

«`html
Оценка возможностей извлечения и рассуждения больших языковых моделей (LLM) в длинных контекстах
Оценка возможностей извлечения и рассуждения больших языковых моделей (LLM) в крайне длинных контекстах, расширяющихся до 1 миллиона токенов, представляет собой значительное испытание. Эффективная обработка длинных текстов критически важна для извлечения актуальной информации и принятия точных решений на основе обширных данных. Эта проблема особенно актуальна для реальных приложений, таких как анализ юридических документов, академические исследования и бизнес-аналитика. Решение этой проблемы является важным для продвижения исследований в области искусственного интеллекта, позволяя развивать LLM, способные выполнять сложные задачи в практических сценариях с длинным контекстом.
Текущие методы оценки возможностей LLM в длинных контекстах
Текущие методы оценки возможностей LLM в длинных контекстах включают различные бенчмарки и наборы данных, которые тестируют модели на различных длинах токенов. Примеры включают набор данных LongBench, который оценивает двуязычное понимание длинных текстов в задачах от 5 тыс. до 15 тыс. токенов. Однако эти методы имеют ограничения, такие как недостаточная оценка LLM на уровне 1 миллиона токенов и часто фокусируются на одиночных задачах извлечения. Существующие подходы, такие как метод тестирования passkey и тест Needle In A Haystack (NIAH), показали, что некоторые модели могут хорошо справляться с извлечением отдельных кусков информации, но испытывают трудности с более сложными задачами, требующими синтеза нескольких кусков данных. Эти ограничения затрудняют применимость текущих методов для оценки истинного понимания и возможностей рассуждения LLM в реалистичных сценариях с длинным контекстом.
NeedleBench: новая рамка оценки возможностей LLM в длинных контекстах
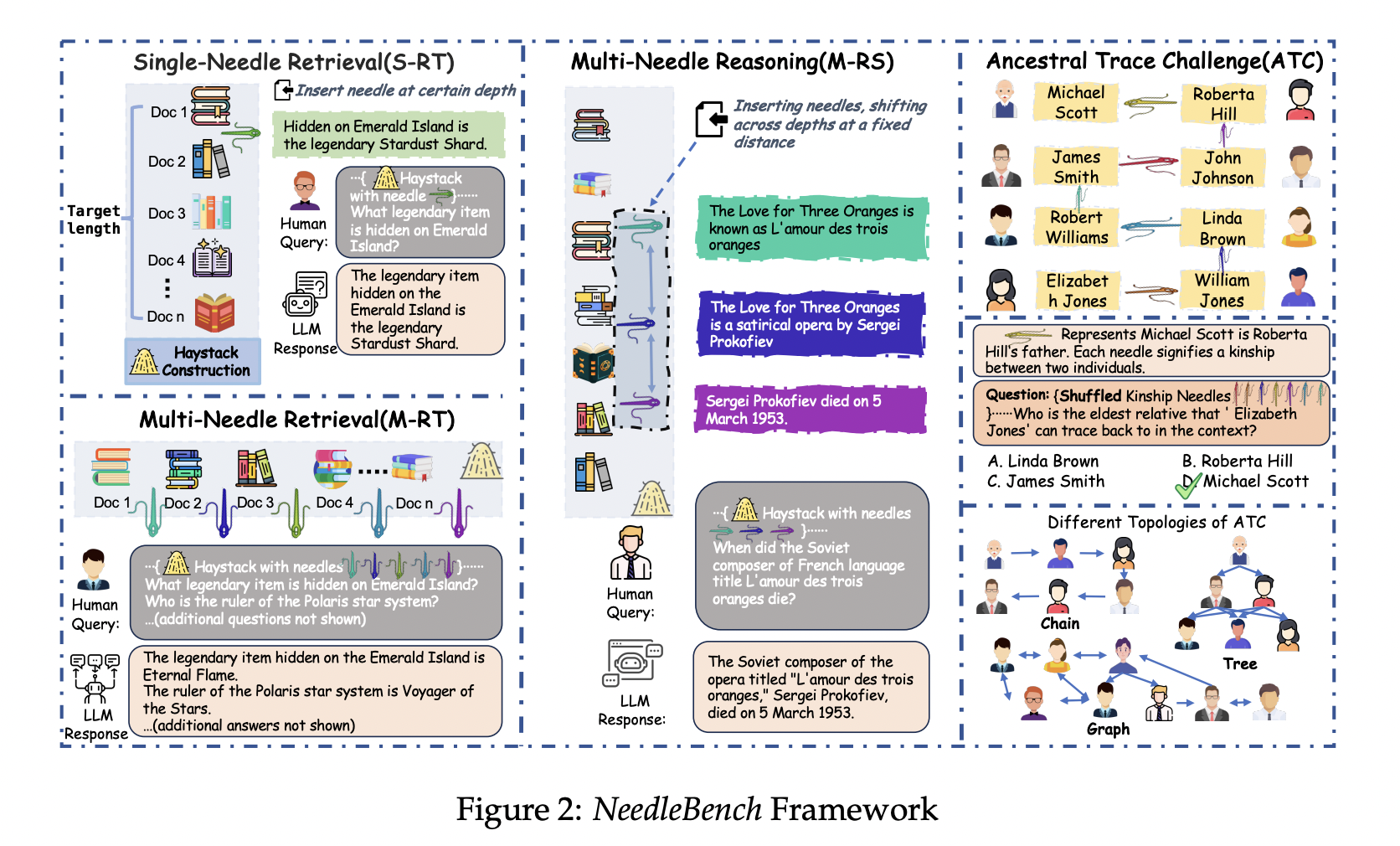
Команда исследователей из Shanghai AI Laboratory и Tsinghua University представляет NeedleBench, новую рамку, разработанную для оценки двуязычных возможностей LLM в длинных контекстах на различных интервалах длин и глубины текста. NeedleBench состоит из прогрессивно более сложных задач, включая задачу извлечения одиночного фрагмента (S-RT), задачу извлечения нескольких фрагментов (M-RT) и задачу многократного рассуждения (M-RS), направленных на обеспечение всесторонней оценки возможностей LLM. Ключевым новшеством