

«`html
Усиление обучения на основе обратной связи от человека (RLHF) для улучшения качества и безопасности в языковых моделях
RLHF существенен для обеспечения качества и безопасности в языковых моделях. Современные языковые модели, такие как Gemini и GPT-4, проходят три этапа обучения: предварительное обучение на больших корпусах, SFT и RLHF для улучшения качества генерации. RLHF включает в себя обучение модели вознаграждения (RM) на основе предпочтений людей и оптимизацию языковой модели для максимизации предсказанных вознаграждений. Этот процесс сложен из-за забывания предварительно обученных знаний и взлома вознаграждения.
Практический подход для улучшения качества генерации
Практический подход для улучшения качества генерации — это Best-of-N сэмплирование, которое выбирает лучший результат из N сгенерированных кандидатов, эффективно балансируя вознаграждение и вычислительные затраты.
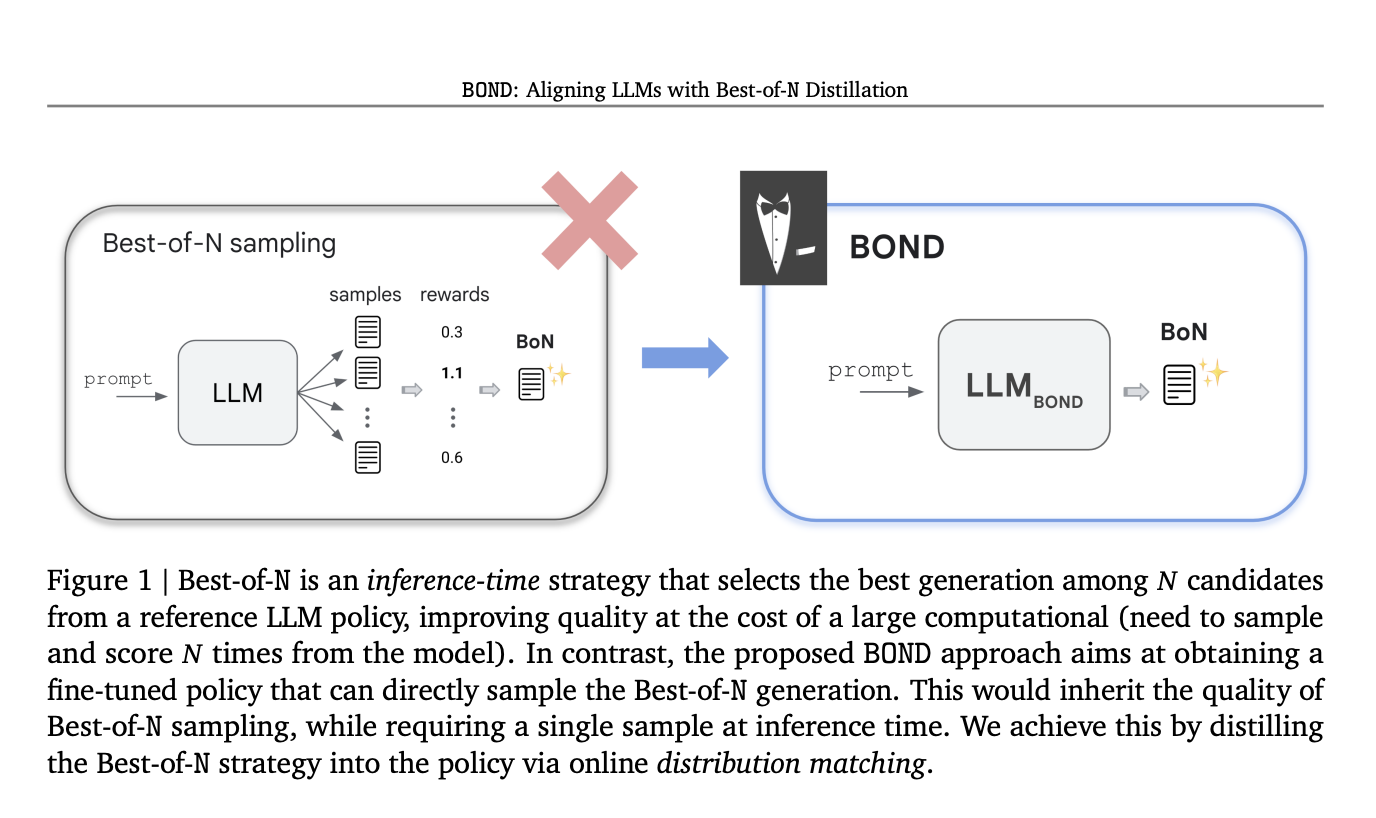
Инновационный алгоритм RLHF: Best-of-N Distillation (BOND)
Исследователи Google DeepMind представили BOND, инновационный алгоритм RLHF, разработанный для репликации производительности Best-of-N сэмплирования без высоких вычислительных затрат. BOND — алгоритм сопоставления распределений, который выравнивает выход политики с распределением Best-of-N. Используя дивергенцию Джеффриса, BOND итеративно улучшает политику через подход с движущейся якорной точкой. Эксперименты на абстрактном резюмировании и моделях Gemma показывают, что BOND, особенно его вариант J-BOND, превосходит другие алгоритмы RLHF, улучшая компромисс между вознаграждением и производительностью.
Преимущества и эффективность BOND
BOND — новый метод RLHF, который улучшает политики через онлайн дистилляцию распределения Best-of-N сэмплирования. Алгоритм J-BOND улучшает практичность и эффективность, интегрируя оценку квантилей методом Монте-Карло, объединяя цели прямой и обратной дивергенции Кульбака-Лейблера и используя итеративную процедуру с якорной точкой экспоненциального скользящего среднего. Этот подход улучшает фронт Парето между дивергенцией и вознаграждением и превосходит современные базовые уровни.
Подробнее о исследовании можно узнать в статье. Вся заслуга за это исследование принадлежит его авторам. Также не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram-каналу и группе в LinkedIn. Если вам понравилась наша работа, вам понравится и наш новостной бюллетень.
Не забудьте присоединиться к нашему сообществу из 47 000+ участников на ML SubReddit.
Узнайте о предстоящих вебинарах по ИИ здесь.
Используйте ИИ для улучшения ваших бизнес-процессов и оставайтесь в числе лидеров!
«`

















