

«`html
NuMind представляет NuExtract: легковесную текст-в-JSON модель языка, специальизированную на задачу структурированного извлечения
NuExtract представляет собой передовую текст-в-JSON модель языка, которая представляет собой значительное достижение в извлечении структурированных данных из текста. Она разработана с целью эффективно преобразовывать неструктурированный текст в структурированные данные. Инновационный дизайн и методологии обучения, используемые в NuExtract, позиционируют его как превосходную альтернативу существующим моделям, обеспечивая высокую производительность и экономичность.
Практические преимущества и решения
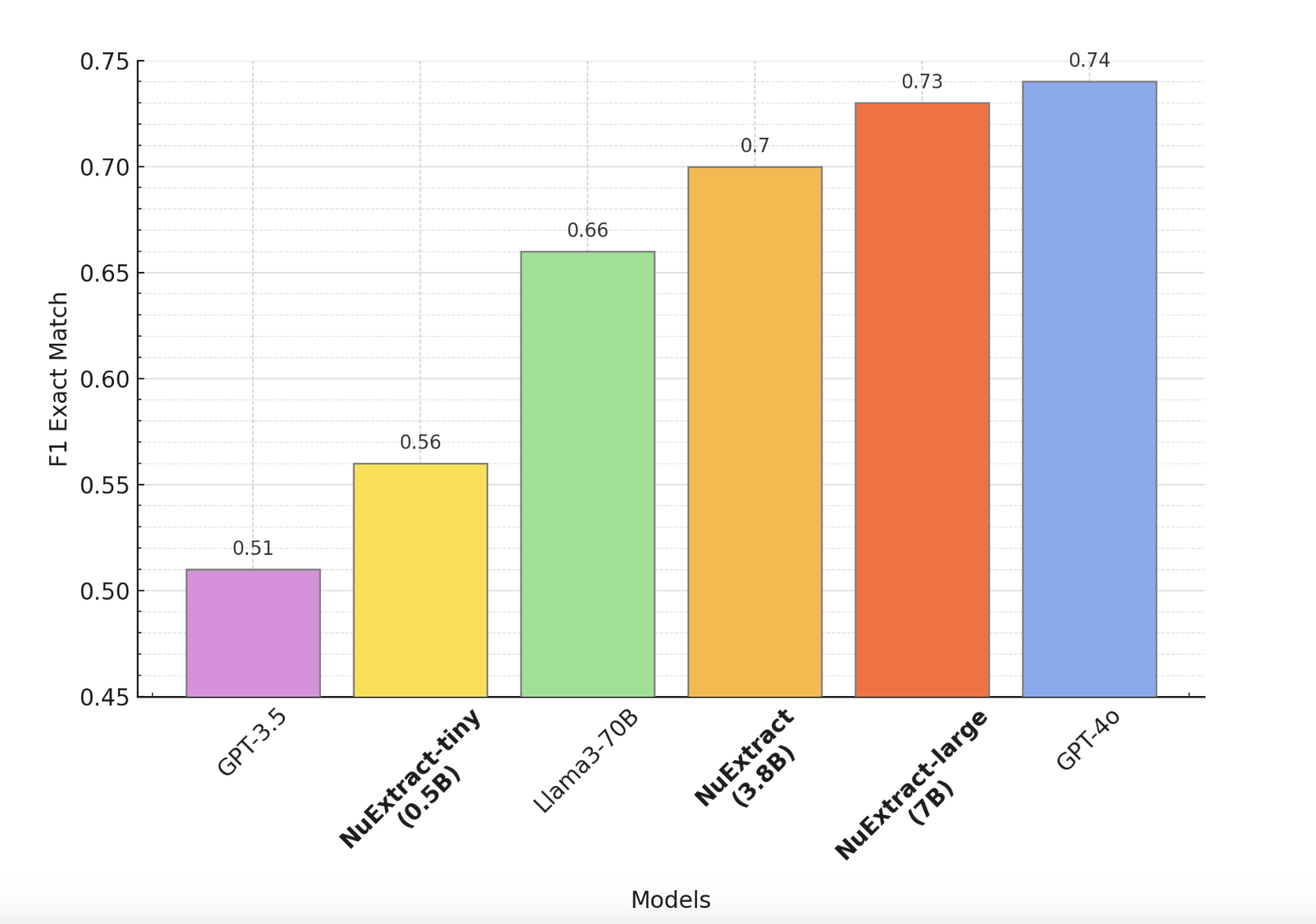
NuExtract разработан для эффективной работы с моделями от 0,5 миллиарда до 7 миллиардов параметров, достигая аналогичных или более высоких возможностей извлечения по сравнению с более крупными популярными языковыми моделями (LLM). Эффективность достигается путем создания трех отдельных моделей в семье NuExtract: NuExtract-tiny, NuExtract и NuExtract-large. Эти модели продемонстрировали выдающуюся производительность в различных задачах извлечения, часто превосходя гораздо более крупные LLM.