является введение вызова Ancestral Trace Challenge (ATC), который имитирует реальные задачи рассуждения в длинных контекстах. ATC тестирует способности моделей решать многократные логические задачи. Этот подход представляет собой значительный вклад в область, предлагая более строгую и реалистичную оценку возможностей LLM в длинных контекстах, устраняя ограничения существующих методов.
Результаты оценки LLM на задачах NeedleBench
Исследователи представляют всесторонние результаты оценки основных открытых LLM на задачах NeedleBench на различных длинах токенов. Ключевые метрики производительности включают точность извлечения для задач извлечения и точность рассуждения для многократных логических задач. Результаты указывают на значительное пространство для улучшения практических применений текущих LLM в длинных контекстах. Например, модель InternLM2-7B-200K достигла идеальных результатов в задачах извлечения одиночного фрагмента, но показала снижение в задачах извлечения нескольких фрагментов из-за переобучения. Исследователи отмечают, что более крупные модели, такие как Qwen-1.5-72B-vLLM, в целом лучше справляются с сложными логическими задачами. Особенно важной является таблица, сравнивающая производительность различных моделей на NeedleBench 32K, показывающая значительные улучшения в точности для предложенного метода по сравнению с существующими базовыми уровнями.
Заключение
NeedleBench предоставляет новую рамку для оценки возможностей LLM в длинных контекстах. Рамка NeedleBench, вместе с вызовом Ancestral Trace Challenge, предлагает всестороннюю оценку способностей моделей решать сложные задачи извлечения и рассуждения в обширных текстах. Вклады являются значительными для продвижения исследований в области искусственного интеллекта, поскольку они решают критическую проблему понимания и рассуждения в длинных контекстах, предлагая более точные и эффективные решения по сравнению с существующими методами. Полученные результаты подчеркивают необходимость дальнейших улучшений в LLM для улучшения их применимости в реальных сценариях с длинным контекстом.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему 46k+ ML SubReddit.
Статья NeedleBench: A Customizable Dataset Framework that Includes Tasks for Evaluating the Bilingual Long-Context Capabilities of LLMs Across Multiple Length Intervals была опубликована на MarkTechPost.
«`















