

«`html
Профессиональные решения в области продаж и маркетинга с учетом технологий искусственного интеллекта
Смешанные архитектуры экспертов (MoE) используют разреженную активацию для масштабирования размеров моделей, сохраняя при этом высокую эффективность обучения и вывода. Тем не менее, обучение сети маршрутизаторов создает вызов оптимизации недифференцируемой, дискретной цели, несмотря на эффективное масштабирование моделей MoE. Недавно была представлена архитектура MoE под названием SMEAR, которая полностью недифференцируема и плавно сливает экспертов в пространстве параметров. SMEAR очень эффективен, но его эффективность ограничена масштабированием на небольших опытах настройки на задачах классификации.
Princeton University и Meta AI представили Lory: полностью дифференцируемую MoE модель, разработанную для предварительной настройки авторегрессивной языковой модели
Разреженные MoE модели стали полезным методом для эффективного масштабирования размеров моделей. Разреженная архитектура MoE адаптирована для моделей трансформаторов для достижения более высокой производительности в машинном переводе. Традиционные модели MoE обучаются направлять входные данные к экспертным модулям, что приводит к недифференцируемой, дискретной проблеме обучения принятия решений. Кроме того, используются стратегии маршрутизации top-1 или top-2 для обучения существующих моделей на основе разработанной цели балансировки нагрузки. Модели MoE сложны в обучении, что создает проблему нестабильности обучения, недостаточной специализации экспертов и неэффективного обучения.
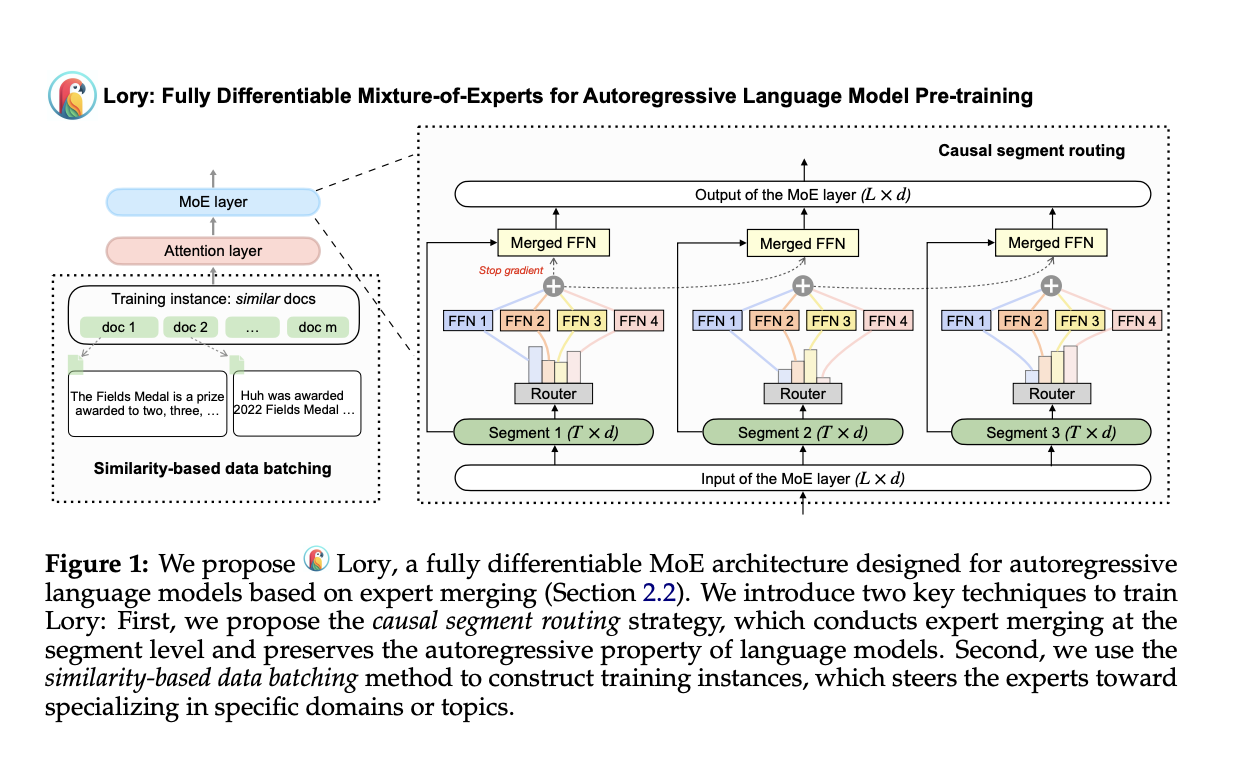
Исследователи из Принстонского университета и Meta AI представили Lory, метод масштабирования архитектур MoE для предварительного обучения авторегрессивной языковой модели. Lory состоит из двух основных техник: (а) стратегии случайной сегментации, эффективной в операциях слияния экспертов, сохраняя авторегрессивную природу языковых моделей, и (б) метода группировки данных на основе сходства, поддерживающего специализацию экспертов путем создания групп для похожих документов во время обучения. Кроме того, Lory превосходит современные модели MoE с помощью маршрутизации на уровне токенов вместо маршрутизации на уровне сегментов.
