

Самокоррекция в Large Language Models (LLMs): преимущества и практические решения
Суть проблемы
Исследователи изучают, как LLMs могут самостоятельно оценивать и улучшать свои ответы, что делает их более автономными и эффективными в выполнении сложных задач.
Традиционные методы
Существующие методы, такие как Reinforcement Learning from Human Feedback (RLHF) и Direct Preference Optimization (DPO), используют внешних критиков или данные о предпочтениях людей для направления LLMs в улучшении ответов.
Инновационный подход
Используя метод внутриконтекстного выравнивания (ICA), исследователи предложили структурированный процесс, позволяющий LLMs самокритиковаться и улучшать ответы внутри модели.
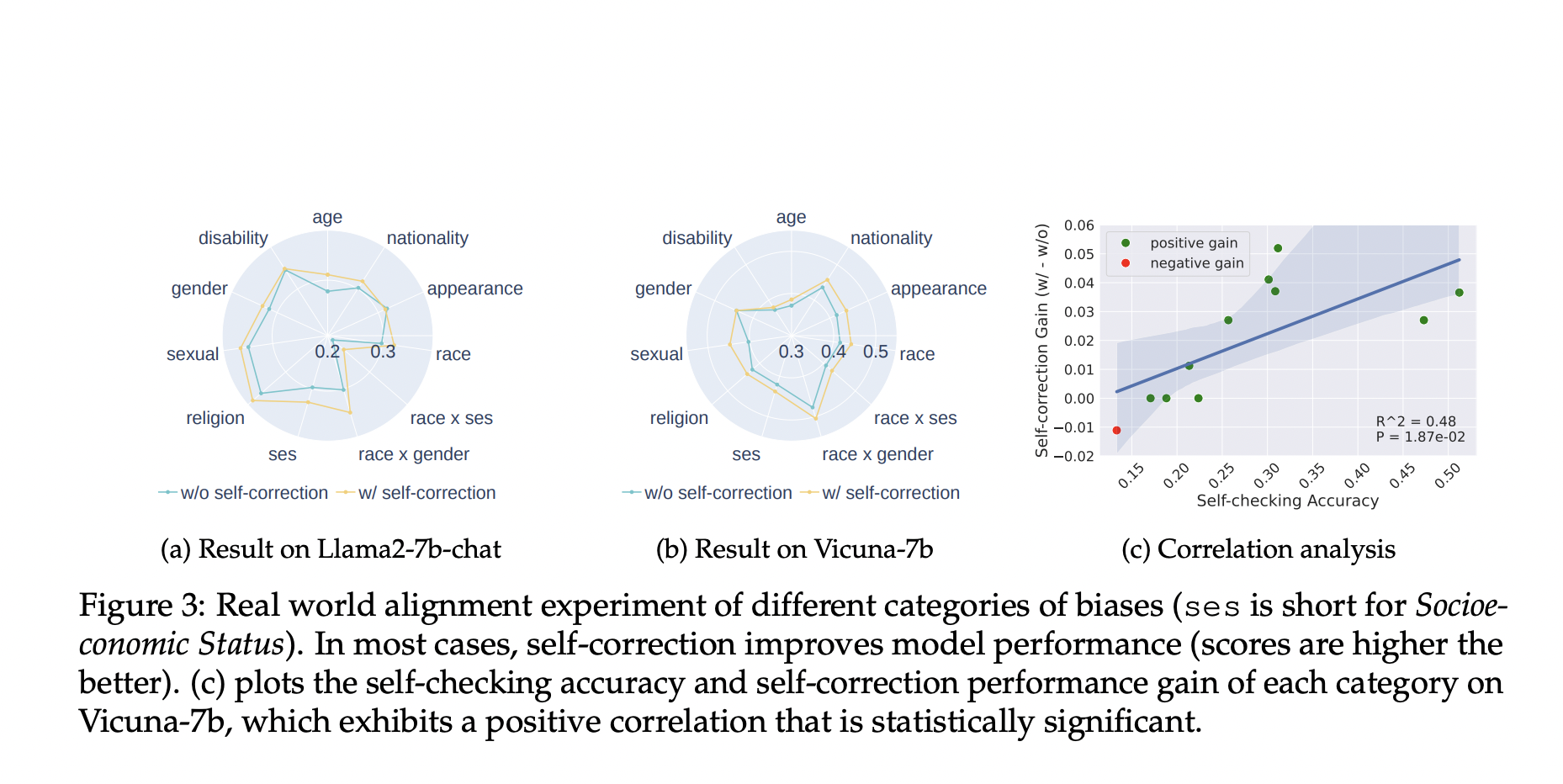
Результаты и применение
Эксперименты показали значительное снижение ошибок и улучшение выравнивания в LLMs, что демонстрирует потенциал для повышения безопасности и надежности в реальных приложениях.
Применение в бизнесе
Используйте AI для улучшения эффективности и автоматизации бизнес-процессов. Начните с малых проектов, анализируйте результаты и постепенно внедряйте ИИ-решения для расширения автоматизации.
Если вам нужна помощь во внедрении ИИ в бизнес, обращайтесь к нам на Telegram. Следите за новостями об ИИ в нашем Телеграм-канале.



















