

«`html
Применение обучения с подкреплением в задачах сложного принятия решений
Решение проблемы аллокации ресурсов с помощью моделей RMAB
Применение обучения с подкреплением (RL) в задачах сложного принятия решений, особенно в ситуациях с ограниченными ресурсами и неопределенными результатами, недавно стало очень полезным. В различных областях применения RL, то, что выделяет беспокойных многоруких бандитов (RMABs), — это их решение проблем аллокации ресурсов многих агентов. Модели RMAB изображают управление несколькими точками принятия решений или «руками», каждая из которых требует тщательного выбора для максимизации накопленных вознаграждений в конце каждой.
Такие модели были инструментальны в таких областях, как здравоохранение, где они оптимизируют поток медицинских ресурсов; онлайн-реклама, где они улучшают эффективность стратегий таргетинга; и охрана природы, где они информируют операции по борьбе с браконьерством. Однако некоторые проблемы остаются при применении RMABs в реальной жизни.
Решение систематических ошибок данных с помощью вариантов глубоких RL техник
Систематические ошибки данных являются одной из основных проблем, влияющих на эффективную реализацию RMAB. Эти ошибки могут возникать из-за несогласованных протоколов сбора данных в различных географических областях, добавления шума для дифференциальной конфиденциальности или изменений в процедурах обработки. Врожденные ошибки, подобные этим, приводят к неправильной оценке вознаграждений и, следовательно, могут привести к неоптимальным решениям со стороны RMAB. Например, был случай завышения ожидаемой даты поставки в сфере здравоохранения матери, где несогласованные методы сбора данных привели к аллокации ресурсов и снижению родов в медицинских учреждениях. Эти ошибки становятся особенно губительными, когда они затрагивают только некоторые точки принятия решений — так называемые «шумные руки» — в модели RMAB.
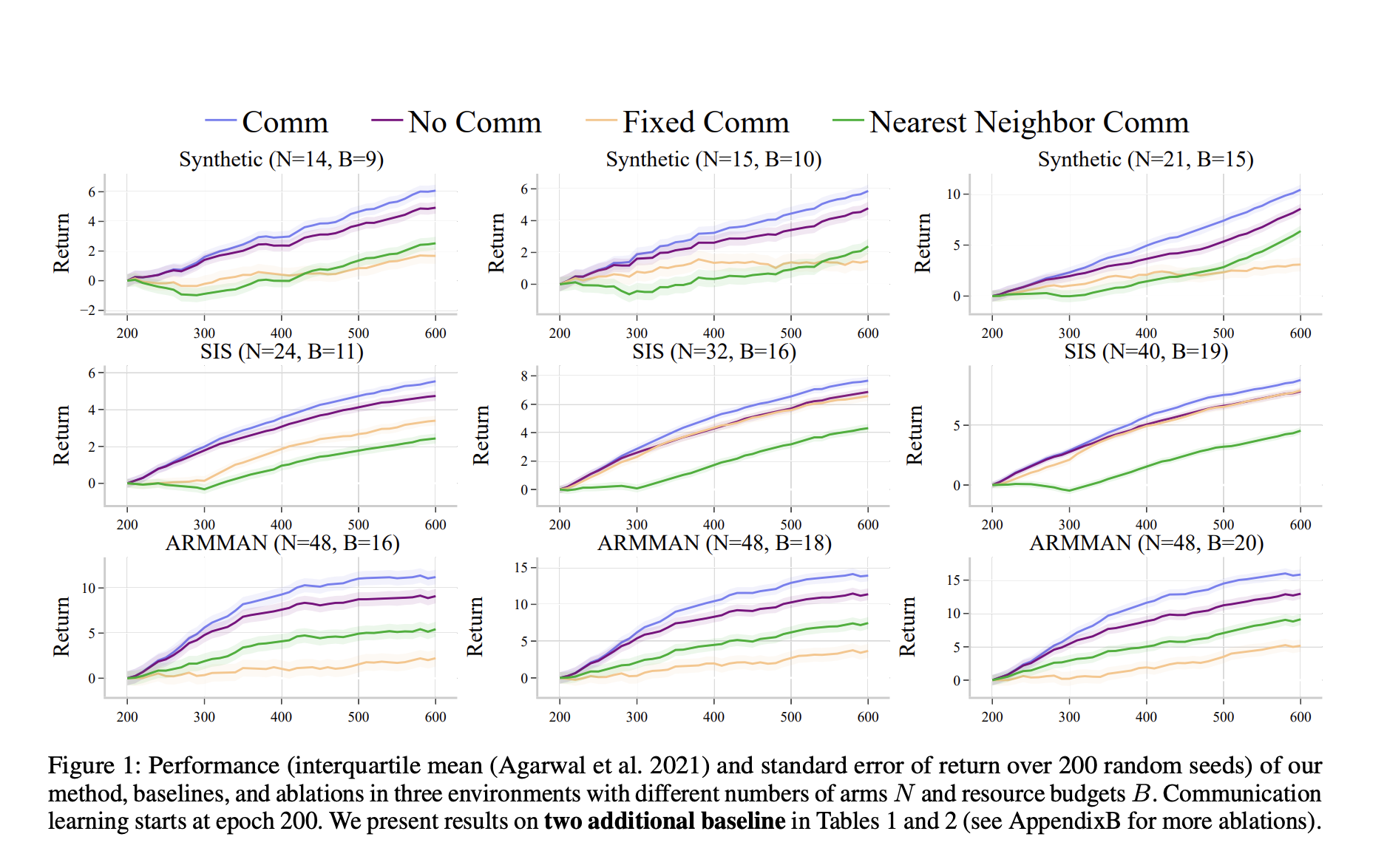
Новый подход к обучению через коммуникацию для улучшения принятия решений в шумных RMAB
Исследователи из Гарвардского университета и Google предложили новую парадигму обучения в рамках RMABs: коммуникацию. Обмен информацией между многими руками RMAB позволяет им помогать друг другу корректировать систематические ошибки в данных, тем самым улучшая качество принятия решений. Предложенный метод был протестирован в широком спектре сред, от синтетических сред до сценариев материнского здравоохранения и моделей борьбы с эпидемиями, что подтверждает применимость этого метода во многих областях.
Эмпирические тесты нового подхода к обучению через коммуникацию
Исследователи провели обширные эмпирические тесты, сравнивая производительность предложенного метода обучения через коммуникацию с базовыми методами. Результаты показывают, что этот подход не только превосходит существующие методы, но также обладает большей устойчивостью и адаптивностью к реальным вызовам.
Заключение
Исследование представляет новаторский алгоритм обучения через коммуникацию, который значительно улучшает производительность RMABs в шумных средах. Предложенный метод позволяет рукам обмениваться параметрами функции Q и учиться на опыте друг друга, эффективно уменьшая влияние систематических ошибок данных и улучшая общую эффективность принятия решений об аллокации ресурсов.