

«`html
MaVEn: An Effective Multi-granularity Hybrid Visual Encoding Framework for Multimodal Large Language Models (MLLMs)
Основное направление существующих многомодальных моделей обработки языка (MLLMs) — это интерпретация отдельных изображений, что ограничивает их способность решать задачи, включающие множество изображений. Для решения таких проблем требуется создание моделей, способных понимать и интегрировать информацию сразу с нескольких изображений, включая вопросно-ответные системы на базе знаний (VQA), визуальное логическое вывод, и множественное рассуждение на основе изображений. Большинство существующих MLLMs испытывают затруднения в этих сценариях из-за их архитектуры, ориентированной в основном на обработку одного изображения, несмотря на расширение потребности в таких навыках в реальных приложениях.
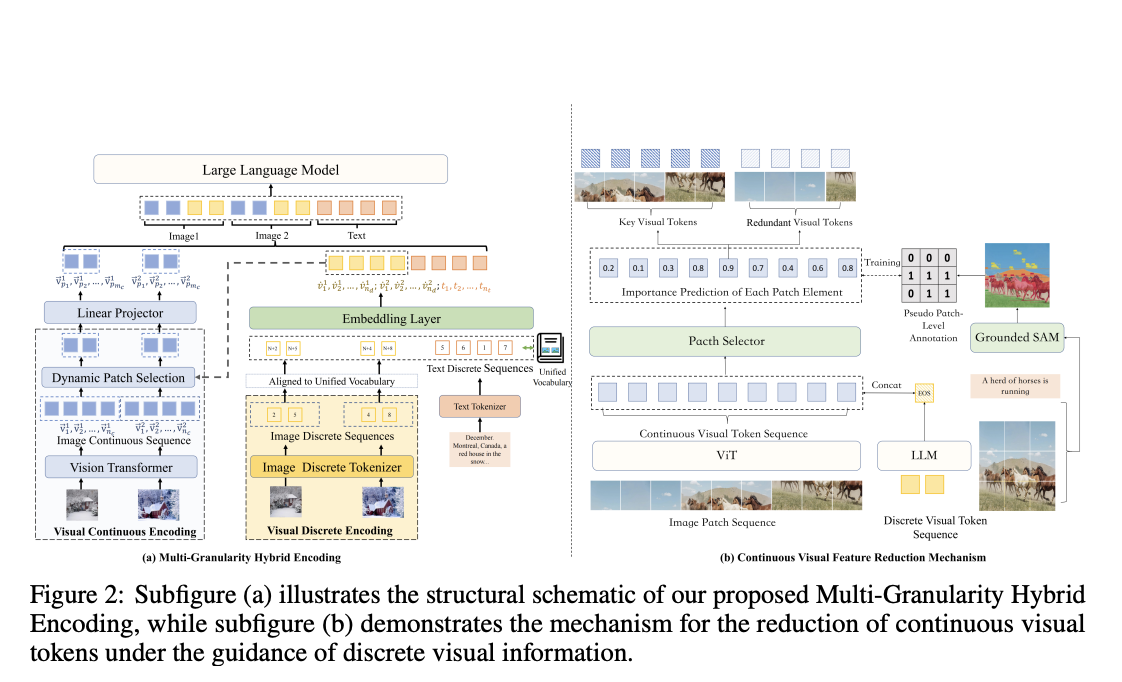
В последних исследованиях команда исследователей представила MaVEn — мультигранулярную визуальную кодировочную платформу, разработанную для улучшения производительности MLLMs в задачах, требующих логического вывода с участием нескольких изображений. Основной целью традиционных MLLMs является понимание и обработка отдельных фотографий, что ограничивает их способность эффективно обрабатывать и объединять данные из нескольких изображений одновременно. MaVEn использует уникальную стратегию, объединяющую два различных вида визуальных представлений, чтобы преодолеть эти препятствия, которые представлены ниже.
Дискретные визуальные символьные последовательности: эти шаблоны извлекают семантические концепции с грубой текстурой изображений. MaVEn упрощает представление высокоуровневых концепций, абстрагируя визуальную информацию в дискретные символы, что облегчает выравнивание и интеграцию этой информации с текстовыми данными.
Последовательности для непрерывного представления: эти последовательности используются для имитации мелкозернистых характеристик изображений, сохраняя специфические визуальные детали, которые могли бы быть упущены в представлении только дискретными. Это гарантирует, что модель все еще имеет доступ к тонкой информации, необходимой для обоснованного толкования и логики.
MaVEn совмещает текстовые и визуальные данные, улучшая способность модели понимать и обрабатывать информацию сразу с различных изображений последовательно. Этот двойной метод кодирования сохраняет эффективность модели в задачах с отдельным изображением, одновременно повышая ее производительность в многокартинных ситуациях.
MaVEn также представляет метод динамического сокращения, предназначенный для управления длинными последовательностями непрерывных признаков, которые могут возникать в ситуациях с несколькими изображениями. Оптимизируя эффективность обработки модели, этот метод снижает вычислительную сложность, не жертвуя качеством визуальных данных, которые кодируются.
Эксперименты показали, что MaVEn значительно улучшает производительность MLLM в сложных ситуациях, требующих логического вывода с участием нескольких изображений. Кроме того, это демонстрирует, как платформа улучшает производительность моделей в задачах с отдельным изображением, что делает ее гибким решением для различных приложений визуальной обработки.
Команда подводит итоги своих основных преимуществ:
1. Предложена уникальная платформа, объединяющая непрерывные и дискретные визуальные представления. Это значительно улучшает способность MLLMs обрабатывать и понимать сложную визуальную информацию с нескольких изображений, а также способность рассуждать среди нескольких изображений.
2. Для решения длинных последовательностей непрерывных визуальных аспектов в исследовании создается динамический механизм сокращения. Оптимизируя эффективность обработки нескольких изображений, этот метод уменьшает вычислительную нагрузку в ML-моделях без ущерба точности.
3. Метод проявляет отличную производительность в различных сценариях многокартинного логического вывода. Он также приносит пользу в стандартных бенчмарках с отдельными изображениями, демонстрируя свою адаптивность и эффективность в различных приложениях визуальной обработки.
«`















![Что такое заказ на покупку и как его создать [с шаблоном]](https://saile.ru/wp-content/uploads/2025/05/itinai.com_IT-company_office_background_blured_-chaos_50_-v_74e4829b-a652-4689-ad2e-c962916303b4_0-200x200.avif)



