

«`html
OpenAI представляет OpenAI Strawberry o1: Прорыв в ИИ-рассуждениях с точностью 93% в математических задачах и входит в топ-1% программных соревнований
Внедрение OpenAI Strawberry o1
OpenAI представила OpenAI Strawberry o1 с явным акцентом на способностях рассуждения, выходящих за рамки предыдущих моделей, таких как GPT-4o. Модель разработана для обдумывания проблем, производя длинную цепочку внутренних рассуждений, имитирующих человеческие методы решения проблем. Эта новая модель использует обучение с подкреплением, где она учится на обратной связи, улучшая свою внутреннюю логику и подход к решению проблем с течением времени. OpenAI o1 занимает место среди лучших исполнителей на различных конкурсах и бенчмарках, включая программные контесты, такие как Codeforces, и математические соревнования, такие как Mатематическая Олимпиада США.
Технические преимущества обучения с подкреплением
Одной из наиболее впечатляющих особенностей OpenAI o1 является использование обучения с подкреплением для построения «цепочки рассуждений». В отличие от традиционных LLM, генерирующих мгновенные ответы, OpenAI o1 обучена рассуждать через проблему поэтапно. Эта способность критически важна для решения сложных задач, особенно тех, которые требуют долгосрочного рассуждения, таких как продвинутая математика или задачи по программированию.
Производительность бенчмарков OpenAI o1
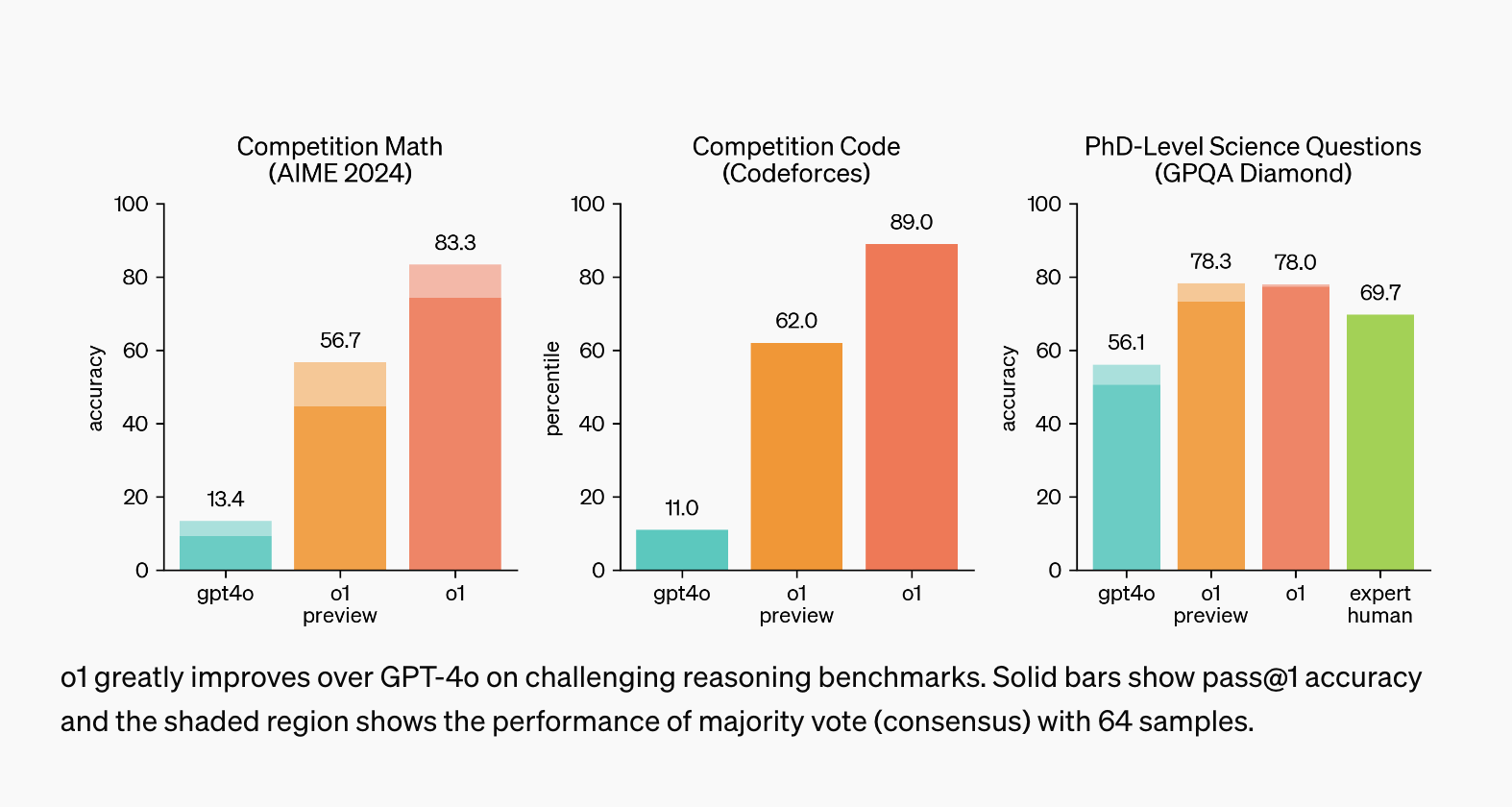
Для демонстрации преимуществ OpenAI o1, OpenAI протестировала модель на различных бенчмарках, включая конкурсные программные экзамены, математические тесты и научные задачи. Результаты были впечатляющими. Например, в квалификационном туре Математической Олимпиады США (AIME) OpenAI o1 выступила на уровне, сравнимом с топ-500 математических студентов в США. В отличие от этого GPT-4o решил только 12% проблем. В свою очередь, OpenAI o1 показала средний уровень успеха в 74%, с впечатляющей точностью в 93%, когда используется консенсус среди нескольких образцов.
Цепочка рассуждений: новая парадигма для ИИ-рассуждений
Одной из особенностей OpenAI o1 является его цепочка рассуждений, процесс, при котором модель занимается внутренним рассуждением перед тем, как дать ответ. Этот подход отражает способ, которым люди решают проблемы, особенно в математике и программировании. Модель способна анализировать и исправлять свои ошибки, пробовать различные стратегии и в конечном итоге улучшать свои решения. Эта способность значительно улучшает точность модели в задачах, связанных с рассуждениями.
Предпочтения человека и вопросы безопасности
Помимо технических возможностей, OpenAI o1 также была оценена на основе человеческих предпочтений. OpenAI сравнила ответы OpenAI o1-preview и GPT-4o на различные предложения в различных областях. Человеческие оценщики преимущественно отдавали предпочтение ответам OpenAI o1-preview в областях, требующих рассуждения, таких как анализ данных, программирование и математика.
Будущие последствия и применения
Выпуск OpenAI o1 является серьезным шагом в развитии ИИ, способного к сложным рассуждениям. Его способность превосходить людей в специализированных задачах, в сочетании с его рамкой обучения с подкреплением, делает его хорошо подходящим для применения в науке, инженерии и других областях, требующих критического мышления.
В заключение, OpenAI o1 устанавливает новый стандарт для больших языковых моделей, демонстрируя беспрецедентные способности к рассуждениям в различных областях. Его использование обучения с подкреплением для построения цепочки рассуждений представляет собой значительное новшество в исследованиях ИИ, которое обещает открывать новые возможности для применения ИИ в повседневных задачах и специализированных областях.
«`















