

«`html
Графовые нейронные сети (GNN), также известные как нейроалгоритмические рассудители (NAR), доказали свою эффективность в решении алгоритмических задач различного размера в различных средах. Однако NAR все еще являются узкими формами искусственного интеллекта, поскольку требуют строго структурированного ввода и не могут быть применены к задачам, поставленным в шумной форме, например, естественным языком, даже если основная проблема является алгоритмической. Напротив, модели языка на основе трансформеров отлично моделируют шумные текстовые данные, но испытывают трудности с алгоритмическими задачами, особенно теми, которые требуют обобщения за пределами распределения. Основной вызов заключается в разработке методов, способных обрабатывать алгоритмическое мышление на естественном языке, сохраняя при этом сильные обобщающие способности.
TransNAR: совмещение Transformer и GNN-based NAR
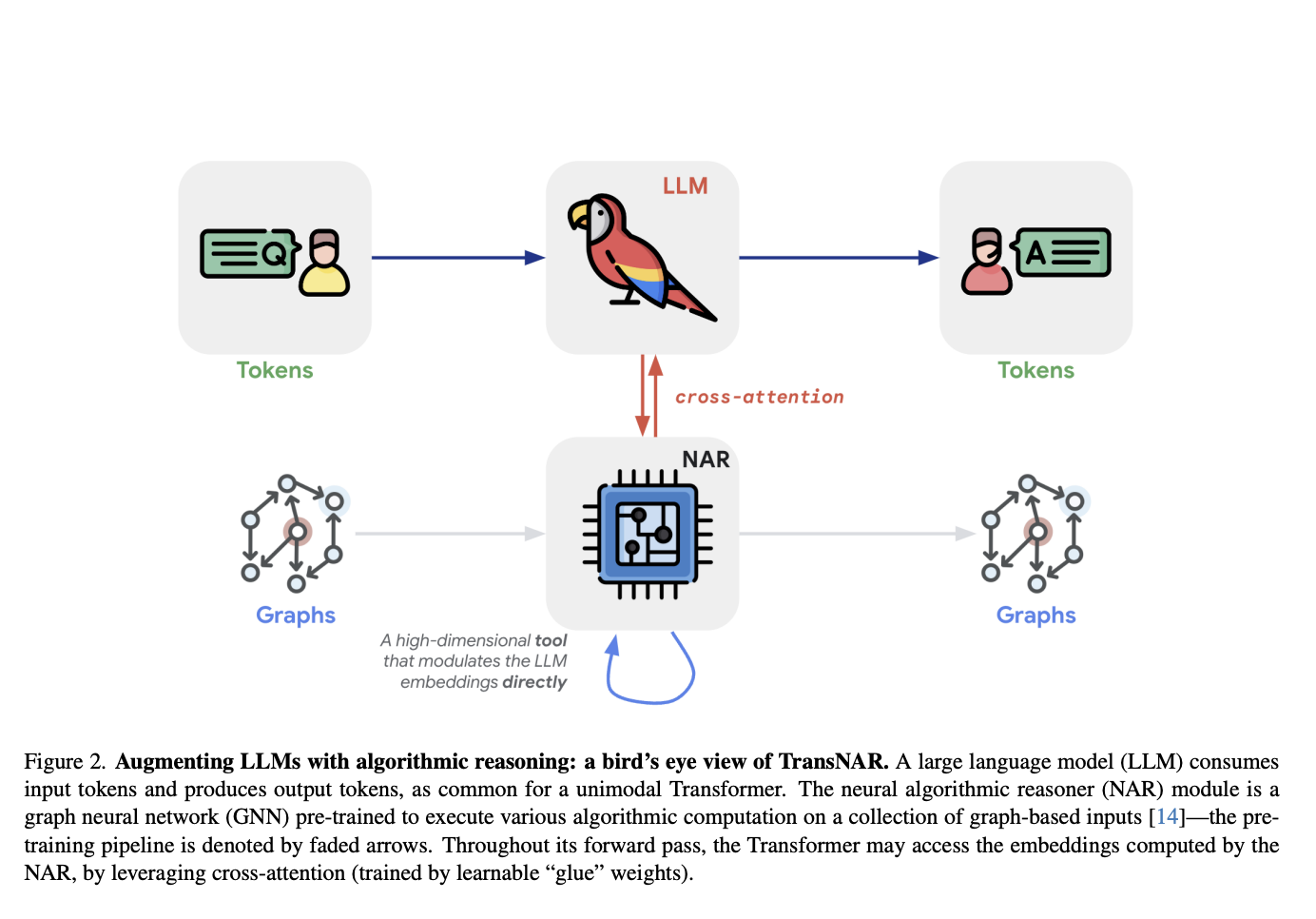
Исследователи DeepMind предложили TransNAR, который представляет собой гибридную архитектуру, объединяющую возможности понимания языка трансформеров с надежными алгоритмическими способностями предварительно обученных GNN-основанных NAR. Трансформер использует NAR в качестве высокоразмерного инструмента для модуляции своих токенов. Модуль NAR представляет собой GNN, предварительно обученную для выполнения различных алгоритмических вычислений на основе графов. В процессе своего прохода трансформер может получить доступ к эмбеддингам, вычисленным NAR, используя кросс-внимание с обучаемыми весами «склейки». Эта синергия между трансформерами и NAR нацелена на улучшение способностей рассуждения языковых моделей, особенно для алгоритмических задач вне распределения.
Преимущества TransNAR
Метод TransNAR основан на нескольких областях исследований: нейроалгоритмическое рассуждение, обобщение длины в языковых моделях, использование инструментов и мультимодальность. Он вдохновлен работами, демонстрирующими, что NAR может выполнять несколько алгоритмов одновременно и обобщаться далеко за пределы обучающего распределения. TransNAR использует предварительно обученный мультизадачный модуль NAR и развертывает его в большем масштабе, интегрируя его с языковой моделью. Объединяя понимание языка трансформеров с надежным алгоритмическим рассуждением NAR, TransNAR нацелен на улучшение способностей рассуждения, особенно для алгоритмических задач вне распределения, поставленных на естественном языке.
