

«`html
Введение в TxT360: Новая эра для ИИ
TxT360 — это передовой набор данных для предварительного обучения, состоящий из 15 триллионов токенов. Этот набор данных сочетает в себе разнообразие, масштаб и строгую фильтрацию данных, что делает его одним из самых сложных открытых наборов данных на сегодняшний день.
Набор данных на новых основах
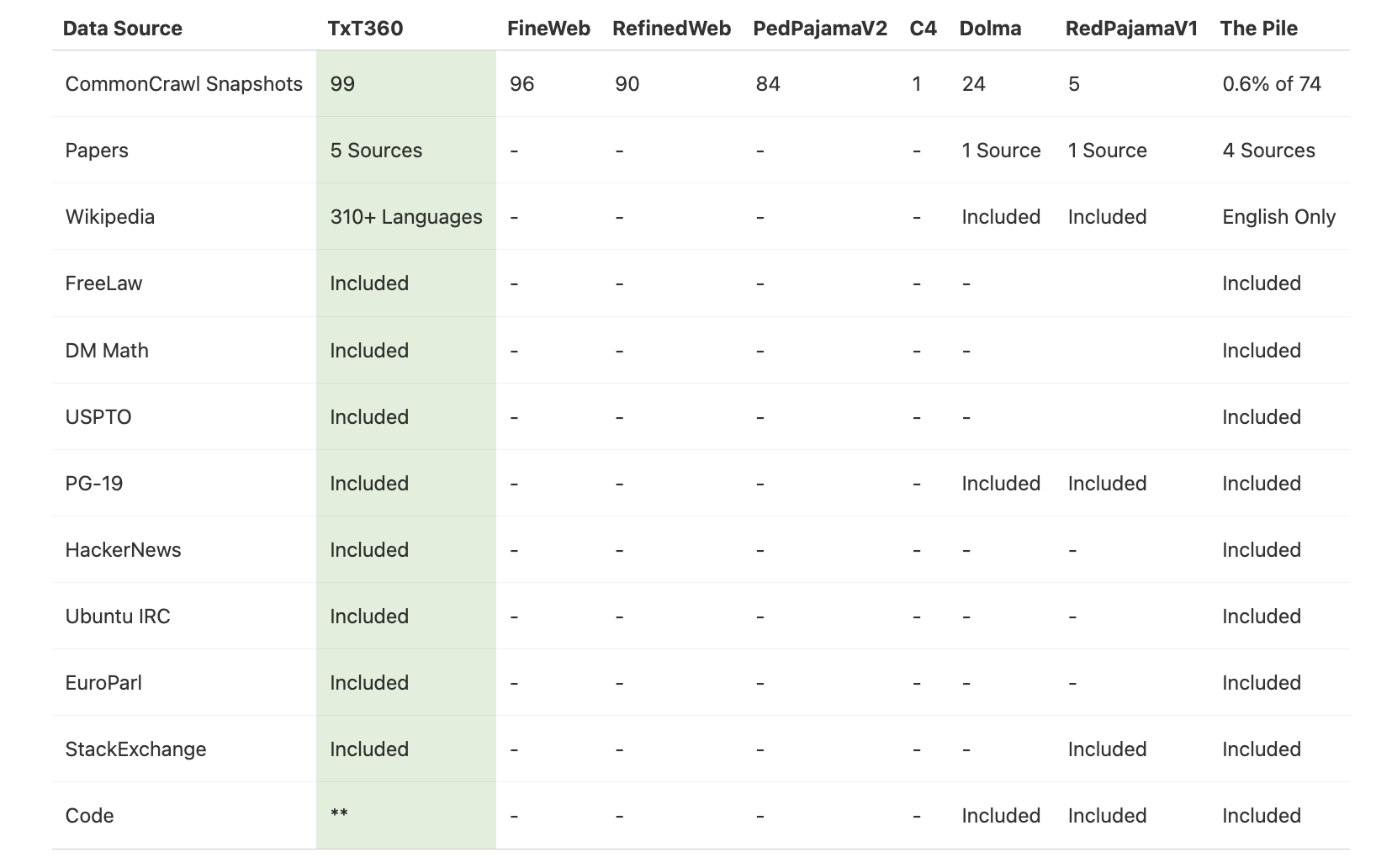
TxT360 выделяется среди предыдущих наборов данных благодаря новым источникам, таким как FreeLaw (правовые корпуса), PG-19 (коллекция книг), научные статьи и Wikipedia. Смешение этих источников создает более богатый и нюансированный набор данных, который укрепляет возможности следующего поколения LLM.
От общего к чистым данным
Создание TxT360 началось с Common Crawl, общедоступного веб-скрейпа. Однако просто использование необработанных веб-данных не соответствовало высоким стандартам, которые ставила перед собой команда LLM360. Они провели строгую фильтрацию для извлечения наиболее полезного текста из огромного объема данных.
- Извлечение текста: Чистый и связный текст был выделен из шумных веб-данных.
- Фильтрация по языку: Удален неанглоязычный контент для поддержания последовательности набора данных.
- Фильтрация URL: Исключены избыточные или низкоценные источники.
- Удаление повторений: Устранены повторяющиеся строки и абзацы.
- Фильтрация на уровне документов и строк: Удалены документы и строки, не соответствующие стандартам качества.
В итоге было отфильтровано 97.65% исходных данных, сохранив только качественный и значимый текст.
Глобальная дедупликация
Для создания качественного набора данных, такого как TxT360, была необходима эффективная дедупликация. Команда LLM360 использовала два подхода: точную дедупликацию с помощью Bloom-фильтра и нечеткую дедупликацию с использованием MinHash алгоритма. Эти методы обеспечили уникальность контента в наборе данных.
Качественные источники
После процесса фильтрации LLM360 добавила отобранные высококачественные корпуса, включая научные статьи, юридические документы и классические книги. Каждый из этих специализированных источников прошел индивидуальные процессы для сохранения целостности и качества данных.
TxT360: Новый стандарт для открытого ИИ
Выпуск TxT360 — это значительный шаг вперед в области ИИ и исследований NLP. Строгость и тщательность создания LLM360 показывают, что качество и количество могут сосуществовать. С 15 триллионами токенов TxT360 поддерживает разработку сложных и интеллектуальных языковых моделей.
Кроме того, прозрачность команды LLM360 в их процессах устанавливает новый стандарт в области. В ближайшее время они выпустят код, который даст представление о методах, лежащих в основе этого набора данных.
Как внедрить ИИ в вашу компанию
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, следуйте этим рекомендациям:
- Проанализируйте, как ИИ может изменить вашу работу.
- Определите, где возможно применение автоматизации.
- Определитесь с ключевыми показателями эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Подберите подходящее решение, начните с малого проекта, анализируйте результаты и KPI.
- На основе полученных данных и опыта расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам в Телеграм. Узнайте, как ИИ может изменить процесс продаж в вашей компании с решением от saile.ru — будущее уже здесь!
«`


















