

«`html
Новый языковой модель Sarvam-2B: инновационные возможности для обработки текста на индийских языках
Sarvam AI недавно представила свою передовую языковую модель Sarvam-2B. Эта мощная модель с 2 миллиардами параметров является значительным прорывом в обработке индийских языков. С акцентом на инклюзивность и культурное представительство Sarvam-2B предварительно обучена с нуля на массивном наборе данных из 4 триллионов высококачественных токенов, из которых внушительные 50% посвящены индийским языкам. Это развитие, особенно их способность понимать и генерировать текст на языках, исторически недостаточно представленных в исследованиях ИИ.
Набор данных Samvaad-Hi-v1: ценный ресурс для развития мультиязычных и культурно значимых моделей ИИ
Компания также представила набор данных Samvaad-Hi-v1, тщательно подобранную коллекцию из 100 000 высококачественных разговоров на английском, хинди и хинглиш. Этот набор данных уникально разработан с учетом индийского контекста, что делает его бесценным ресурсом для исследователей и разработчиков, работающих над мультиязычными и культурно значимыми моделями ИИ. Samvaad-Hi-v1 призван улучшить обучение систем разговорного ИИ, способных естественно и контекстуально взаимодействовать с пользователями на различных языках и диалектах, распространенных в Индии.
Цель Sarvam-2B
Визия Sarvam AI с Sarvam-2B ясна: создать мощную и универсальную языковую модель, которая отлично работает на английском и поддерживает индийские языки. Это особенно важно в стране, где языковое разнообразие огромно, и необходимость в ИИ-моделях, способных эффективно обрабатывать и генерировать текст на нескольких языках, велика.
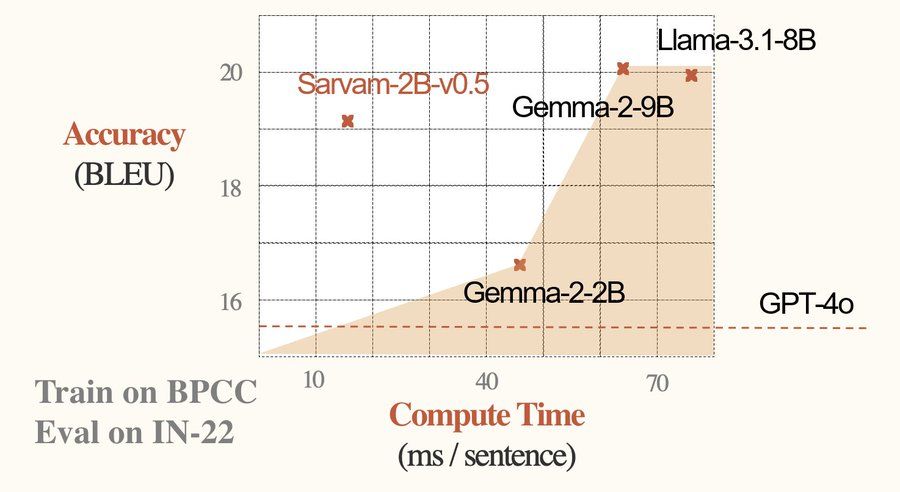
Техническое совершенство и внедрение
Sarvam-2B обучена на сбалансированной смеси данных на английском и индийских языках, каждый внес по 2 триллиона токенов в процесс обучения. Этот тщательный баланс обеспечивает, что модель одинаково виртуозно работает на английском и поддерживаемых индийских языках. Процесс обучения включал изощренные техники для улучшения способностей модели в понимании и генерации текста, что делает ее одной из самых передовых моделей в своей категории.
Расширение горизонта: дополнительные модели
Помимо Sarvam-2B, Sarvam AI также представила три другие замечательные модели, дополняющие ее возможности:
Bulbul 1.0: Модель текст в речь (TTS), поддерживающая комбинации 10 языков и шесть голосов. Эта модель генерирует естественно звучащую речь, что делает ее ценным инструментом для приложений, требующих многоязычного звукового вывода.
Saaras 1.0: Модель речи в текст (STT), поддерживающая те же десять языков и включающая автоматическую идентификацию языка. Эта модель особенно полезна для транскрибирования устной речи в текст, с дополнительным преимуществом автоматического определения языка.
Mayura 1.0: API для перевода, разработанный для работы с сложностями перевода между индийскими языками и английским. Эта модель адаптирована для учета тонкостей и уникальных вызовов, связанных с индийскими языками, обеспечивая более точные и культурно значимые переводы.
Заключение
Sarvam AI запустила Sarvam-2B, особенно в контексте языковых моделей, разработанных для индийских языков. Посвятив половину своих обучающих данных этим языкам, Sarvam-2B выделяется как модель, активно пропагандирующая важность языкового разнообразия. Универсальность модели, в сочетании с дополнительными возможностями Bulbul 1.0, Saaras 1.0 и Mayura 1.0, позиционирует Sarvam AI как лидера в разработке инклюзивных, инновационных и перспективных технологий ИИ.
Проверьте Model Card и Dataset. Вся заслуга за этот проект принадлежит исследователям. Также не забудьте подписаться на наш Twitter и присоединиться к нашей группе в LinkedIn. Если вам нравится наша работа, вам понравится наш newsletter.
«`

















