

«`html
Преимущества H-DPO в области выравнивания языковых моделей
Большие языковые модели (LLMs) обладают выдающимися возможностями, но их широкое применение сталкивается с рядом вызовов. Главная проблема заключается в том, что обучающие наборы данных могут содержать разнообразный, нечеткий и потенциально вредный контент. Это создает необходимость согласования выходных данных LLM с конкретными требованиями пользователей.
Решения для улучшения LLM
Существуют различные методы согласования, направленные на улучшение LLM с учетом человеческих предпочтений. Например, метод Обратной Политики Оптимизации (DPO) упрощает процесс, убирая необходимость в модели вознаграждения и используя вместо этого бинарную кросс-энтропию.
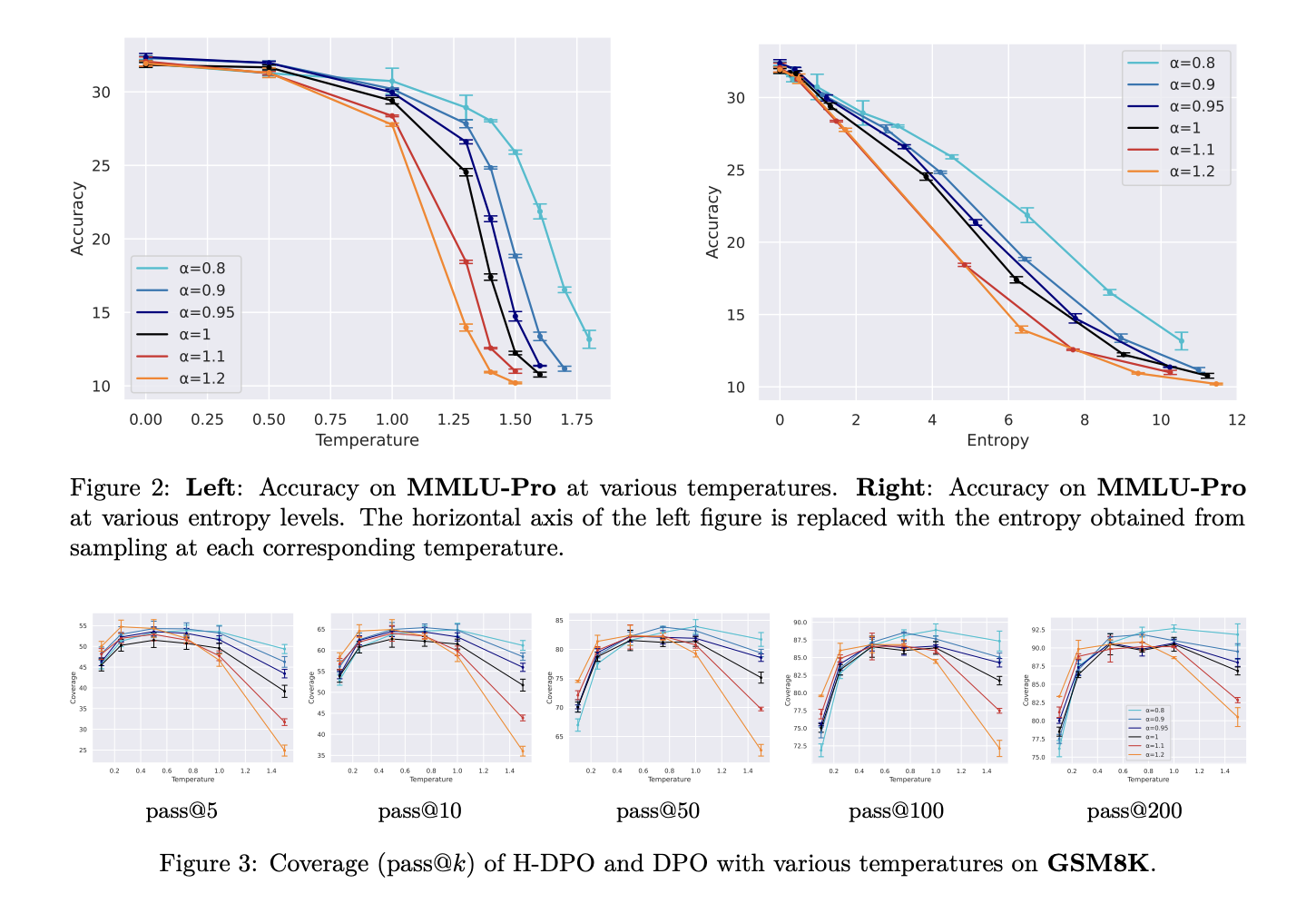
Инновации H-DPO
Исследователи из Токийского университета предложили H-DPO, который улучшает традиционный подход DPO, вводя контроль над энтропией распределения политик. Это позволяет более эффективно захватывать целевые распределения. Благодаря специальному параметру α, H-DPO помогает уменьшить энтропию, что ведет к улучшению поведения моделей.
Преимущества H-DPO
- Упрощение внедрения: минимальные изменения в текущей структуре DPO.
- Улучшение качества: значительные достижения в точности и разнообразии выходных данных моделей.
- Эффективность: надежное поведение с учетом человеческих предпочтений.
Практические рекомендации по внедрению ИИ
Если вы хотите развивать свою компанию с использованием ИИ, следуйте этим шагам:
- Проанализируйте, как ИИ может изменить вашу работу.
- Определите, где возможно применение автоматизации.
- Выберите ключевые показатели эффективности (KPI), которые хотите улучшить.
- Подберите подходящее решение, начиная с небольшого проекта.
- Анализируйте результаты и на основе данных расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам в наш Телеграм-канал.
Попробуйте AI Sales Bot — ваш помощник для успешных продаж!
«`



















