

«`html
Внедрение Docmatix: датасет для визуального ответа на вопросы по документам
Документальный визуальный ответ на вопросы (DocVQA) – это раздел визуального ответа на вопросы, ориентированный на ответы на запросы о содержании документов. Эти документы могут иметь несколько форм, включая отсканированные фотографии, PDF-файлы и цифровые документы с текстовыми и визуальными элементами. Возникает нехватка наборов данных для DocVQA из-за сложности сбора и аннотирования данных. Тем не менее, срочная необходимость в большем количестве наборов данных для DocVQA подчеркивает важность этих наборов для улучшения производительности моделей, а также создания более доступных документов через автоматизацию процессов и создание кратких резюме.
Актуальные решения и практические преимущества
Для улучшения моделей требуется автоматизация процессов относительно документов в различных сферах и сделать документы более доступными через генерацию резюме и ответы на запросы. Обновленные модели DocVQA могут значительно повлиять на доступность документов.
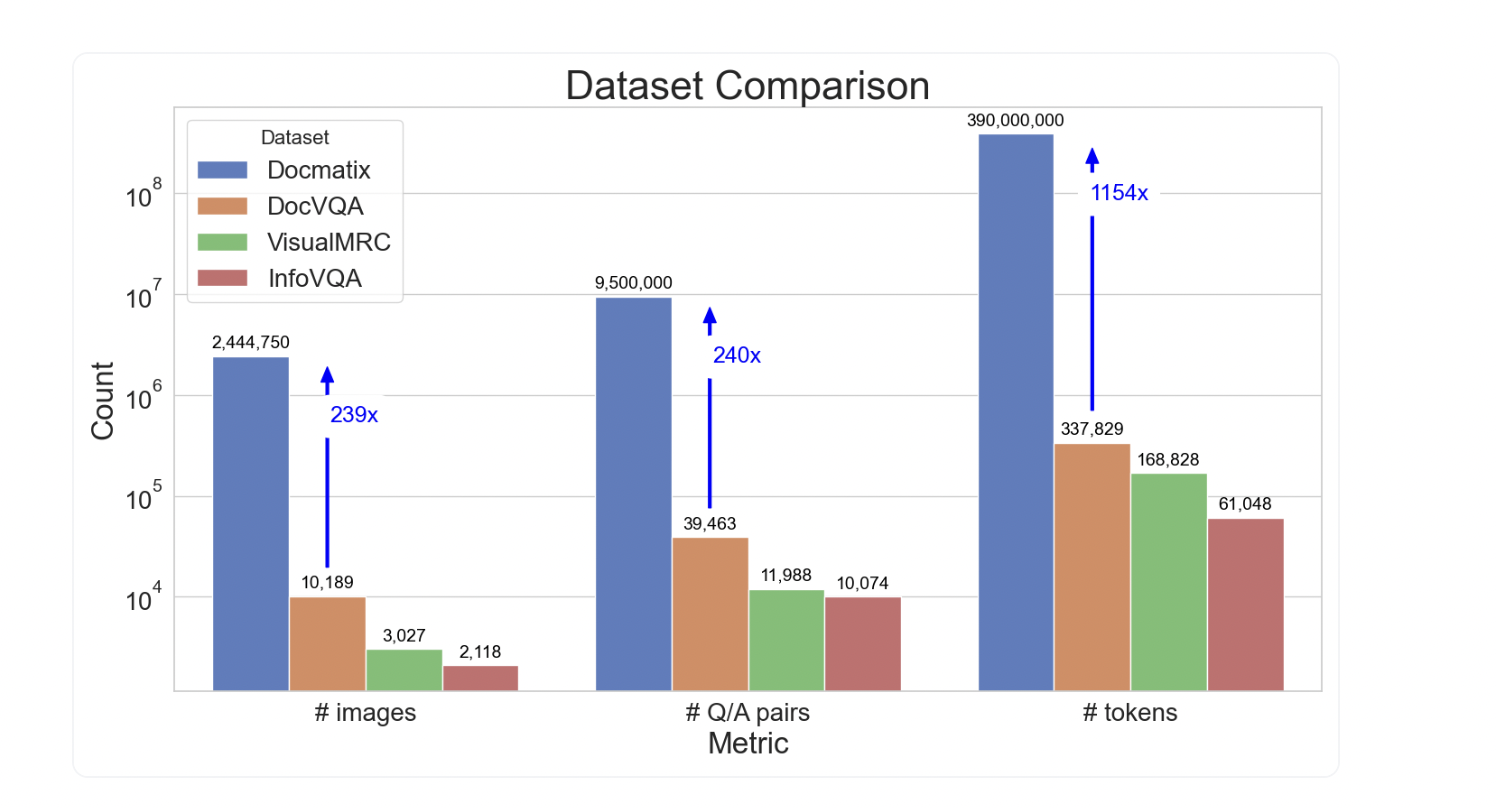
Исследователи из HuggingFace создали масштабную коллекцию из пятидесяти наборов данных под названием The Cauldron для настройки моделей Vision-Language Models (VLMs), с акцентом на Idefics2. В результате этих усилий команда обнаружила серьезный дефицит высококачественных наборов данных для DocVQA. Docmatix – новый набор данных DocVQA, содержащий 2,4 миллиона изображений и 9,5 миллиона пар вопрос-ответ, извлеченных из 1,3 миллиона PDF-документов. Это увеличение в 240 раз по сравнению с предыдущими наборами подчеркивает потенциальное влияние Docmatix.
Для обеспечения качества данных было удалено 15% пар вопрос-ответ, выявленных как галлюцинации при создании фильтра. После обработки PDF-файлов команда загрузила их на Hugging Face Hub, обеспечивая легкий доступ для всех.
Исследователи провели эксперименты для оценки производительности Docmatix и обнаружили улучшение на 20% при обучении на небольшом подмножестве этого набора данных. Команда надеется, что их работа сократит разрыв между закрытыми и открытыми VLM.
Реализация практических решений на практике
Исследование Docmatix представляет собой прорыв в области доступности документов и визуального ответа на вопросы. Он может быть использован для улучшения производительности моделей и обеспечения более точных ответов на запросы, что имеет потенциальную ценность для различных отраслей.
Для консультаций по внедрению искусственного интеллекта обращайтесь к нам, следите за новостями в наших социальных сетях.
Попробуйте наш AI Sales Bot для улучшения процессов в сфере продаж и снижения нагрузки на персонал.
Подключайтесь к нашим AI-решениям и следите за новостями в области искусственного интеллекта.
«`



















