

«`html
LMMS-EVAL: единый и стандартизированный мультимодальный AI-фреймворк для прозрачной и воспроизводимой оценки
Фундаментальные большие языковые модели (LLM), такие как GPT-4, Gemini и Claude, продемонстрировали заметные возможности, соответствующие или превосходящие человеческую производительность. В этом контексте бенчмарки становятся сложными, но необходимыми инструментами для различения различных моделей и выявления их ограничений.
Проблема оценки моделей
Оценки, которые являются прозрачными, стандартизированными и воспроизводимыми, являются необходимыми, но в настоящее время не существует единой техники для языковых моделей или мультимодальных моделей. Разработчики моделей часто создают индивидуальные техники оценки с различными степенями подготовки данных, постобработки вывода и расчета метрик, что затрудняет прозрачность и воспроизводимость.
Решение проблемы
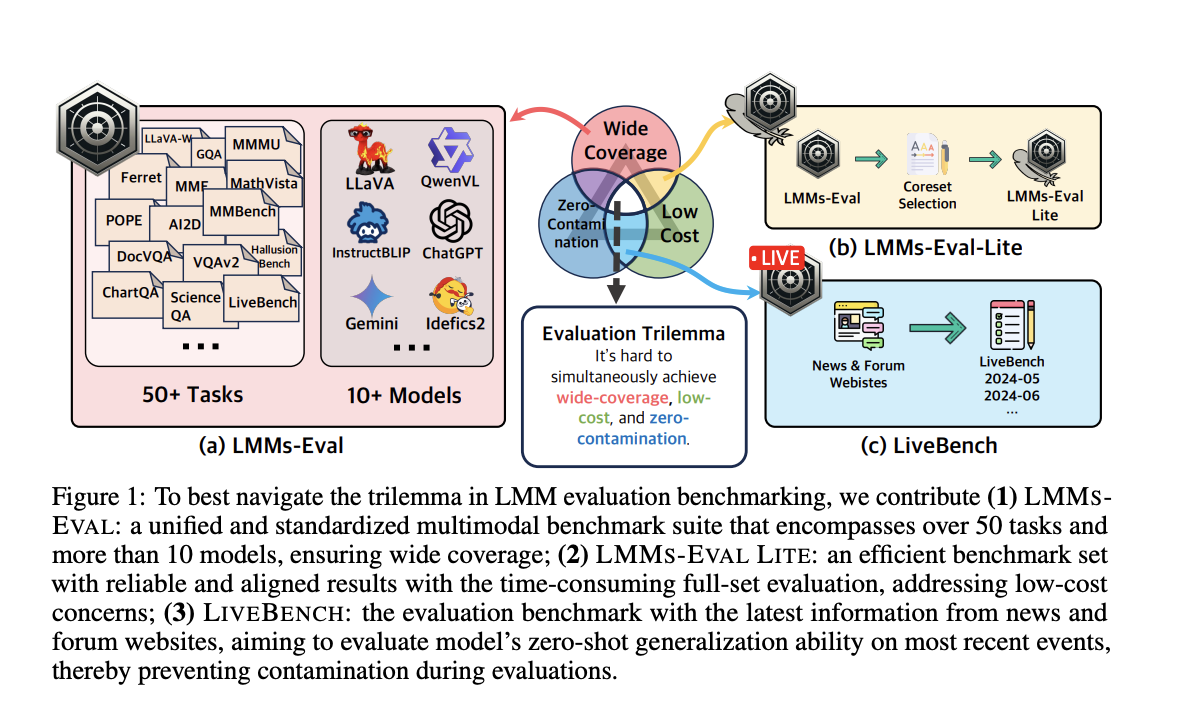
Для решения этой проблемы команда исследователей из LMMs-Lab Team и S-Lab, NTU, Сингапур, создала LMMS-EVAL — стандартизированный и надежный набор бенчмарков, предназначенный для оценки мультимодальных моделей в целом. LMMS-EVAL оценивает более десяти мультимодальных моделей и около 30 вариантов на более чем 50 задачах в различных контекстах. Он имеет унифицированный интерфейс для упрощения интеграции новых моделей и наборов данных, а также предлагает стандартизированный процесс оценки для обеспечения открытости и повторяемости.
Дополнительные решения
Команда также добавила LMMS-EVAL LITE и LiveBench в сцену оценки LMM. LMMS-EVAL LITE сосредотачивается на различных задачах и устраняет избыточные экземпляры данных, предлагая доступную и всестороннюю оценку. LiveBench, в свою очередь, предоставляет дешевый и широко применимый метод проведения бенчмарков путем создания тестовых данных с использованием последней информации из новостей и интернет-форумов.
Основные преимущества
LMMS-EVAL — единый набор оценки мультимодальных моделей, оценивающий более десяти моделей с более чем 30 подвидами и охватывающий более 50 задач. Цель LMMS-EVAL — обеспечить беспристрастные и последовательные сравнения между различными моделями путем упрощения и стандартизации процесса оценки.
Эффективная версия всего набора оценки называется LMMS-EVAL LITE. Устранение бесполезных экземпляров данных снижает расходы, обеспечивая надежные и последовательные результаты с тщательной оценкой LMMS-EVAL. Поскольку LMMS-EVAL LITE сохраняет высокое качество оценки, это доступная альтернатива глубоким оценкам моделей.
Бенчмарк LIVEBENCH оценивает способность моделей к нулевой обобщенности на текущие события, используя актуальные данные из новостных и форумных веб-сайтов. LIVEBENCH предлагает доступный и широко применимый подход к оценке мультимодальных моделей, обеспечивая их непрерывную применимость и точность в постоянно меняющихся реальных ситуациях.
Заключение
Надежные бенчмарки являются неотъемлемыми для развития ИИ. Они предоставляют необходимую информацию для различения моделей, выявления недостатков и направления будущих усовершенствований. Стандартизированные, прозрачные и повторяемые бенчмарки становятся все более важными по мере развития ИИ, особенно в отношении мультимодальных моделей. LMMS-EVAL, LMMS-EVAL LITE и LiveBench призваны закрыть пробелы в существующих системах оценки и способствовать непрерывному развитию ИИ.
Подробнее ознакомьтесь с статьей и GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram-каналу и группе LinkedIn. Если вам нравится наша работа, вам понравится наш рассылка.
Не забудьте присоединиться к нашему 47k+ ML SubReddit.
Найдите предстоящие вебинары по ИИ здесь.
Оригинальная статья опубликована на сайте MarkTechPost.