

«`html
Эффективное развертывание крупномасштабных моделей трансформера: стратегии масштабируемого и низколатентного вывода
Масштабирование моделей на основе трансформера до более чем 100 миллиардов параметров привело к революционным результатам в обработке естественного языка. Эти большие языковые модели отлично справляются с различными приложениями, но их эффективное развертывание представляет вызовы из-за последовательной природы генеративного вывода, где вычисление каждого токена зависит от предшествующих токенов. Это требует тщательного параллельного размещения и оптимизации памяти. Исследование подчеркивает важные инженерные принципы для эффективного обслуживания крупномасштабных моделей трансформера в различных производственных средах, обеспечивая масштабируемость и низколатентный вывод.
Ключевые практические решения и ценность
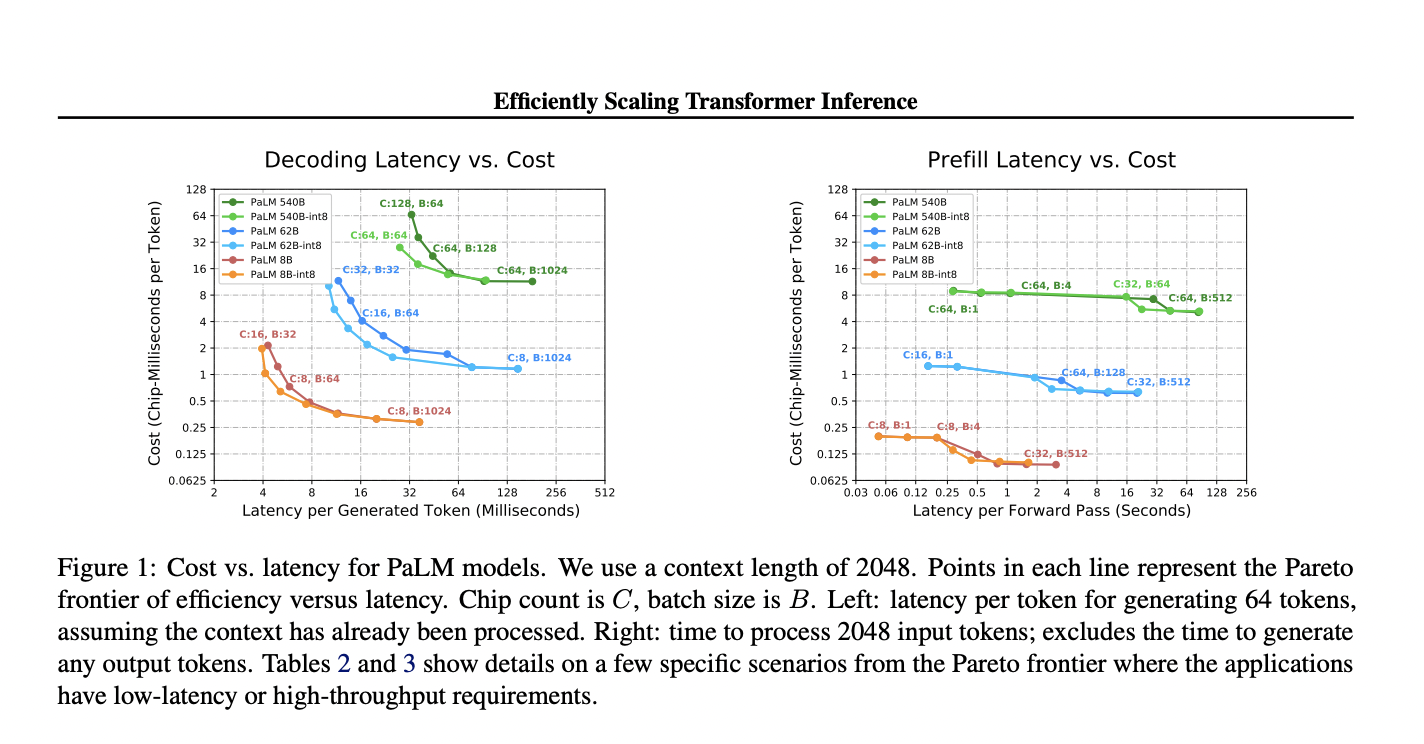
Исследователи Google изучают эффективный генеративный вывод для крупных моделей трансформера, сосредотачиваясь на жестких целях латентности и длинных длинах последовательностей. Они разработали аналитическую модель для оптимизации многомерных техник разделения для срезов TPU v4 и реализовали низкоуровневые оптимизации. Это позволило добиться превосходной латентности и компромиссов по использованию FLOPS модели (MFU) для моделей с 500 миллиардами параметров, превзойдя бенчмарки FasterTransformer. Используя многозапросное внимание, они масштабировали длину контекста до 32× больше. Их модель PaLM 540B достигла латентности 29 мс на токен с квантованием int8 и MFU 76%, поддерживая длину контекста 2048 токенов, выделяя практические применения в чат-ботах и высокопроизводительном оффлайн выводе.
