

«`html
Align-Pro: Эффективное решение для согласования больших языковых моделей (LLM)
Согласование больших языковых моделей с человеческими ценностями становится важным, поскольку эти модели играют центральную роль в различных аспектах общества. Однако, когда параметры модели нельзя обновить напрямую, необходимо корректировать входные запросы, чтобы результаты модели соответствовали желаемым.
Проблемы текущих методов
Современные методы, такие как обучение с подкреплением на основе человеческой обратной связи (RLHF), требуют тонкой настройки параметров модели. Эти методы эффективны, но ресурсоемки и не подходят для замороженных или недоступных моделей.
Решение Align-Pro
Исследователи из Университета Центральной Флориды, Университета Мэриленда и Университета Пердью предложили Align-Pro — фреймворк для оптимизации запросов, который позволяет согласовывать LLM без изменения их параметров. Ключевые шаги включают:
- Тонкая настройка с использованием человеческих данных.
- Обучение модели вознаграждений на основе экспертной обратной связи.
- Оптимизация с использованием обучения с подкреплением.
Результаты экспериментов
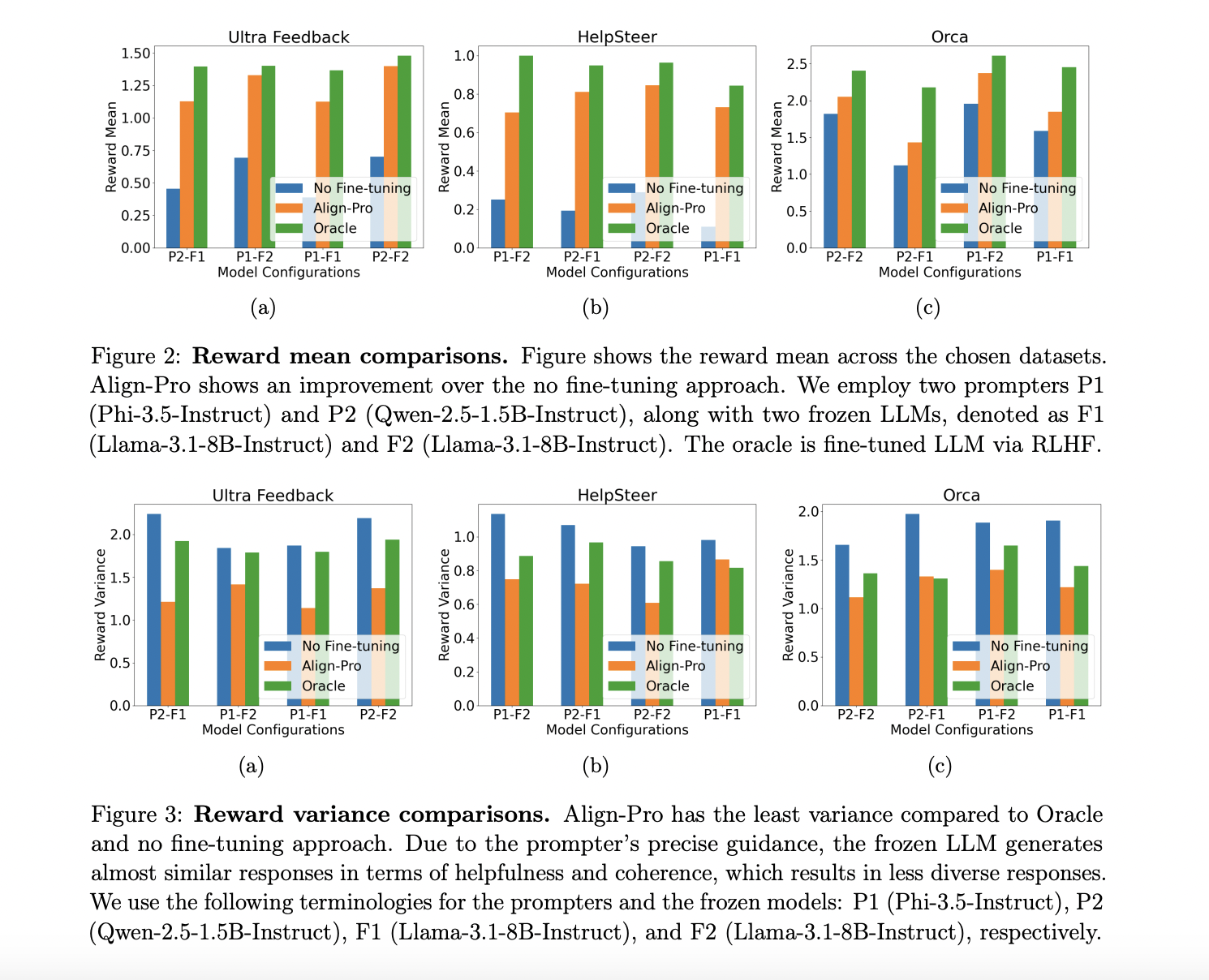
Эксперименты показали, что Align-Pro превосходит базовые методы по всем тестовым наборам, обеспечивая лучшие средние вознаграждения и более низкую вариацию вознаграждений. Это подтверждает, что оптимизация запросов может эффективно работать с замороженными моделями.
Преимущества Align-Pro
Фреймворк позволяет:
- Снижать вычислительные затраты.
- Сохранять предобученные возможности LLM.
- Не требовать тонкой настройки LLM.
Рекомендации для бизнеса
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, используйте Align-Pro:
- Анализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить.
- Внедряйте ИИ решения постепенно, начиная с небольших проектов.
Если вам нужны советы по внедрению ИИ, пишите нам в Телеграм.
Узнайте, как ИИ может изменить процесс продаж в вашей компании с решением от saile.ru — будущее уже здесь!
«`

















