

«`html
Искусственный интеллект (ИИ) в современных моделях языка
Искусственный интеллект (ИИ) значительно продвинулся с разработкой больших языковых моделей (LLM), которые следуют инструкциям пользователя. Эти модели направлены на предоставление точных и актуальных ответов на запросы людей, часто требуя настройки для улучшения их производительности в различных областях, таких как обслуживание клиентов, поиск информации и генерация контента. Возможность точно инструктировать эти модели стала основополагающей в современном ИИ, расширяя границы того, что эти системы могут достичь в практических сценариях.
Преодоление проблемы длинной ответной информации
Одной из проблем в разработке и оценке моделей, следующих инструкциям, является врожденный длинный биас. Этот биас возникает потому, что человеческие оценщики и алгоритмы обучения предпочитают более длинные ответы, что приводит к созданию моделей, генерирующих излишне длинные выводы. Это предпочтение усложняет оценку качества и эффективности модели, поскольку более длинные ответы иногда бывают более информативными или точными. Следовательно, вызов состоит в разработке моделей, которые понимают инструкции и обеспечивают генерацию ответов соответствующей длины.
Практические методы решения проблемы длинной ответной информации
Текущие методы решения длинного биаса включают в себя внедрение штрафов за длину в оценочные бенчмарки. Например, AlpacaEval и MT-Bench интегрировали эти штрафы, чтобы противодействовать тенденции моделей производить более длинные ответы. Кроме того, различные методы настройки, такие как обучение с подкреплением с обратной связью от человека (RLHF), используются для оптимизации моделей для лучшей следования инструкциям. Эти методы направлены на улучшение способности моделей генерировать краткие, но полные ответы, балансируя длину и качество вывода.
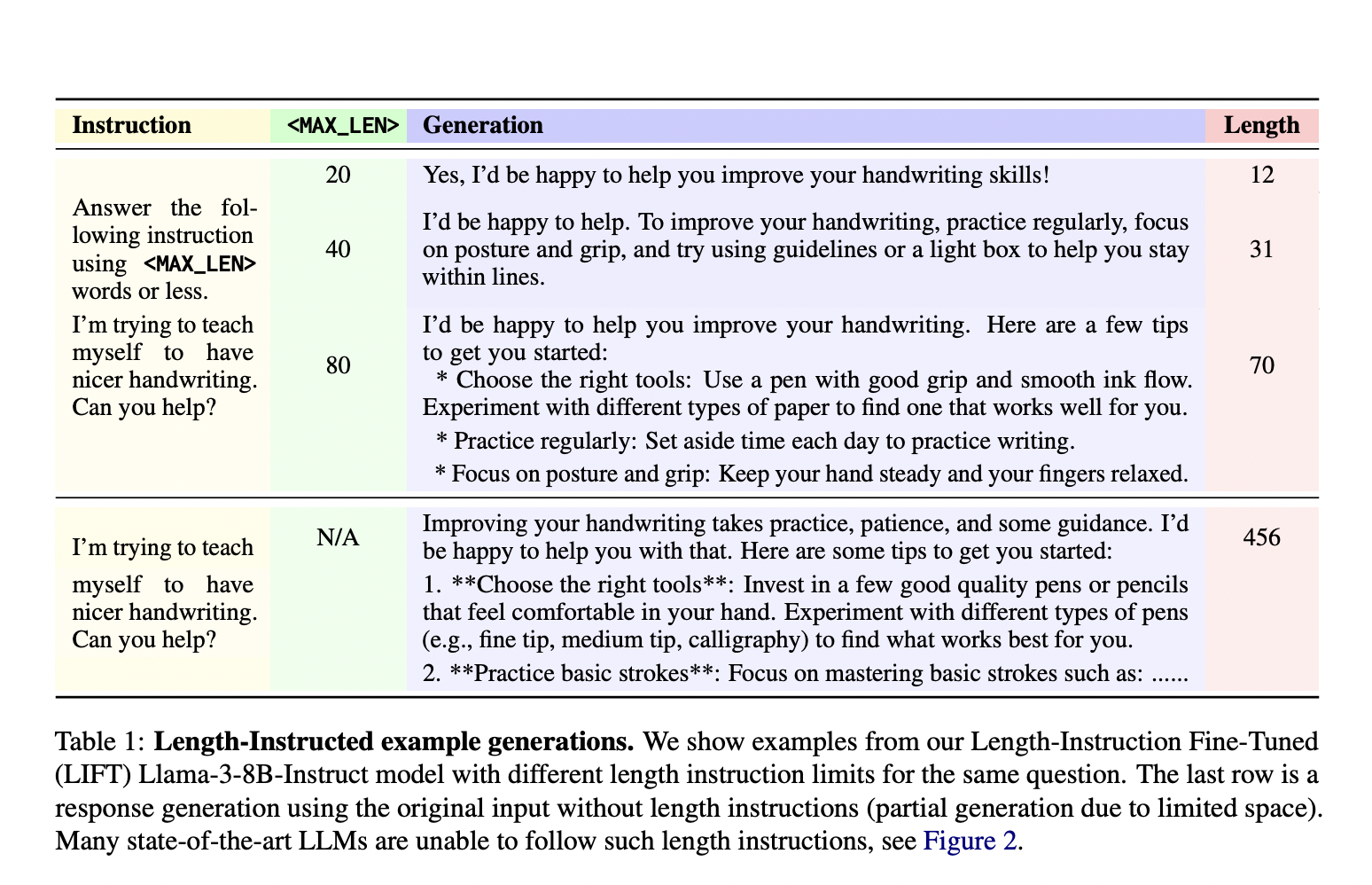
Исследователи из Meta FAIR и Нью-Йоркского университета представили новый подход под названием Length-Instruction Fine-Tuning (LIFT), который включает в себя дополнение обучающих данных явными инструкциями по длине. Этот метод позволяет контролировать модели во время вывода, чтобы соответствовать указанным ограничениям длины. Команда исследователей, включая участников Meta FAIR и Нью-Йоркского университета, разработала этот подход для уменьшения длинного биаса и улучшения следования моделей инструкциям по длине. Модели учатся уважать эти ограничения в реальных приложениях, интегрируя детальные инструкции в обучающие данные.
Метод LIFT включает в себя Direct Preference Optimization (DPO) для настройки моделей с использованием обогащенных инструкциями по длине наборов данных. Этот процесс начинается с дополнения обычного набора данных, следующего инструкциям, путем вставки ограничений длины в подсказки. Метод создает пары предпочтений, отражающие как ограничения длины, так и качество ответа. Эти дополненные наборы данных затем используются для настройки моделей, таких как Llama 2 и Llama 3, обеспечивая их способность обрабатывать подсказки с и без инструкций по длине. Этот систематический подход позволяет моделям учиться на различных инструкциях, улучшая их способность генерировать точные и соответствующие по длине ответы.
