

«`html
Google представил инновацию DataGemma для решения проблемы галлюцинаций в крупных языковых моделях искусственного интеллекта
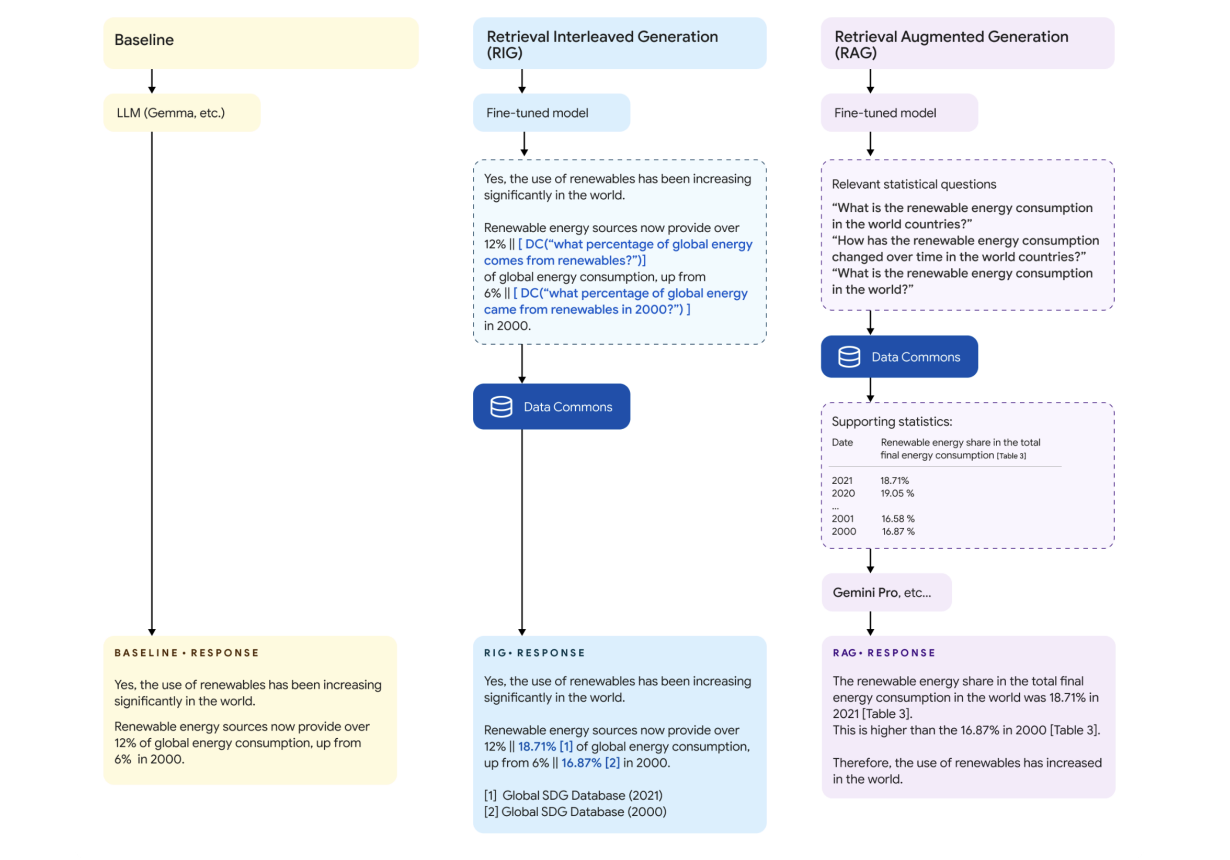
Google представил революционную инновацию под названием DataGemma, разработанную для борьбы с одной из наиболее значительных проблем современного искусственного интеллекта: галлюцинациями в крупных языковых моделях (LLM). Галлюцинации возникают, когда ИИ уверенно генерирует информацию, которая либо неверна, либо выдумана. Эти неточности могут подрывать полезность ИИ, особенно для исследований, разработки политики или других важных процессов принятия решений. В ответ Google DataGemma стремится закрепить LLM в реальном мире, статистических данных, используя обширные ресурсы, доступные через свою Data Commons.
Возникновение крупных языковых моделей и проблемы галлюцинаций
Крупные языковые модели, являющиеся двигателями генеративного искусственного интеллекта, становятся все более сложными. Они могут обрабатывать огромные объемы текста, создавать резюме, предлагать креативные выводы и даже составлять код. Однако одним из критических недостатков этих моделей является их время от времени склонность представлять неверную информацию как факт. Это явление, известное как галлюцинация, вызвало опасения относительно надежности и достоверности контента, созданного ИИ.
Data Commons: основа фактических данных
Data Commons является основой миссии DataGemma, обширного репозитория общедоступных, надежных данных. Этот граф знаний содержит более 240 миллиардов точек данных по многим статистическим переменным, извлеченных из надежных источников, таких как Организация Объединенных Наций, Всемирная организация здравоохранения, Центры по контролю и профилактике заболеваний и различные национальные бюро переписи населения.
«`
…(the rest of the text is omitted)













![6 обязательных курсов по социальным продажам на 2024 год [и советы экспертов по социальным продажам]](https://saile.ru/wp-content/uploads/2025/04/itinai.com_beautiful_Russian_high_fashion_Sales_representativ_81976356-11a7-4f61-9064-75fe15742118_0-200x200.png)



