

«`html
Language Models and Data Curation for Improved AI Performance
Языковые модели (LMs) играют фундаментальную роль в обработке естественного языка (NLP), позволяя генерировать текст, выполнять переводы и анализировать настроение. Однако для их точной и эффективной работы необходимо огромное количество тренировочных данных. Качество и курирование этих наборов данных критически важны для производительности LMs. Основное внимание уделяется улучшению методов сбора и подготовки данных для повышения эффективности моделей.
Проблемы и Решения
Одной из важных задач в разработке эффективных языковых моделей является улучшение тренировочных наборов данных. Создание высококачественных наборов данных является сложной задачей, включающей фильтрацию нерелевантного или вредоносного контента, удаление дубликатов и выбор наиболее полезных источников данных.
Новые Решения
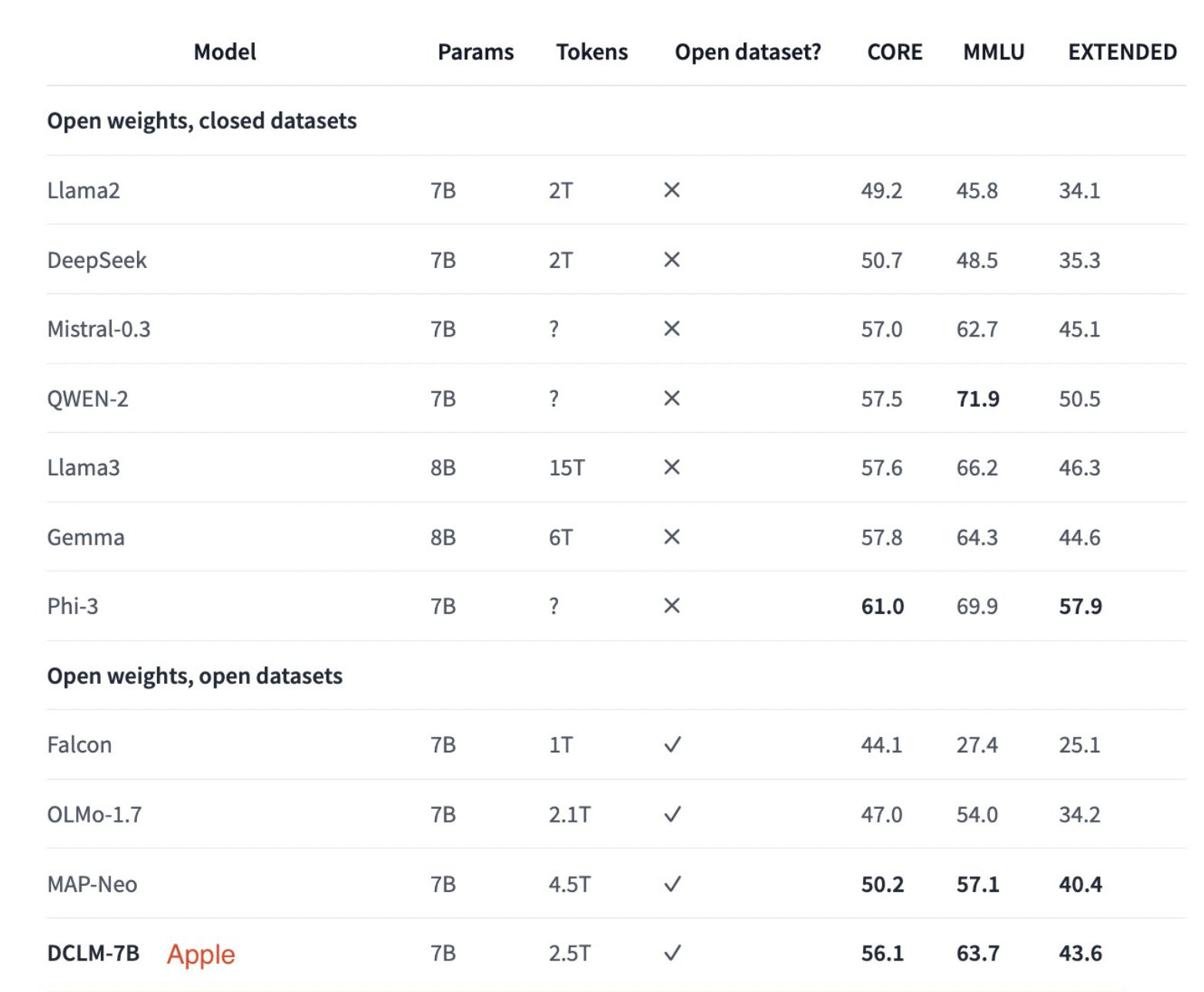
Разработчики из Apple, Университета Вашингтона и других институтов представили DataComp for Language Models (DCLM), чтобы решить эти проблемы. Они недавно опубликовали модели DCIM и наборы данных на платформе Hugging Face. Этот инновационный инструмент позволяет проводить контролируемые эксперименты с большими наборами данных для улучшения языковых моделей.
Практическое Применение
DCLM предлагает структурированный рабочий процесс для исследователей. Участники могут выбирать масштабы от 412 миллионов до 7 миллиардов параметров и экспериментировать с методами курирования данных, такими как удаление дубликатов, фильтрация и смешивание данных. Это систематический подход помогает выявить наиболее эффективные стратегии курирования данных.
Эффективность и Практическое Применение
Внедрение DCLM привело к значительным улучшениям в тренировке языковых моделей, что демонстрируется на практике. Например, базовый набор данных, созданный с использованием DCLM, позволил обучить языковую модель с 7 миллиардами параметров с нуля. Эта модель достигла 64% точности на MMLU-бенчмарке с 2,6 триллионами тренировочных токенов, что представляет собой улучшение на 6,6 процентных пункта по сравнению с предыдущей лучшей языковой моделью с открытыми данными, MAP-Neo, используя при этом на 40% меньше вычислительных ресурсов.
DCLM также обладает значительной масштабируемостью, что подтверждается результатами экспериментов на различных масштабах от 400 миллионов до более чем 7 миллиардов параметров. Эти эксперименты подчеркивают важную роль фильтрации на основе модели в сборе высококачественных тренировочных наборов данных.
Практический Вывод
Введение DCLM позволяет проводить контролируемые эксперименты и выявлять наиболее эффективные стратегии улучшения языковых моделей, предоставляя стандартизированный и систематический подход к курированию данных. Этот инструмент устанавливает новый стандарт качества наборов данных и демонстрирует потенциал для значительного улучшения производительности с использованием сокращенных вычислительных ресурсов.
Применение ИИ в Маркетинге и Продажах
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте AI Sales Bot, который помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Подберите подходящее решение для вашей компании, начните с малого проекта и постепенно расширяйте автоматизацию. Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru – будущее уже здесь!
«`


















