

«`html
Исследование: Программный фреймворк для количественного анализа проблем эффективности при обслуживании нескольких запросов с длительным контекстом в условиях ограниченной памяти высокой пропускной способности GPU (HBM)
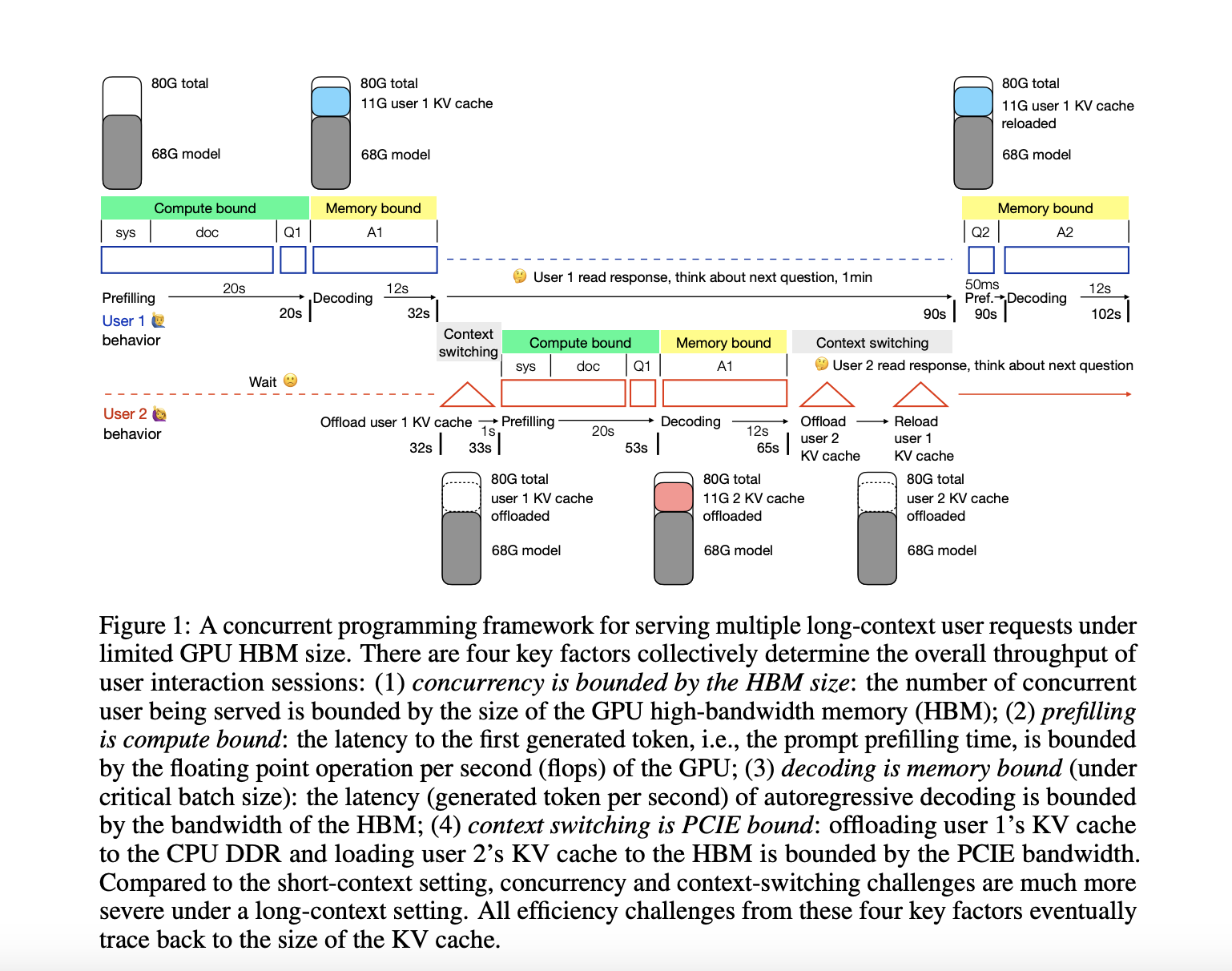
Большие языковые модели (LLM) достигли значительных возможностей, достигнув производительности уровня GPT-4. Однако использование этих моделей для приложений, требующих обширного контекста, таких как кодирование на уровне репозитория и понимание видео продолжительностью в час, представляет существенные вызовы. Для этих задач требуются контексты ввода от 100 тыс. до 10 млн токенов, что значительно превышает стандартный предел в 4 тыс. токенов. Основное препятствие в обслуживании длинных контекстных трансформаторов — размер кэша KV. Например, модель с 30+ млрд параметров и 100 тыс. контекстом требует огромных 22,8 ГБ кэша KV, по сравнению с 0,91 ГБ для контекста в 4 тыс. токенов, что подчеркивает экспоненциальный рост требований к памяти с увеличением длины контекста.
