

«`html
Визионно-языковые модели: практические решения и ценность
Эволюция визионно-языковых моделей
В последние годы визионно-языковые модели претерпели значительное развитие, выделив два поколения. Первое поколение, представленное CLIP и ALIGN, расширило предварительное обучение на основе крупномасштабной классификации, используя данные веб-масштаба без необходимости обширной человеческой разметки. Модели использовали встраивания подписей, полученные от языковых кодировщиков, для расширения словаря для задач классификации и поиска. Второе поколение, аналогичное T5 в языковом моделировании, объединило задачи подписывания и вопросно-ответной системы через генеративное кодировщик-декодировщик моделирование. Модели, такие как Flamingo, BLIP-2 и PaLI, дальше масштабировали эти подходы. Недавние разработки внесли дополнительный этап «настройки инструкции» для улучшения удобства использования. Параллельно с этими достижениями проводились систематические исследования с целью выявления ключевых факторов в визионно-языковых моделях.
Представление PaliGemma
Исходя из этого прогресса, исследователи DeepMind представляют PaliGemma — открытую визионно-языковую модель, объединяющую преимущества серии визионно-языковых моделей PaLI с семейством языковых моделей Gemma. Этот инновационный подход основан на успехах предыдущих версий PaLI, которые продемонстрировали впечатляющие возможности масштабирования и улучшения производительности. PaliGemma интегрирует 400M модель визионного представления SigLIP с 2B языковой моделью Gemma, что приводит к созданию визионно-языковой модели объемом менее 3B, которая не уступает по производительности гораздо более крупным предшественникам, таким как PaLI-X, PaLM-E и PaLI-3. Компонент Gemma, производный от той же технологии, что и модели Gemini, вносит свою авторегрессионную декодирующую архитектуру для улучшения возможностей PaliGemma. Это слияние передовых техник обработки изображений и языка позиционирует PaliGemma как значительное достижение в мультимодальном ИИ.
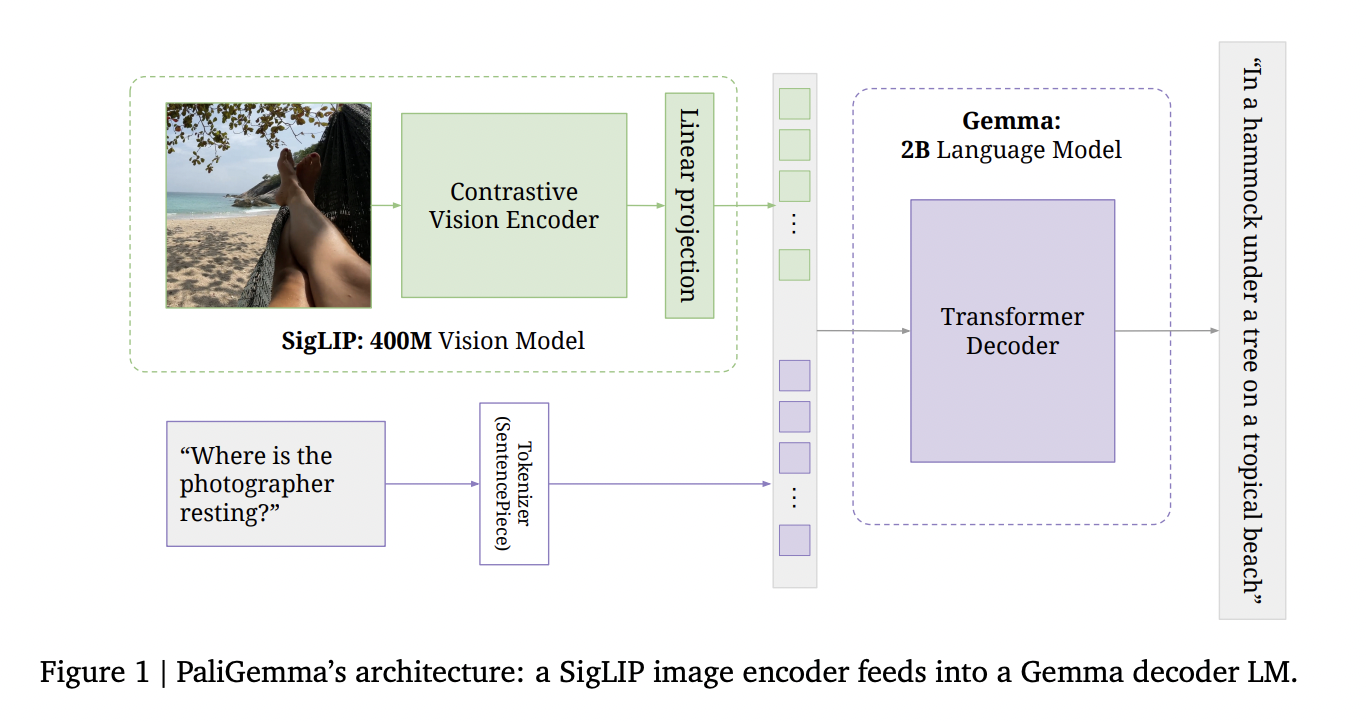
Архитектура PaliGemma
Архитектура модели PaliGemma включает три ключевых компонента: кодировщик изображений SigLIP ViTSo400m, декодирующую языковую модель Gemma-2B v1.0 и линейный проекционный слой. Кодировщик изображений преобразует входные изображения в последовательность токенов, в то время как языковая модель обрабатывает текст с использованием своего токенизатора SentencePiece. Линейный проекционный слой выравнивает размерности токенов изображения и текста, позволяя им быть объединенными. Этот простой, но эффективный дизайн позволяет PaliGemma обрабатывать различные задачи, включая классификацию изображений, подписывание и визуальные вопросно-ответные задачи через гибкий API ввода изображения+текста, вывод текста.
