

«`html
Автодегрессионные языковые модели (ALM)
Автодегрессионные языковые модели (ALM) доказали свои возможности в машинном переводе, генерации текста и т. д. Однако эти модели представляют определенные вызовы, такие как вычислительная сложность и использование памяти GPU. Несмотря на большой успех в различных приложениях, существует срочная необходимость найти экономически эффективный способ обслуживания этих моделей.
Вызовы авто-регрессионных LLM
Генеративный вывод больших языковых моделей (LLM) использует механизм кеширования KV для увеличения скорости генерации. Однако увеличение размера модели и длины генерации приводит к увеличению использования памяти кеша KV. Когда использование памяти превышает емкость GPU, генеративный вывод LLM прибегает к отключению.
Практическое решение: FastGen
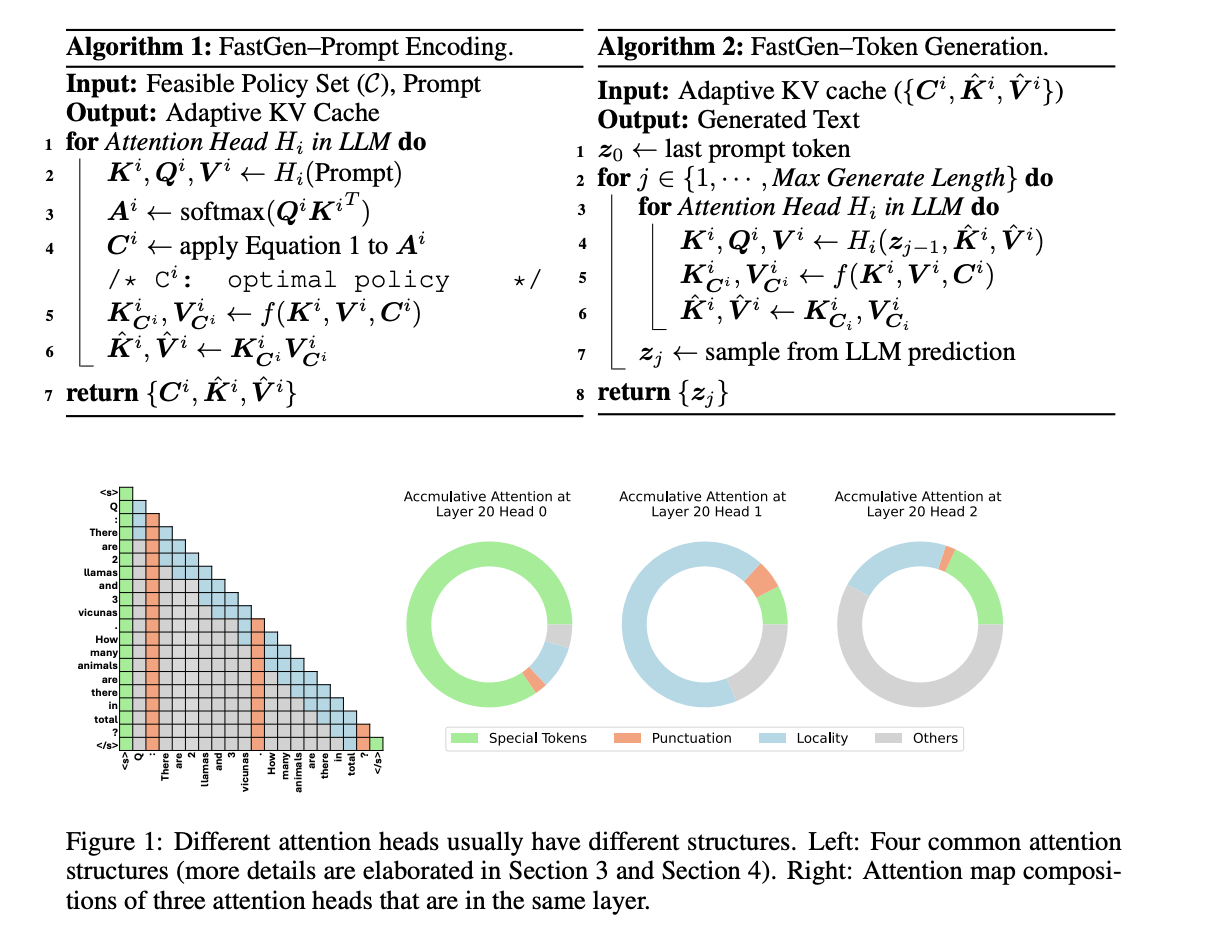
Исследователи из Университета Иллинойса в Урбане-Шампейне и Microsoft предложили FastGen — высокоэффективную технику для повышения эффективности вывода LLM без потери видимого качества, используя легкое профилирование модели и адаптивное кеширование ключ-значение. FastGen способен сокращать использование памяти GPU с минимальной потерей качества генерации.
Применение FastGen
FastGen учитывает компрессию адаптивного кеша KV, что позволяет уменьшить объем памяти для генеративного вывода LLM. Этот метод включает два этапа для вывода генеративной модели:
- Кодирование запроса: Модуль внимания собирает контекстную информацию от всех предыдущих i-1 токенов для i-го токена, сгенерированного авторегрессионной трансформерной LLM.
- Генерация токена: Завершив кодирование запроса, LLM генерирует выходной токен пошагово, и для каждого шага новые токены, сгенерированные на предыдущем шаге, кодируются с использованием LLM.
Результаты
FastGen превосходит все неадаптивные методы сжатия KV для 30B моделей и достигает более высокого коэффициента сокращения кеша KV при увеличении размера модели, сохраняя качество модели без изменений.
Заключение
FastGen — новая техника для повышения эффективности вывода LLM без потери видимого качества, используя легкое профилирование модели и адаптивное кеширование ключ-значение. Также было внедрено адаптивное сжатие KV Cache для уменьшения памяти генеративного вывода LLM. В будущем предполагается интегрировать FastGen с другими методами сжатия моделей, такими как квантизация и дистилляция, а также использовать групповой запрос внимания и др.
Полный текст статьи доступен по ссылке.
«`
Ресурсы, такие как [ссылка], [ссылка] и [ссылка], были отредактированы, чтобы соответствовать указаниям и быть включенными в HTML-код.

















