

Внедрение техники обучения с подкреплением от обратной связи человека (RLHF) для улучшения работы крупных языковых моделей (LLM)
Проблемы и решения
RLHF играет ключевую роль в обеспечении понятного и надежного поведения систем искусственного интеллекта. Он улучшает возможности LLM, обучая их на основе обратной связи, что позволяет моделям производить более полезные, безопасные и честные результаты.
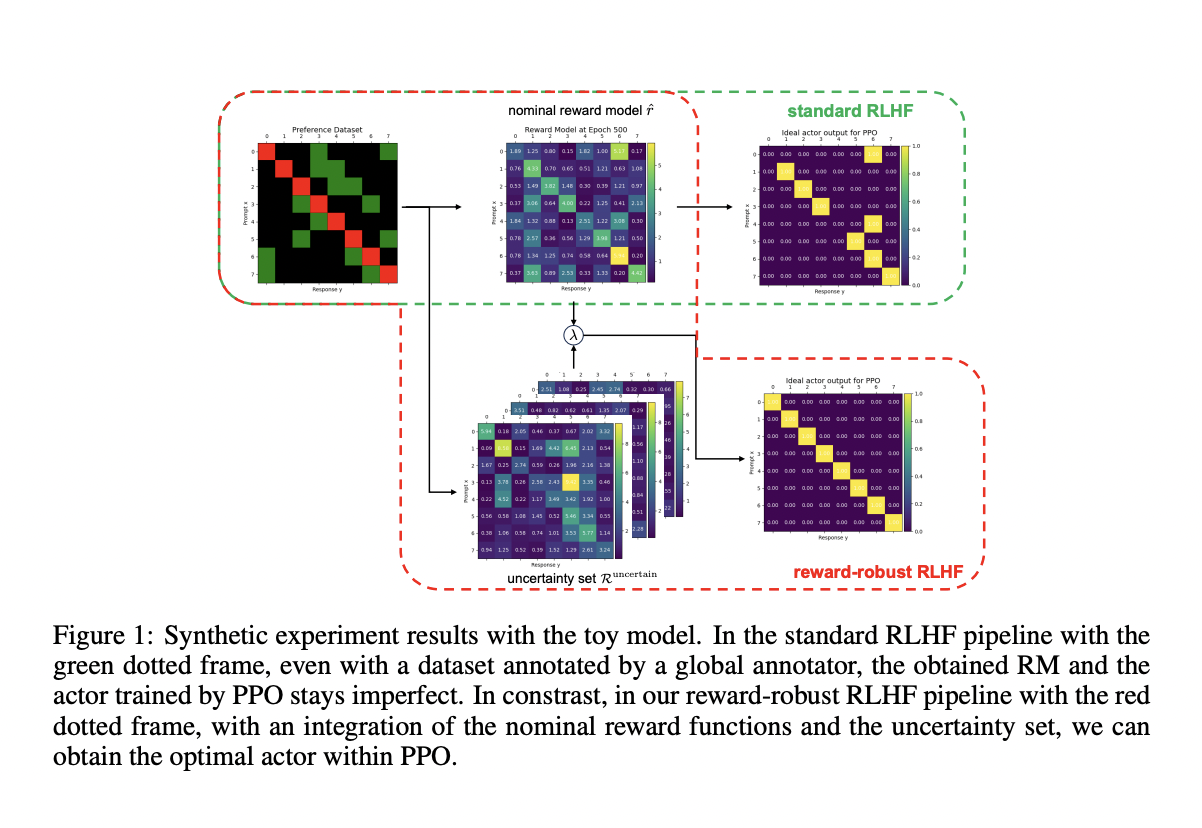
Однако RLHF сталкивается с несколькими фундаментальными проблемами, такими как нестабильность и врожденные недостатки в моделях вознаграждения, которые руководят процессом обучения. Эти проблемы могут привести к нежелательным последствиям, таким как взлом вознаграждения, переобучение и недообучение, что затрудняет выравнивание поведения модели с истинным намерением человека.
Недавние исследования предлагают инновационный подход с использованием ансамблей байесовских моделей вознаграждения (BRME), который позволяет управлять неопределенностью в сигналах вознаграждения. Этот подход демонстрирует впечатляющую производительность, превосходя традиционные методы RLHF на различных показателях.
Практические шаги
Для успешного внедрения ИИ в бизнес, определите области, где автоматизация может приносить пользу клиентам. Выберите ключевые показатели эффективности, которые хотите улучшить с помощью ИИ.
Постепенно внедряйте ИИ-решения, начиная с небольших проектов, и анализируйте результаты. Расширяйте автоматизацию на основе полученного опыта.
Используйте AI Sales Bot для улучшения процесса продаж и обслуживания клиентов. Этот AI ассистент поможет вам эффективно отвечать на вопросы клиентов и генерировать контент.

