Процесс обучения PaliGemma
Процесс обучения модели PaliGemma включает несколько этапов для обеспечения всестороннего понимания визуально-языковой информации. Он начинается с унимодального предварительного обучения отдельных компонентов, за которым следует мультимодальное предварительное обучение на разнообразной смеси задач. Особенно важно отметить, что кодировщик изображений не замораживается на этом этапе, что позволяет улучшить пространственное и относительное понимание. Обучение продолжается с этапом увеличения разрешения, улучшающим способность модели обрабатывать изображения высокого разрешения и сложные задачи. Наконец, этап трансфера адаптирует базовую модель к конкретным задачам или сценариям использования, демонстрируя универсальность и эффективность PaliGemma в различных приложениях.
Результаты исследования
Результаты демонстрируют впечатляющую производительность PaliGemma в широком спектре визуально-языковых задач. Модель превосходит в подписывании изображений, достигая высоких показателей на бенчмарках, таких как COCO-Captions и TextCaps. В визуально-языковых вопросно-ответных задачах PaliGemma показывает высокую производительность на различных наборах данных, включая VQAv2, GQA и ScienceQA. Модель также успешно справляется с более специализированными задачами, такими как понимание диаграмм (ChartQA) и задачи, связанные с OCR (TextVQA, DocVQA). Особенно важно отметить, что PaliGemma проявляет значительные улучшения при увеличении разрешения изображения с 224px до 448px и 896px, особенно для задач, связанных с деталями или распознаванием текста. Универсальность модели также подтверждается ее способностью обрабатывать видео и задачи сегментации изображений.
Заключение
Это исследование представляет PaliGemma — надежную, компактную открытую базовую визионно-языковую модель, которая превосходит в обучении на различных задачах. Оно демонстрирует, что более маленькие визионно-языковые модели могут достичь впечатляющей производительности на широком спектре бенчмарков, оспаривая утверждение о том, что более крупные модели всегда превосходят. Предоставление базовой модели без настройки инструкции позволяет исследователям создать ценную основу для дальнейших исследований в области настройки инструкции и конкретных приложений. Этот подход способствует более ясному различию между базовыми моделями и моделями с настройкой, открывая потенциально новые возможности для более эффективных и универсальных систем ИИ в области визионно-языкового понимания.
Подробнее о исследовании можно узнать в статье. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам понравилась наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему сообществу в Reddit.
Источник: MarkTechPost
«`

