Предложенные модели LIFT-DPO продемонстрировали превосходную производительность в соблюдении ограничений длины по сравнению с существующими передовыми моделями, такими как GPT-4 и Llama 3. Например, исследователи обнаружили, что модель GPT-4 Turbo нарушала ограничения длины почти в 50% случаев, подчеркивая значительный недостаток в ее конструкции. В отличие от этого, модели LIFT-DPO проявили значительно более низкие уровни нарушений. В частности, модель Llama-2-70B-Base при стандартном обучении DPO показала уровень нарушений в 65,8% на AlpacaEval-LI, который значительно снизился до 7,1% при обучении LIFT-DPO. Аналогично, уровень нарушений модели Llama-2-70B-Chat снизился с 15,1% при стандартном DPO до 2,7% при LIFT-DPO, демонстрируя эффективность метода в контроле длины ответа.
Более того, модели LIFT-DPO сохраняли высокое качество ответов, соблюдая ограничения длины. Уровни побед значительно улучшились, указывая на то, что модели могут генерировать высококачественные ответы в пределах указанных ограничений длины. Например, уровень побед для модели Llama-2-70B-Base увеличился с 4,6% при стандартном DPO до 13,6% при LIFT-DPO. Эти результаты подчеркивают успех метода в балансировке контроля длины и качества ответа, предоставляя надежное решение для оценки моделей, подверженных длинному биасу.
В заключение, исследование решает проблему длинного биаса в моделях, следующих инструкциям, путем представления метода LIFT. Этот подход улучшает управляемость и качество ответов модели путем интеграции ограничений длины в процесс обучения. Результаты показывают, что модели LIFT-DPO превосходят традиционные методы, предоставляя более надежное и эффективное решение для следования инструкциям с ограничением длины. Сотрудничество между Meta FAIR и Нью-Йоркским университетом значительно улучшило разработку ИИ-моделей, способных генерировать краткие ответы высокого качества, устанавливая новый стандарт для возможностей следования инструкциям в исследованиях по ИИ.
Проверьте статью. Вся заслуга за это исследование принадлежит ученым этого проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему 46k+ ML SubReddit.
The post This AI Paper from NYU and Meta AI Introduces LIFT: Length-Instruction Fine-Tuning for Enhanced Control and Quality in Instruction-Following LLMs appeared first on MarkTechPost.
«`

















![Что такое заказ на покупку и как его создать [с шаблоном]](https://saile.ru/wp-content/uploads/2025/05/itinai.com_IT-company_office_background_blured_-chaos_50_-v_74e4829b-a652-4689-ad2e-c962916303b4_0-200x200.avif)