

«`html
Cerebras Systems Introduces Revolutionary AI Inference Solution
Cerebras Systems представила новое революционное решение для искусственного интеллекта (ИИ), устанавливающее новый стандарт в этой области. Новое решение, Cerebras Inference, обеспечивает несравненную скорость и эффективность обработки больших моделей языка (LLM), отвечая на растущие требования к ИИ-приложениям, особенно требующим реального времени и выполнения сложных многошаговых задач.
Непревзойденная Скорость и Эффективность
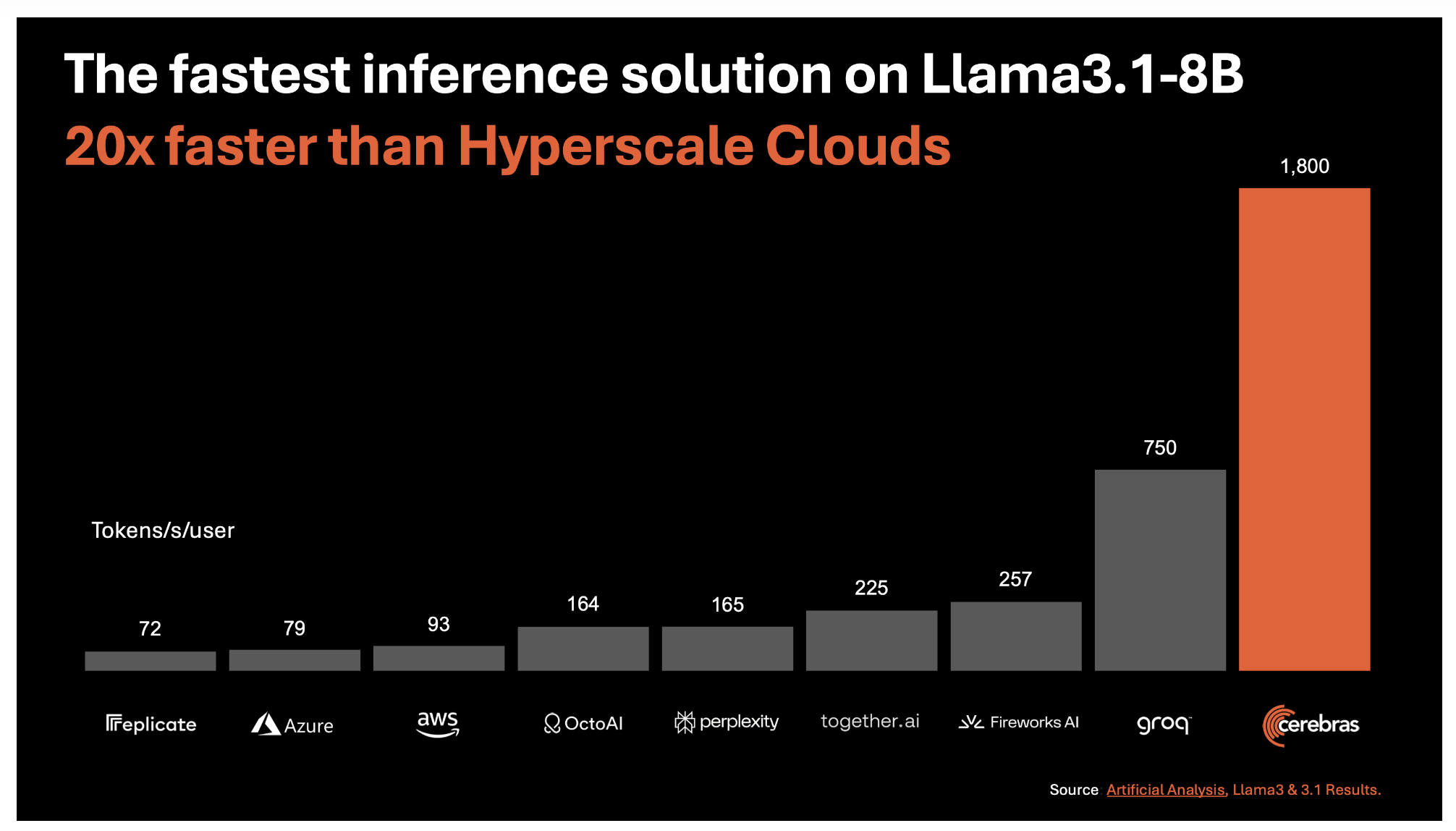
В основе Cerebras Inference лежит третьего поколения Wafer Scale Engine (WSE-3), обеспечивающий самое быстрое решение для ИИ-вычислений на сегодняшний день. Эта технология обеспечивает удивительные 1,800 токенов в секунду для модели Llama3.1 8B и 450 токенов в секунду для модели Llama3.1 70B. Эти скорости примерно в 20 раз выше, чем у традиционных решений на основе GPU в облаке гипермасштаба. Этот прорыв обеспечивает не только высокую скорость, но и стоимость на уровне всего 10 центов за миллион токенов для модели Llama 3.1 8B и 60 центов за миллион токенов для модели Llama 3.1 70B.
Решение Проблемы Пропускной Способности Памяти
Одной из основных проблем в ИИ-вычислениях является необходимость в большой пропускной способности памяти. Cerebras преодолела эту проблему, интегрировав 44 ГБ SRAM непосредственно на чип WSE-3, что позволило избежать использования внешней памяти и значительно увеличить пропускную способность памяти. WSE-3 предлагает поразительные 21 петабайт в секунду агрегированной пропускной способности памяти, в 7,000 раз превышающей Nvidia H100 GPU. Этот прорыв позволяет Cerebras Inference легко обрабатывать большие модели, обеспечивая более быстрое и точное выполнение.
Сохранение Точности с 16-битной Точностью
Еще одним важным аспектом Cerebras Inference является его стремление к точности. В отличие от некоторых конкурентов, снижающих точность веса до 8-бит для достижения более высокой скорости, Cerebras сохраняет исходную 16-битную точность на протяжении всего процесса вывода. Это обеспечивает максимальную точность модельных выводов, что критично для задач, требующих высокой точности, таких как математические вычисления и сложные логические задачи.
Стратегические Партнерства и Будущее Развитие
Cerebras не только сосредотачивается на скорости и эффективности, но также создает мощную экосистему вокруг своего решения для ИИ-вычислений. Она заключила партнерские соглашения с ведущими компаниями в отрасли ИИ, включая Docker, LangChain, LlamaIndex и Weights & Biases, чтобы предоставить разработчикам необходимые инструменты для быстрой и эффективной разработки и внедрения ИИ-приложений.
Влияние на ИИ-приложения
Последствия высокой скорости выполнения Cerebras Inference выходят далеко за рамки традиционных ИИ-приложений. Благодаря значительному сокращению времени обработки, Cerebras позволяет более сложные рабочие процессы ИИ и улучшает реальное время в моделях языка. Это может революционизировать отрасли, зависящие от ИИ, от здравоохранения до финансов, позволяя более быстрые и точные принятия решений. Возможности бесконечны, и Cerebras Inference готов открывать новые перспективы в ИИ-приложениях в различных областях.
«`


















