

«`html
Улучшение языковых моделей и создание разнообразных обучающих наборов данных
Обработка естественного языка значительно улучшила настройку языковых моделей. Однако создание больших и разнообразных наборов данных является сложным и дорогостоящим процессом, требующим значительного человеческого вмешательства. Это создает разрыв между академическим и промышленным применением языковых моделей.
Проблема ручной разметки данных
Ручное создание наборов данных трудоемко и дорого, что ограничивает масштаб и разнообразие создаваемых данных. Исследовательские наборы данных обычно содержат сотни или тысячи образцов, в то время как промышленные наборы данных могут содержать десятки миллионов.
Автоматизация создания наборов данных
Существующие методы решения этой проблемы включают использование больших языковых моделей для изменения и дополнения текстов, написанных людьми. Однако эти методы все еще нуждаются в улучшении масштабируемости и разнообразия.
Инновационное решение от Университета Мэриленда
Исследователи из Университета Мэриленда предложили инновационное решение этой проблемы, представив GenQA. Этот метод использует один хорошо разработанный запрос для автономного создания миллионов разнообразных образцов инструкций. GenQA нацелен на создание масштабных и высокоразнообразных наборов данных, минимизируя человеческое вмешательство.
Технология GenQA
Основная технология GenQA заключается в использовании генераторных запросов для улучшения случайности и разнообразия выводов, создаваемых языковыми моделями. Этот подход значительно снижает необходимость человеческого контроля.
Результаты и потенциал
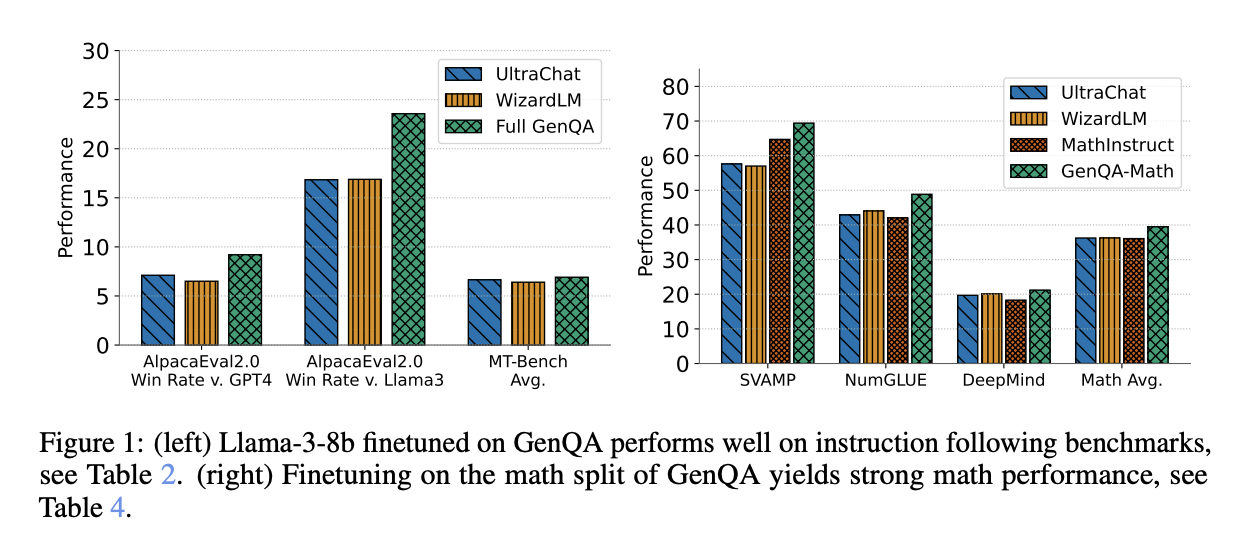
Исследователи протестировали набор данных GenQA, настроив модель Llama-3 8B. Результаты были впечатляющими, показывая превосходство GenQA в сравнении с другими наборами данных.
Заключение
Введение GenQA демонстрирует возможность создания масштабных и разнообразных наборов данных с минимальным человеческим вмешательством. Этот подход снижает затраты и устраняет разрыв между академическим и промышленным применением языковых моделей.
Подробнее о статье и наборе данных.
Вся заслуга за это исследование принадлежит исследователям этого проекта.
Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам понравилась наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему SubReddit.
Источник: MarkTechPost.
«`














![Что такое кросс-продажи: введение, шаги и профессиональные советы [с данными]](https://saile.ru/wp-content/uploads/2025/04/itinai.com_beautiful_Russian_high_fashion_Sales_representativ_07aa490b-7ef7-4dee-b17a-85f8d562fa91_1-200x200.png)