Доступны три обученных версии NuExtract:
- NuExtract-tiny (0,5 млрд): легковесная модель идеально подходит для приложений, требующих эффективной производительности с минимальными вычислительными ресурсами. Несмотря на свой небольшой размер, NuExtract-tiny работает лучше некоторых более крупных моделей, что делает его подходящим для задач, где ограничения ресурсов имеют приоритет.
- NuExtract (3,8 млрд): данная модель находит баланс между размером и производительностью, что делает ее хорошо подходящей для более требовательных задач извлечения. Она использует умеренное количество параметров для достижения высокой точности и универсальности, обрабатывая широкий спектр структурированных задач извлечения эффективно.
- NuExtract-large (7 млрд): самая мощная версия, разработанная для самых сложных и интенсивных задач извлечения. С 7 миллиардами параметров NuExtract-large достигает уровня производительности, сравнимого с топовыми LLM, такими как GPT-4, при этом она является значительно более компактной и экономичной. Эта модель идеально подходит для приложений, требующих высочайшей точности и детализации при извлечении данных.
Основной вызов, которому NuExtract удовлетворяет, заключается в структурированном извлечении, которое включает в себя извлечение различных типов информации, таких как сущности, количества, даты и иерархические отношения из документов. Извлеченная информация структурируется в формат JSON, что облегчает парсинг и интеграцию в базы данных или использование для автоматизированных действий. Например, извлечение данных из документа и их организация в иерархическую древовидную структуру в формате JSON — это задача, которую NuExtract обрабатывает с высокой точностью и эффективностью.
Задачи структурированного извлечения значительно различаются по сложности. Традиционные методы, такие как регулярные выражения или не-генеративные модели машинного обучения, могли бы справиться с простым извлечением сущностей, но должны улучшаться при работе с более сложными задачами, требующими более глубокого иерархического извлечения. Современные генеративные LLM, включая GPT-4, расширили возможности в этой области, позволяя генерировать глубокие деревья извлечения. Однако NuExtract показал, что может достичь аналогичных результатов с гораздо более компактными моделями, что делает его более практичным решением для многих приложений.
Одно из ключевых преимуществ NuExtract заключается в его способности обрабатывать сценарии извлечения «нулевой обучающей выборки» и «файнтюнинга». Модель может извлекать информацию только на основе заранее заданного шаблона или схемы в режиме «нулевой обучающей выборки», не требуя специфических данных обучения по конкретной задаче. Эта возможность особенно ценна для приложений, где создание больших размеченных наборов данных нереально. Кроме того, NuExtract может быть файнтюнингован для конкретных приложений, дополнительно улучшая его производительность для специализированных задач.
Для обучения NuExtract разработчики использовали новый подход: они использовали большой и разнообразный корпус текста из набора данных C4, который был аннотирован с использованием современной LLM с тщательно разработанными подсказками. Эти синтетические данные были затем использованы для файнтюнинга компактной универсальной модели, что привело к получению высокоспециализированной модели для выполнения конкретных задач. Эта методология обучения обеспечивает способность NuExtract хорошо обобщаться в различных областях, делая его универсальным для различных задач структурированного извлечения.
Модель систематически производит действительные JSON выходы, соблюдает схему и точно извлекает соответствующую информацию. Например, в тестах по разбору химических реакций NuExtract успешно выявлял, классифицировал и извлекал количество химических веществ и условия реакции, такие как продолжительность и температура. Это высокая точность демонстрирует потенциал NuExtract в решении сложных задач извлечения в области химии, медицины, права и финансов.
Компактный размер NuExtract предлагает несколько практических преимуществ. Менее мощные модели стоят дешевле в эксплуатации, что обеспечивает экономичную реализацию. Кроме того, они позволяют локальное развертывание, что является важным для приложений, требующих соблюдение конфиденциальности данных. Простота настройки этих моделей делает их приспосабливаемыми к конкретным случаям использования, дополнительно улучшая их утилитарность.
В заключение, NuExtract от NuMind представляет собой значительный шаг вперед в структурированном извлечении данных из текста. Его инновационный дизайн, эффективная методология обучения и впечатляющая производительность в различных задачах делают его ценным инструментом для преобразования неструктурированного текста в структурированные данные. Возможность модели хорошо проявлять себя как в режиме нулевой обучающей выборки, так и при файнтюнинге, в связи со стоимостью и простотой развертывания, позиционирует его как ведущее решение для современных вызовов структурированного извлечения данных.
NuMind Releases NuExtract: A Lightweight Text-to-JSON LLM Specialized for the Task of Structured Extraction
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте NuMind Releases NuExtract: A Lightweight Text-to-JSON LLM Specialized for the Task of Structured Extraction.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai.
Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`


















