

«`html
Yandex представляет TabReD: новый стандарт для табличного машинного обучения
В последние годы исследования в области табличного машинного обучения растут стремительно. Однако для исследователей и практиков это по-прежнему представляет значительные вызовы. Традиционные академические стандарты для табличного машинного обучения не полностью отражают сложности, с которыми сталкиваются в реальных промышленных приложениях.
Практические решения и ценность
Для решения этих проблем исследователи из Yandex и HSE University представили TabReD — новый стандарт, разработанный для отражения промышленных приложений табличных данных. TabReD включает в себя восемь наборов данных из реальных приложений, охватывающих такие области, как финансы, доставка еды и недвижимость. Код и наборы данных были опубликованы на GitHub.
Конструирование стандарта TabReD
Для создания TabReD исследователи использовали наборы данных из соревнований Kaggle и приложений машинного обучения Yandex. Они следовали четырем правилам: данные должны быть табличными, процесс создания признаков должен соответствовать практикам промышленности, исключались наборы данных с утечкой информации, а также убедились, что у наборов данных есть временные метки и достаточное количество образцов для временного разделения.
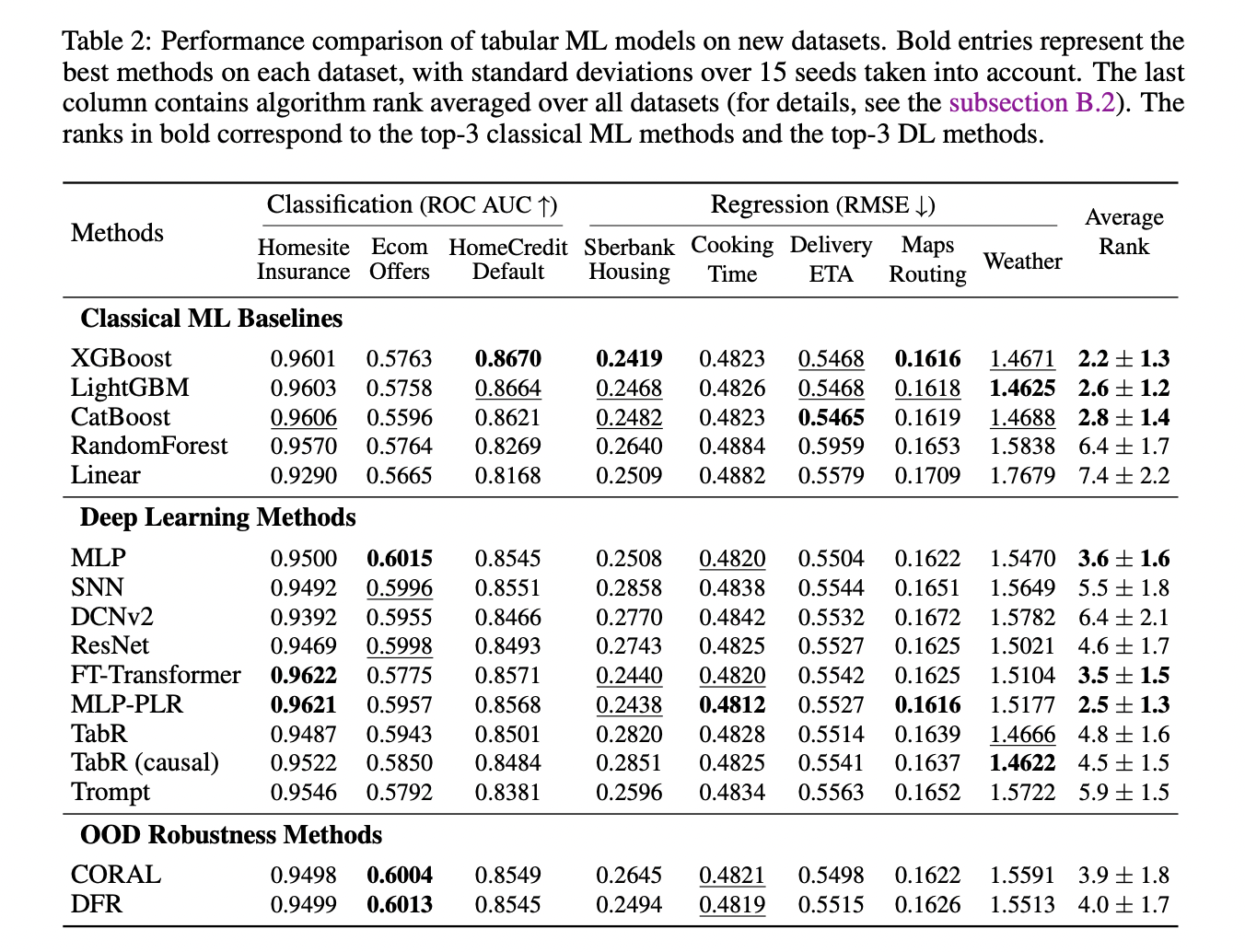
Экспериментальные результаты и будущие исследования
Исследователи тестировали недавние методы глубокого обучения на стандарте TabReD, чтобы оценить их производительность с разделением данных по времени и дополнительными признаками. Они пришли к выводу, что разделение данных по времени играет решающую роль для правильной оценки. Результаты выявили, что MLP с встраиваниями для непрерывных признаков является простым, но эффективным базовым методом глубокого обучения, в то время как более сложные модели показывали менее впечатляющую производительность в этом контексте.
Стандарт TabReD сокращает разрыв между академическими исследованиями и промышленным применением в табличном машинном обучении. Он позволяет исследователям разрабатывать и оценивать модели, которые более вероятно будут успешно работать в производственных средах, предоставляя стандарт, который тесно соответствует реальным сценариям. Это критически важно для ускоренного внедрения новых исследовательских результатов в практические приложения.
Стандарт TabReD заложил основу для исследования дополнительных направлений, таких как непрерывное обучение, управление постепенными временными изменениями и улучшение методов выбора и создания признаков. Он также подчеркивает необходимость разработки надежных протоколов оценки для более точной оценки реальной производительности моделей машинного обучения в динамичных реальных средах.
Подробнее о статье и наборах данных можно узнать на GitHub. Вся заслуга за это исследование принадлежит ученым этого проекта. Также не забудьте следить за нами в Twitter и присоединиться к нашей группе в LinkedIn.
«`

















