

«`html
Преодоление Вызовов Масштабирования Трансформерных Моделей с Помощью PEER
Проблема
В архитектуре трансформеров вычислительные затраты и объем активации памяти растут линейно с увеличением ширины скрытого слоя слоев прямого распространения (FFW). Эта проблема масштабирования представляет собой значительное вызов, особенно по мере увеличения размера и сложности моделей. Преодоление этого вызова необходимо для продвижения исследований в области искусственного интеллекта, поскольку это напрямую влияет на возможность развертывания масштабных моделей в реальных приложениях, таких как языковое моделирование и задачи обработки естественного языка.
Решение
Методы, решающие этот вызов, используют архитектуры Mixture-of-Experts (MoE), которые развертывают разреженно активированные экспертные модули вместо одного плотного слоя FFW. Этот подход позволяет отделять размер модели от вычислительной стоимости. Несмотря на перспективы MoE, как продемонстрировано исследователями, такими как Шазир и др. (2017) и Лепихин и др. (2020), эти модели сталкиваются с вычислительными и оптимизационными вызовами при масштабировании за пределы небольшого количества экспертов. Эффективность часто стагнирует с увеличением размера модели из-за фиксированного количества обучающих токенов. Эти ограничения мешают полной реализации потенциала MoE, особенно в задачах, требующих обширного и непрерывного обучения.
Исследователи из Google DeepMind предлагают новый подход, называемый Parameter Efficient Expert Retrieval (PEER), который специально решает ограничения существующих моделей MoE. PEER использует технику product key для разреженного извлечения из огромного количества маленьких экспертов, их число превышает миллион. Этот подход улучшает детализацию моделей MoE, что приводит к более выгодному соотношению производительности и вычислительной стоимости. Инновация заключается в использовании изученной структуры индекса для маршрутизации, обеспечивающей эффективное и масштабируемое извлечение экспертов. Этот метод отделяет вычислительную стоимость от количества параметров, представляя собой значительное развитие по сравнению с предыдущими архитектурами. Слои PEER демонстрируют существенное улучшение эффективности и производительности для задач языкового моделирования.
Результаты
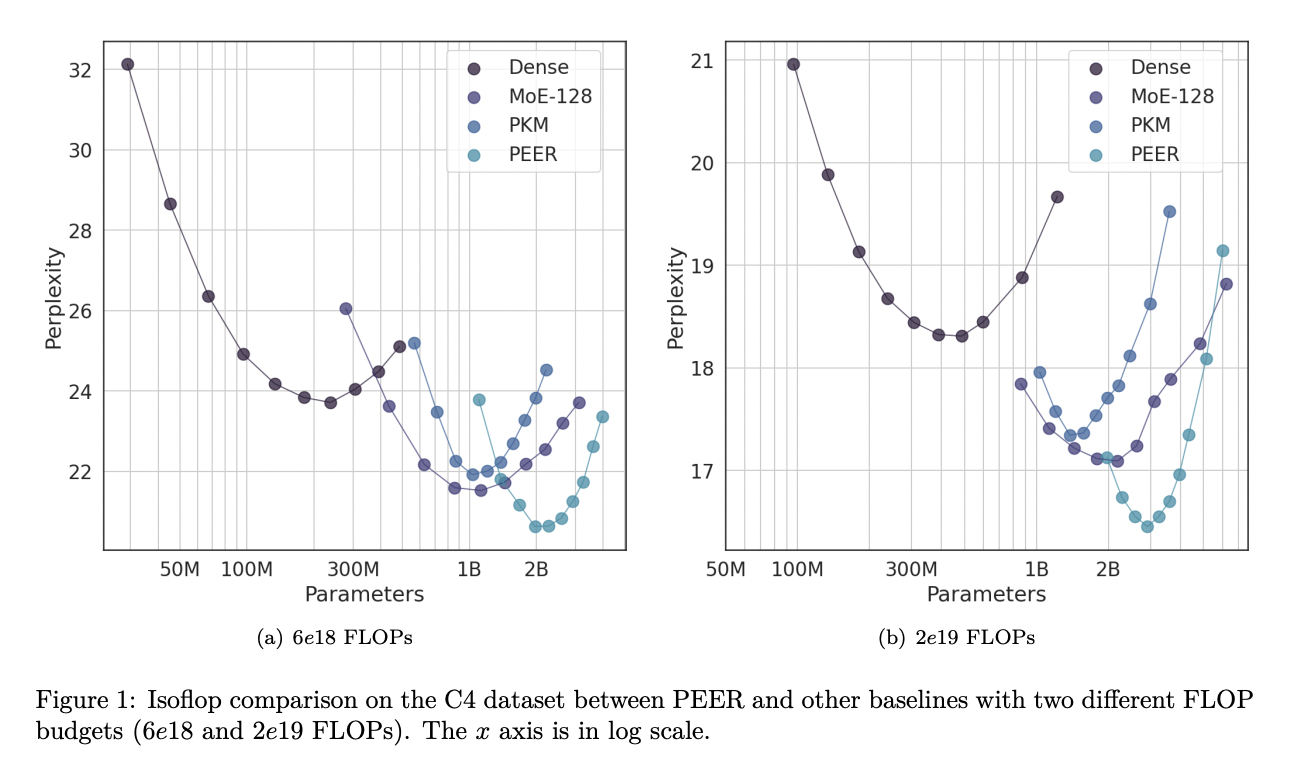
PEER-слои значительно превосходят плотные FFW и крупномасштабные MoE в плане соотношения производительности и вычислительной стоимости. Применительно к нескольким наборам данных для языкового моделирования, включая Curation Corpus, Lambada, Pile, Wikitext и C4, модели PEER достигли заметно более низких показателей перплексии. Например, при бюджете FLOP 2е19 модели PEER достигли перплексии 16.34 на наборе данных C4, что ниже, чем 17.70 для плотных моделей и 16.88 для моделей MoE. Эти результаты подчеркивают эффективность и эффективность архитектуры PEER в улучшении масштабируемости и производительности моделей трансформера.
Заключение
Предложенный метод представляет собой значительный вклад в исследования в области искусственного интеллекта путем внедрения архитектуры PEER. Этот новаторский подход решает вычислительные вызовы, связанные с масштабированием моделей трансформера, используя огромное количество маленьких экспертов и эффективные техники маршрутизации. Превосходное соотношение производительности и вычислительной стоимости модели PEER, продемонстрированное через обширные эксперименты, подчеркивает ее потенциал для продвижения исследований в области искусственного интеллекта путем создания более эффективных и мощных языковых моделей. Полученные результаты показывают, что PEER может успешно масштабироваться для обработки обширных и непрерывных потоков данных, что делает его многообещающим решением для пожизненного обучения и других требовательных приложений искусственного интеллекта.
Посмотрите статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе LinkedIn.
Если вам нравится наша работа, вам понравится наш бюллетень.
Не забудьте присоединиться к нашему SubReddit с 46 тысячами подписчиков.
Источник: MarkTechPost
«`

