Практические решения:
Для преодоления вызовов обслуживания длинных контекстных трансформаторов исследователь из Университета Эдинбурга разработал параллельную программную среду для количественного анализа проблем эффективности при обслуживании нескольких запросов с длинным контекстом в условиях ограниченной памяти высокой пропускной способности GPU (HBM). Этот фреймворк сосредоточен на модели уровня 34B GPT-3.5 с контекстом в 50 тыс. токенов на графическом процессоре A100 NVLink в качестве примера. Анализ выявляет четыре основных вызова обслуживания, происходящих от большого кэша KV: продленное время предварительной загрузки и использование памяти для длинных входов, ограниченная емкость одновременных пользователей из-за занятости HBM, увеличение задержки декодирования из-за частого доступа к кэшу KV и значительная задержка переключения контекста при замене кэша KV между HBM и памятью DDR. Этот комплексный фреймворк позволяет исследователям оценить существующие решения и исследовать потенциальные комбинации для разработки эффективных систем, способных обрабатывать длинные контекстные языковые модели от начала и до конца.
Значение:
Исследование фокусируется на сжатии кэша KV по четырем измерениям: слой, голова, токен и скрытый. Исследователи предполагают, что для некоторых задач может не потребоваться полноценное вычисление для измерения слоя, что позволяет пропускать слои во время предварительной загрузки. Такой подход потенциально может сократить кэш KV до одного слоя, достигнув коэффициента сжатия 1/60. В измерении головы исследования показывают, что некоторые головы специализируются на извлечении и возможностях длинного контекста. Удерживая только эти важные головы и обрезая другие, можно достичь значительного сжатия. Например, некоторые исследования показывают, что для выполнения задач извлечения может потребоваться всего 20 из 1024 голов.
Сжатие по измерению токена основано на гипотезе, что информацию о токене можно вывести из его контекста, и его можно сжать, отбросив или объединив с соседними токенами. Однако это измерение оказывается менее сжимаемым, чем слои или головы, поскольку большинство работ показывают менее 50% коэффициента сжатия. Скрытое измерение, уже малое на 128, видело ограниченное исследование за пределами техник квантования. Исследователи предлагают, что применение техник сокращения измерений, таких как LoRA, к кэшу KV может привести к дальнейшим улучшениям. Фреймворк также учитывает относительные затраты между предварительной загрузкой и декодированием, отмечая, что по мере увеличения размеров моделей и длины контекста затраты смещаются от декодирования к предварительной загрузке, подчеркивая необходимость оптимизации обоих аспектов для эффективного обслуживания длинных контекстов.
Исследование представляет собой всесторонний анализ вызовов при развертывании длинных контекстных трансформаторов, нацеленный на то, чтобы обслуживание 1 млн контекстов было так же эффективным, как 4 тыс. Эта цель демократизирует передовые приложения ИИ, такие как понимание видео и генеративные агенты. Исследование представляет параллельный программный фреймворк, который разбивает пропускную способность взаимодействия пользователя на четыре ключевых метрики: параллельность, предварительная загрузка, декодирование и переключение контекста. Анализируя, как различные факторы влияют на эти метрики и рассматривая существующие оптимизационные усилия, исследование выделяет значительные возможности для интеграции текущих подходов к разработке надежных систем обслуживания длинных контекстов от начала и до конца. Эта работа заложила основу для оптимизации всего стека в области вывода длинных контекстов.
Подробнее о статье вы можете узнать по ссылке здесь. Все права на это исследование принадлежат его авторам. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам понравилась наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему сообществу более 46 тыс. подписчиков на ML SubReddit.
Статья: A Concurrent Programming Framework for Quantitative Analysis of Efficiency Issues When Serving Multiple Long-Context Requests Under Limited GPU High-Bandwidth Memory (HBM) Regime была опубликована на MarkTechPost.
Применение ИИ в вашем бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте A Concurrent Programming Framework for Quantitative Analysis of Efficiency Issues When Serving Multiple Long-Context Requests Under Limited GPU High-Bandwidth Memory (HBM) Regime .
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot https://itinai.ru/aisales Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!
«`

















