

«`html
Улучшение производительности долгих контекстовых языковых моделей с помощью MInference
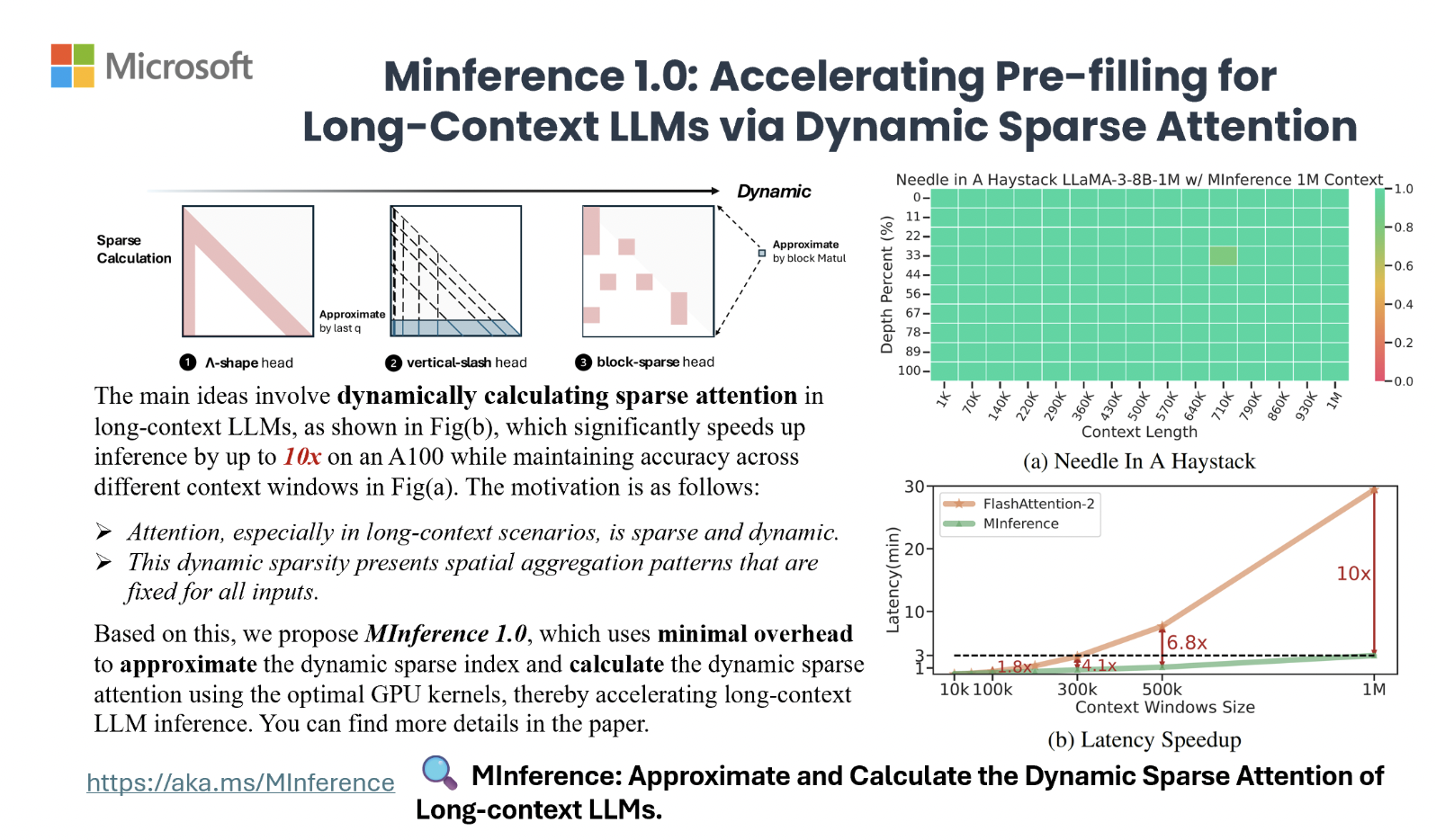
Высокая вычислительная сложность долгих контекстовых языковых моделей (LLM) затрудняет их практическое использование из-за квадратичной сложности механизма внимания. Но MInference (Milliontokens Inference) предлагает эффективное решение для ускорения обработки длинных последовательностей в LLM. Этот метод динамически оптимизирует разреженные вычисления для графических процессоров, обеспечивая значительное ускорение без изменения предварительного обучения или тонкой настройки.
Оптимизация разреженного внимания
Используя три различных шаблона внимания — A-форма, Вертикальная черта и Блочно-разреженное внимание, MInference значительно сокращает время предварительной обработки, обеспечивая до 10-кратное ускорение на GPU A100. Это позволяет существенно снизить задержки и улучшить эффективность работы LLM.
Практическое применение
MInference демонстрирует свою эффективность на различных контекстных длинах и в различных сценариях, таких как вопросно-ответные системы, суммаризация и поиск информации. Он также интегрируется с техниками сжатия кэша KV и значительно сокращает задержку, что подтверждает его практическую ценность в оптимизации производительности LLM.
Применение в бизнесе
Если вы хотите улучшить процессы с помощью искусственного интеллекта, MInference предлагает эффективное решение для ускорения работы LLM. Начните с малого проекта, анализируйте результаты и постепенно расширяйте автоматизацию. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot itinai.ru/aisales, который помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`


