Сущность первой техники, случайной сегментации, заключается в разделении на более мелкие сегменты с фиксированной длиной для последовательности входных токенов. Оригинальный сегмент используется для получения весов маршрутизатора и оценки слияния эксперта для последующего сегмента. Маршрутизация на уровне сегментов, проводимая с помощью подсказок во время вывода, может привести к недостаточной специализации экспертов из-за объединения текстовых данных для предварительного обучения языковых моделей. Поэтому вторая техника, т.е. метод группировки данных на основе сходства для обучения MoE, преодолевает этот вызов, группируя похожие документы для создания последовательных сегментов. Этот метод используется для обучения языковых моделей, что приводит к эффективному обучению маршрутизации экспертов.
Работа Lory демонстрирует выдающиеся результаты по различным факторам:
- Эффективность обучения и сходимость: Lory достигает эквивалентного уровня потерь при использовании менее половины обучающих токенов для моделей 0,3 млрд и 1,5 млрд, что указывает на лучшую производительность при том же обучающем вычислении.
- Языковое моделирование: Предложенные модели MoE превосходят плотные базовые модели во всех областях, приводя к уменьшению перплексии. Например, по сравнению с плотной моделью 0,3 млрд, модели 0,3 млрд/32E достигают относительного улучшения в 13,9% в разделе книг.
- Задачи на уровне: Модель 0,3 млрд/32E достигает среднего увеличения производительности +3,7% в общем смысле, +3,3% в понимании чтения, +1,5% в понимании чтения и +11,1% в классификации текста.
В заключение, исследователи Принстонского университета и Meta AI предложили Lory, полностью дифференцируемую MoE модель, разработанную для предварительного обучения авторегрессивной языковой модели. Метод Lory превосходит свои плотные аналоги в языковом моделировании и задачах на уровне, а обученные эксперты высоко специализированы и способны улавливать информацию на уровне домена. Будущая работа включает масштабирование Lory и интеграцию маршрутизации на уровне токенов и сегментов путем разработки эффективных методов декодирования для Lory.
Подробнее: Статья. Вся благодарность за это исследование исследователям этого проекта. Также не забудьте подписаться на нас в Twitter. Присоединяйтесь к нашему Telegram-каналу, Discord и группе LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему подразделению ML в Reddit.
Применение искусственного интеллекта для вашего бизнеса
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Researchers from Princeton and Meta AI Introduce ‘Lory’: A Fully-Differentiable MoE Model Designed for Autoregressive Language Model Pre-Training .
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизацию: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на ItinAI Telegram. Следите за новостями о ИИ в нашем Телеграм-канале ItinAI News или в Twitter @itinairu45358.
Попробуйте AI Sales Bot ItinAI. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab ItinAI Lab. Будущее уже здесь!
«`



















