL), чтобы улучшить производительность. Однако RL требует множества попыток, часто в миллионах, чтобы робот стал искусным в выполнении задач. Это непрактично, особенно в частично наблюдаемых средах, где роботы не могут взаимодействовать непрерывно из-за связанных с этим рисков. Более того, существующие системы, такие как модели принятия решений, основанные на больших языковых моделях (LLM), испытывают трудности с сохранением прошлых взаимодействий, заставляя роботов повторять ошибки или переучиваться стратегиям, с которыми они уже сталкивались. Эта неспособность применять предыдущие знания препятствует их эффективности в сложных долгосрочных задачах.
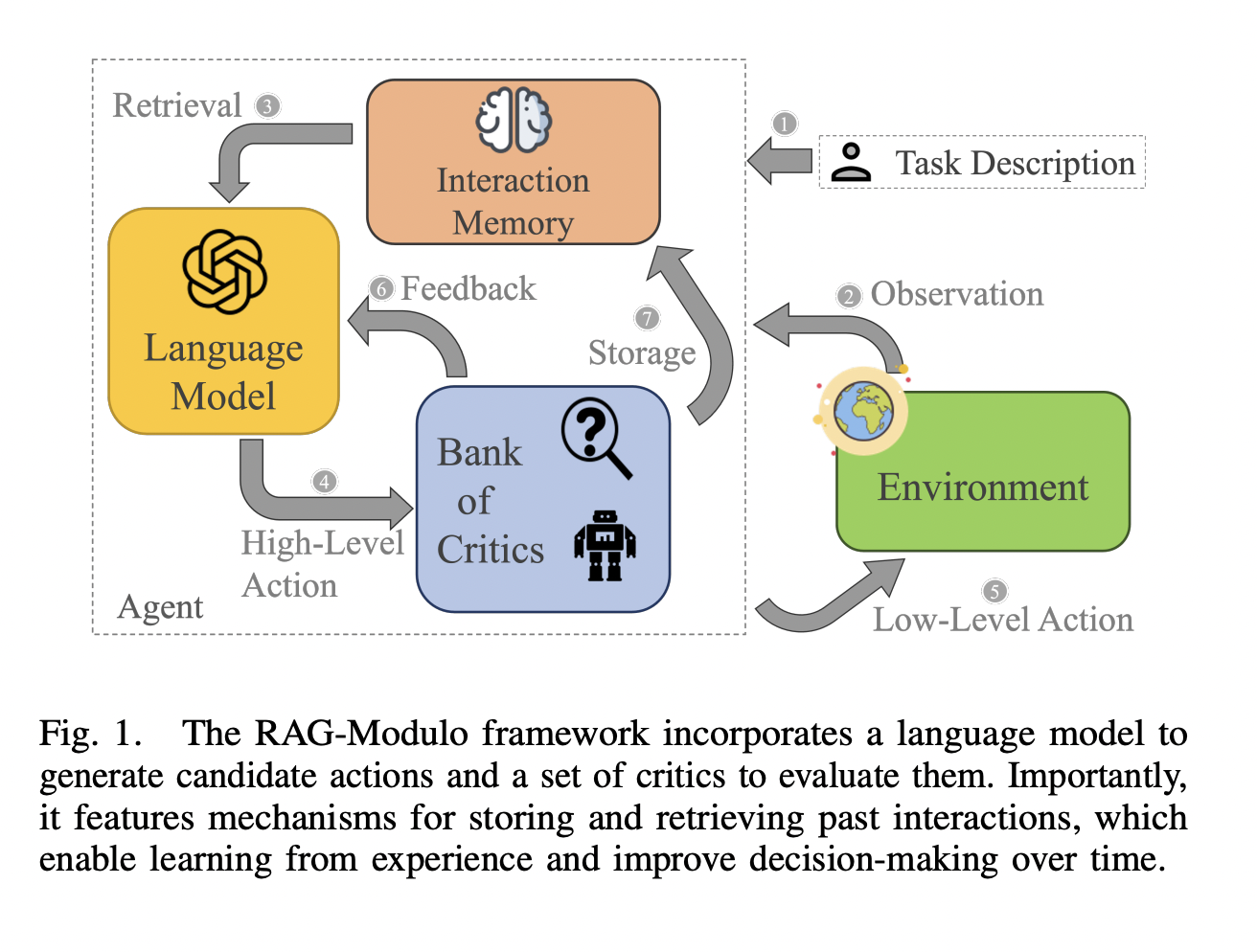
Исследователи из Университета Райса представили фреймворк RAG-Modulo. Эта новая система улучшает агентов на основе LLM, оснащая их памятью взаимодействия. Эта память сохраняет прошлые решения, позволяя роботам вспоминать и применять соответствующий опыт при столкновении с подобными задачами в будущем. Таким образом, система улучшает способности принятия решений со временем. Критики, встроенные в систему, действуют как проверяющие, предоставляя обратную связь на основе синтаксиса, семантики и политики низкого уровня. Эти критики гарантируют, что действия робота являются выполнимыми и контекстуально соответствующими. Важно отметить, что такой подход устраняет необходимость в обширной ручной настройке, поскольку память автоматически адаптируется и настраивает подсказки для LLM на основе прошлого опыта.

