Предыдущие работы по эффективному разделению для обучения крупных моделей включают NeMo Megatron, GSPMD и Alpa, которые используют параллелизм тензоров и конвейерную параллельность с оптимизацией памяти. FasterTransformer устанавливает бенчмарки для многографического многокомпьютерного вывода, в то время как DeepSpeed Inference использует ZeRO offload для использования памяти CPU и NVMe. EffectiveTransformer уменьшает заполнение, упаковывая последовательности. В отличие от них, это исследование разрабатывает стратегии разделения на основе аналитических компромиссов. Для улучшения эффективности вывода подходы включают эффективные слои внимания, дистилляцию, обрезку и квантование. Исследование включает квантование модели для ускорения вывода и предлагает, что его техники могут дополнить другие методы сжатия.
Увеличение размеров моделей улучшает их возможности, но увеличивает латентность, производительность и стоимость вывода по MFU. Ключевые метрики включают латентность (время предварительной загрузки и декодирования), производительность (обработанные/сгенерированные токены в секунду) и MFU (наблюдаемая против теоретической производительности). Большие модели сталкиваются с проблемами памяти и вычислений, с малыми размерами партий, которые доминируют временем загрузки весов, а большими — кэшем KV. Эффективный вывод требует балансировки низкой латентности и высокой производительности через стратегии, такие как 1D/2D размещение весов и сбора весов. Механизмы внимания влияют на использование памяти, многозапросное внимание уменьшает размер кэша KV, но добавляет коммуникационные издержки.
В исследовании моделей PaLM, техники, такие как многозапросное внимание и параллельные слои внимания/прямого распространения, были оценены с использованием JAX и XLA на чипах TPU v4. Для модели PaLM 540B, улучшение разделения внимания к заполнению повысило эффективность разделения. Были протестированы различные стратегии разделения: 1D и 2D размещение весов и сбора весов, при этом 2D показал лучшие результаты при более высоком количестве чипов. Многозапросное внимание позволило использовать более длинные контексты с меньшим использованием памяти, чем многоголовое внимание. Исследование продемонстрировало, что оптимизация размещения на основе размера партии и фазы (предварительная загрузка против генерации) является ключевой для балансировки эффективности и латентности.
Большие модели трансформера революционизируют различные области, но их демократизация требует значительных усовершенствований. Это исследование исследует масштабирование рабочих нагрузок вывода трансформера и предлагает практические методы разделения для удовлетворения строгих требований к латентности, особенно для моделей с более чем 500 миллиардами параметров. Оптимальные латентности были достигнуты за счет масштабирования вывода на 64+ чипах. Многозапросное внимание с эффективным разделением уменьшает затраты памяти для вывода с длинным контекстом. Хотя масштабирование улучшает производительность, количество операций с плавающей запятой и объем коммуникации остаются ограничивающими факторами. Техники, такие как разреженные архитектуры и адаптивные вычисления, которые уменьшают количество операций с плавающей запятой на токен и объем коммуникации между чипами, обещают дальнейшие улучшения стоимости и латентности.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему Telegram каналу и группе LinkedIn.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему SubReddit с 46 тысячами подписчиков.
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Efficient Deployment of Large-Scale Transformer Models: Strategies for Scalable and Low-Latency Inference .
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизацию: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на itinai. Следите за новостями о ИИ в нашем Телеграм-канале itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot itinai.ru/aisales. Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!
«`

















