

«`html
Обучение машин для связи изображений и текста
Модели, работающие с изображениями и текстом, обучаются на больших наборах данных. Чем больше данных, тем лучше модели распознают шаблоны и повышают точность.
Проблемы и решения
Существуют модели Vision-Language (VLM), которые используют большие наборы данных для выполнения задач, таких как описание изображений и ответ на визуальные вопросы. Однако, возникает вопрос: при увеличении данных до 100 миллиардов примеров действительно ли улучшается точность и культурное разнообразие? Увеличение данных выше 10 миллиардов замедлилось, и появляется сомнение в дальнейших преимуществах. Большие объемы данных создают проблемы качества, предвзятости и вычислительные ограничения.
Новые подходы для повышения разнообразия
Исследователи из Google Deepmind предложили набор данных WebLI-100B, содержащий 100 миллиардов пар изображений и текста. Это в десять раз больше, чем предыдущие наборы данных. Этот набор данных позволяет улучшить работу моделей в области низкоресурсных языков и разнообразных представлений.
Преимущества WebLI-100B
В отличие от предыдущих наборов, WebLI-100B фокусируется на масштабировании данных, не полагаясь на жесткую фильтрацию, что часто удаляет важные культурные детали. Модели, обученные на этом наборе, лучше справляются с задачами культурного и многоязычного характера.
Качество и многоязычность
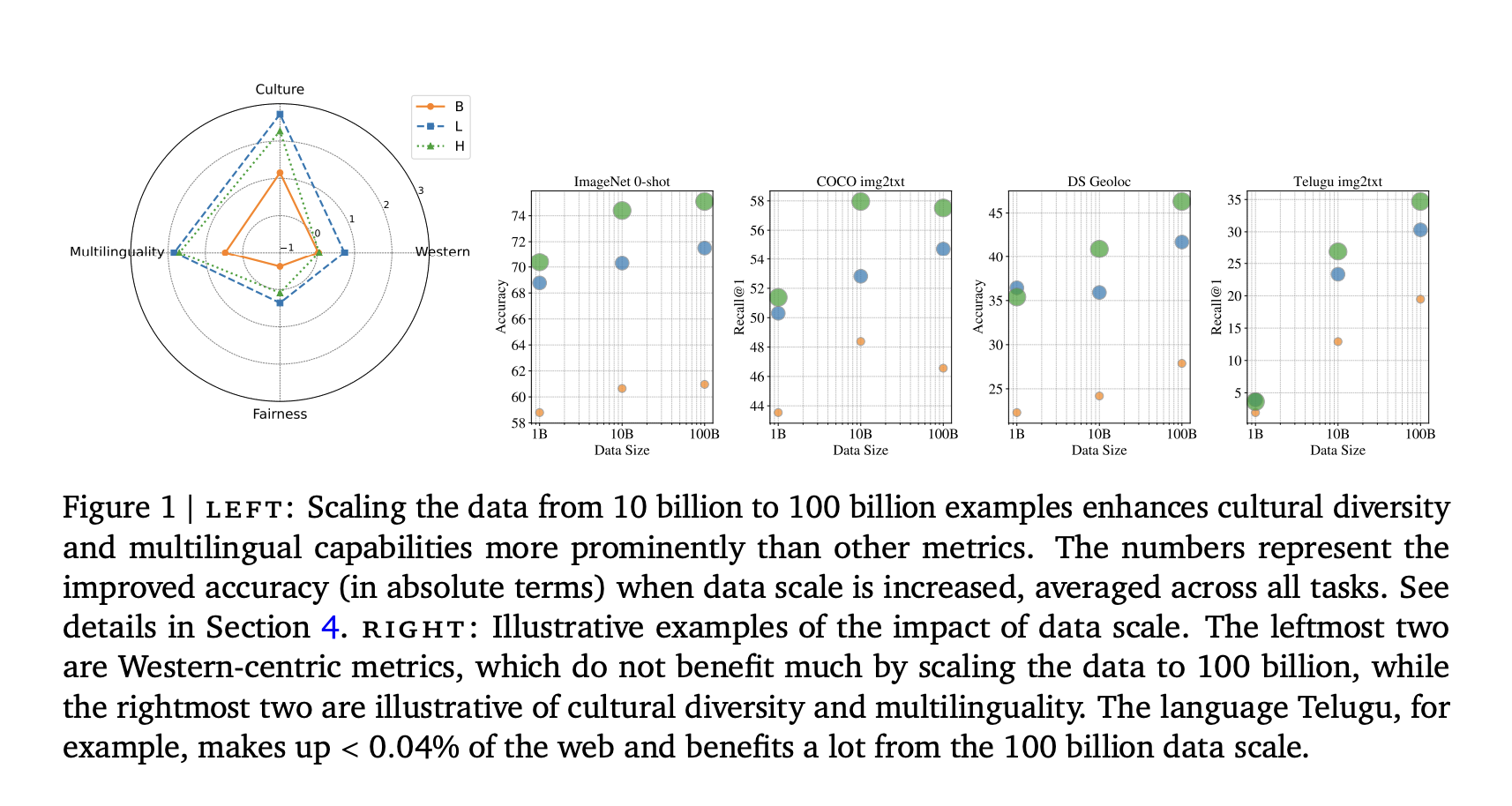
Созданный набор данных включает качественно отфильтрованные 5 миллиардов примеров, а также версию, сбалансированную по языкам. Используя модель SigLIP, исследователи провели оценку различных наборов данных (1B, 10B и 100B) и получили результаты, показывающие, что увеличение размера набора данных от 10B до 100B минимально повлияло на западные стандарты, но улучшило разнообразие культурных задач и поиск низкоресурсных языков.
Заключение
Увеличение наборов данных до 100 миллиардов изображений и текстов улучшает инклюзивность, культурное разнообразие и многоязычие, даже если традиционные тесты показывают ограниченные улучшения. Это исследование может стать основой для будущих разработок, способствующих созданию алгоритмов фильтрации, которые сохраняют разнообразие.
Как использовать ИИ для бизнеса?
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ), выполните следующие шаги:
- Проанализируйте, как ИИ может изменить вашу работу. Найдите области, где автоматизация может помочь вашим клиентам.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Подберите подходящее решение. Начните с небольшого проекта, анализируйте результаты и KPI.
- Расширяйте автоматизацию на основе полученных данных и опыта.
Если вам нужны советы по внедрению ИИ, пишите нам.
Узнайте, как ИИ может изменить процесс продаж в вашей компании с решениями от saile.ru. Будущее уже здесь!
«`

















