

«`html
Efficient Medical Image Classification through Unsupervised Adaptation of Vision-Language Models
Обучение с учителем в классификации медицинских изображений сталкивается с проблемой недостатка размеченных данных, так как экспертные аннотации сложно получить. Модели видение-язык (VLM) решают эту проблему, используя выравнивание визуального и текстового контента, позволяя без учителя уменьшить зависимость от размеченных данных. Предварительное обучение на больших медицинских наборах данных изображений и текста позволяет моделям VLM генерировать точные метки и подписи, снижая стоимость аннотации. Активное обучение определяет ключевые образцы для экспертной аннотации, а трансферное обучение настраивает предварительно обученные модели на конкретных медицинских наборах данных. Модели VLM также генерируют синтетические изображения и аннотации, улучшая разнообразие данных и производительность моделей в задачах медицинского изображения.
MedUnA: Метод эффективной медицинской невероятностьной адаптации для классификации изображений
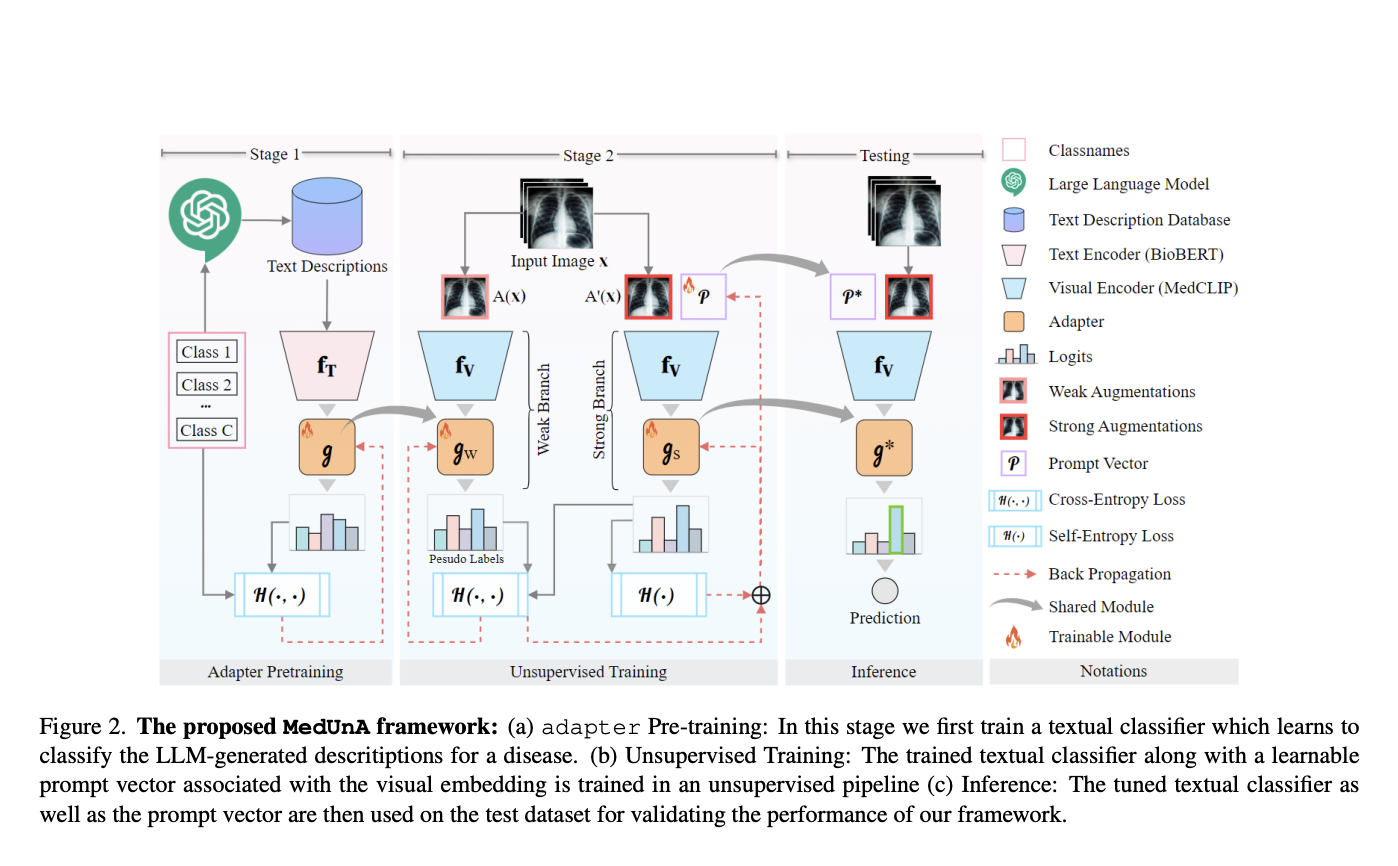
Исследователи из Университета искусственного интеллекта Мохамеда Бин Зайеда и Института искусственного интеллекта предлагают MedUnA, метод медицинской без учителя адаптации для классификации изображений. MedUnA использует двухступенчатое обучение: Предварительное обучение адаптера с использованием текстовых описаний, созданных LLM, выравненных с классовыми метками, и последующее без учителя обучение. Адаптер интегрируется с визуальным кодировщиком MedCLIP, используя минимизацию энтропии для выравнивания визуальных и текстовых эмбеддингов. MedUnA решает проблему модальной разницы между текстовыми и визуальными данными, улучшая производительность классификации без необходимости обширного предварительного обучения. Этот метод эффективно адаптирует модели видение-язык для медицинских задач, уменьшая зависимость от размеченных данных и улучшая масштабируемость.
Особенности метода и преимущества
Основной отличительной чертой метода MedUnA является использование существующего выравнивания между визуальными и текстовыми эмбеддингами для избежания обширного предварительного обучения. Он использует неразмеченные изображения и авто-сгенерированные описания от LLM для категорий болезней. Легкий адаптер и вектор запроса обучаются для минимизации самоэнтропии, обеспечивая уверенную производительность при множественных улучшениях данных. MedUnA предлагает улучшенную эффективность и производительность без необходимости обширного предварительного обучения.
Эксперименты и результаты
Эксперименты, проверившие предложенный метод на пяти общедоступных медицинских наборах данных, показали, что MedUnA достиг лучшей точности по сравнению с базовыми моделями. Метод оценивался с использованием визуальных кодировщиков CLIP и MedCLIP, и MedCLIP в целом проявил себя лучше. Было использовано без учителя обучение для генерации псевдо-меток для неразмеченных изображений, и модели обучались с использованием оптимизатора SGD. Результаты показали, что MedUnA достиг превосходной точности по сравнению с базовыми моделями.
Перспективы использования и значимость исследования
Исследование анализирует экспериментальные результаты, выявляя производительность MedUnA по сравнению с другими методами, такими как CLIP, MedCLIP, LaFTer и TPT. MedUnA продемонстрировал значительное улучшение точности на нескольких медицинских наборах данных, превзойдя нулевое MedCLIP в большинстве случаев.
«`
Please let me know if you need further assistance.


