Архитектура и результаты TransNAR
Архитектура TransNAR принимает два входа: текстовую спецификацию алгоритмической задачи и ее соответствующее графовое представление из бенчмарка CLRS-30. Проход модели чередует слои трансформеров, обрабатывающие текстовый ввод, с слоями NAR, работающими с графовым вводом. Критически важно то, что слои трансформеров используют кросс-внимание для условием своих токенов на эмбеддинги узлов, вычисленные NAR. Эта синергия позволяет языковой модели дополнить свое понимание надежными алгоритмическими способностями предварительно обученного модуля NAR. Модель обучается end-to-end с целью предсказания следующего токена в текстовом выводе.
Результаты демонстрируют значительное улучшение модели TransNAR по сравнению с базовым трансформером. TransNAR превосходит базовую модель в целом и по большинству отдельных алгоритмов как в пределах распределения, так и вне его. Важно отметить, что TransNAR не только улучшает существующие возможности обобщения вне распределения, но и позволяет достичь таких возможностей, когда они полностью отсутствуют в базовой модели. Анализ оценки формы показывает, что привязка выводов трансформера к эмбеддингам NAR увеличивает долю входов, для которых модель выдает правильные выводы, устраняя конкретный вид неудач. Однако TransNAR все еще испытывает трудности с алгоритмами, включающими поиск определенного индекса во входном списке, намекая на единый вид неудачи, связанный с обобщением к надежным границам индексов, невидимым во время обучения.
TransNAR: решение для вашего бизнеса
TransNAR — это гибридная архитектура, объединяющая языковую модель трансформера с предварительно обученной графовой нейронной сетью NAR. Путем базирования возможностей понимания языка трансформеров на надежном алгоритмическом рассуждении NAR, TransNAR может эффективно решать алгоритмические задачи, указанные на естественном языке. Оценка на бенчмарке CLRS-Text продемонстрировала превосходство TransNAR над моделями только на трансформерах как в пределах распределения, так и, что критически важно, вне его с увеличенными входными данными.
Подробнее ознакомьтесь с исследованием. Вся заслуга за это исследование принадлежит его авторам. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему субреддиту по машинному обучению.
«`


















