

«`html
Аудио-Языковая Модель Qwen2-Audio: Революционные Решения для Сложных Задач Аудио
Аудио, как средство передачи информации, имеет огромный потенциал для передачи сложной информации, что делает его необходимым для разработки систем, способных точно интерпретировать и реагировать на аудиовходы. Это поле направлено на создание моделей, способных понимать широкий спектр звуков, от устной речи до окружающего шума, и использовать это понимание для облегчения более естественного взаимодействия между людьми и машинами.
Основные Вызовы и Решения
Одним из ключевых вызовов в этой области является разработка систем, способных обрабатывать разнообразные аудиосигналы в реальных сценариях. Традиционные модели часто не справляются с распознаванием и реагированием на сложные аудиовходы, такие как перекрывающиеся звуки, многоголосные среды и смешанные аудиоформаты. Исследователи разрабатывают новые методологии, способные лучше подготовить модели к непредсказуемости и сложности реальных аудиоданных, тем самым улучшая их способность следовать инструкциям и точно реагировать в различных контекстах.
Qwen2-Audio: Практические Решения и Преимущества
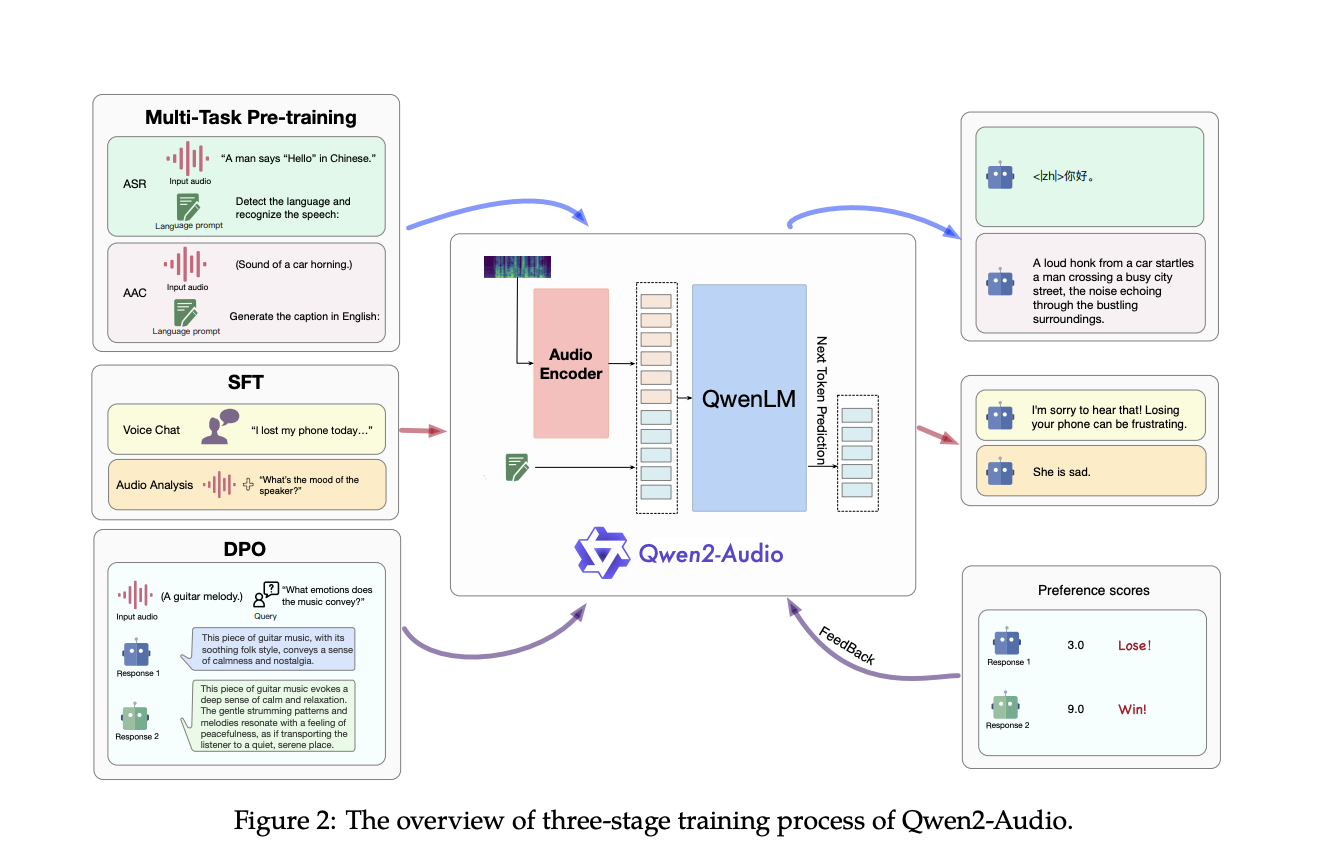
Команда Qwen представила Qwen2-Audio, продвинутую аудио-языковую модель, предназначенную для обработки и реагирования на сложные аудиосигналы без необходимости специальной настройки под конкретные задачи. Модель отличается упрощением процесса предварительного обучения с использованием естественных языковых подсказок вместо иерархических тегов, значительным расширением объема данных модели и улучшением ее способности следовать инструкциям. Архитектура Qwen2-Audio интегрирует сложный аудиоэнкодер, инициализированный на основе модели Whisper-large-v3, с крупной языковой моделью Qwen-7B в качестве основного компонента. Модель может обрабатывать различные аудиовходы, от простой речи до сложных мультимодальных аудиосред.
Практические Результаты и Перспективы
Оценки производительности показывают, что Qwen2-Audio превосходит предыдущие модели в таких задачах, как автоматическое распознавание речи, перевод речи в текст и распознавание эмоций в речи. Модель показала высокую точность в различных аудиозадачах, подтверждая свою надежность и мощность.
Qwen2-Audio, упрощая процесс предварительного обучения, расширяя объем данных и интегрируя передовую архитектуру, устанавливает новые стандарты для систем взаимодействия с аудиосигналами.
Подробнее о работе модели, карте модели и демо можно узнать на официальном сайте. Вся благодарность за это исследование идет исследователям этого проекта.
Не забудьте присоединиться к нашим социальным сетям, чтобы следить за новостями и обновлениями.
Также, не забудьте посетить наш подраздел AI Webinars и узнать о предстоящих мероприятиях и событиях в области искусственного интеллекта.
Arcee AI представил DistillKit: открытый инструмент для моделирования, упрощающий процесс дистилляции моделей для создания эффективных и высокопроизводительных малых языковых моделей.
Мы поможем вам использовать искусственный интеллект для развития вашего бизнеса. Свяжитесь с нами для получения дополнительной информации и консультаций.