

«`html
Обеспечение безопасности и этического поведения в больших языковых моделях (LLM)
Гарантировать безопасность и этическое поведение больших языковых моделей (LLM) при ответе на запросы пользователей — это крайне важно. Проблемы возникают из-за того, что LLM созданы для генерации текста на основе ввода пользователя, что иногда может привести к вредному или оскорбительному контенту. Эта статья исследует механизмы, с помощью которых LLM отказываются генерировать определенные типы контента, и разрабатывает методы для улучшения их способностей к отказу.
Метод ортогонализации весов
Предложенное решение исследователей из ETH Zürich, Anthropic, MIT и других включает новый подход, называемый «ортогонализацией весов», который устраняет направление отказа в весах модели. Этот метод призван сделать отказ более надежным и сложным для обхода.
Преимущества метода
Техника ортогонализации весов проще и эффективнее существующих методов, поскольку не требует оптимизации на основе градиентов или набора вредоносных завершений. Она заключается в корректировке весов в модели таким образом, чтобы направление, связанное с отказом, было ортогонализировано, предотвращая модели следовать указаниям отказа, сохраняя при этом ее исходные возможности.
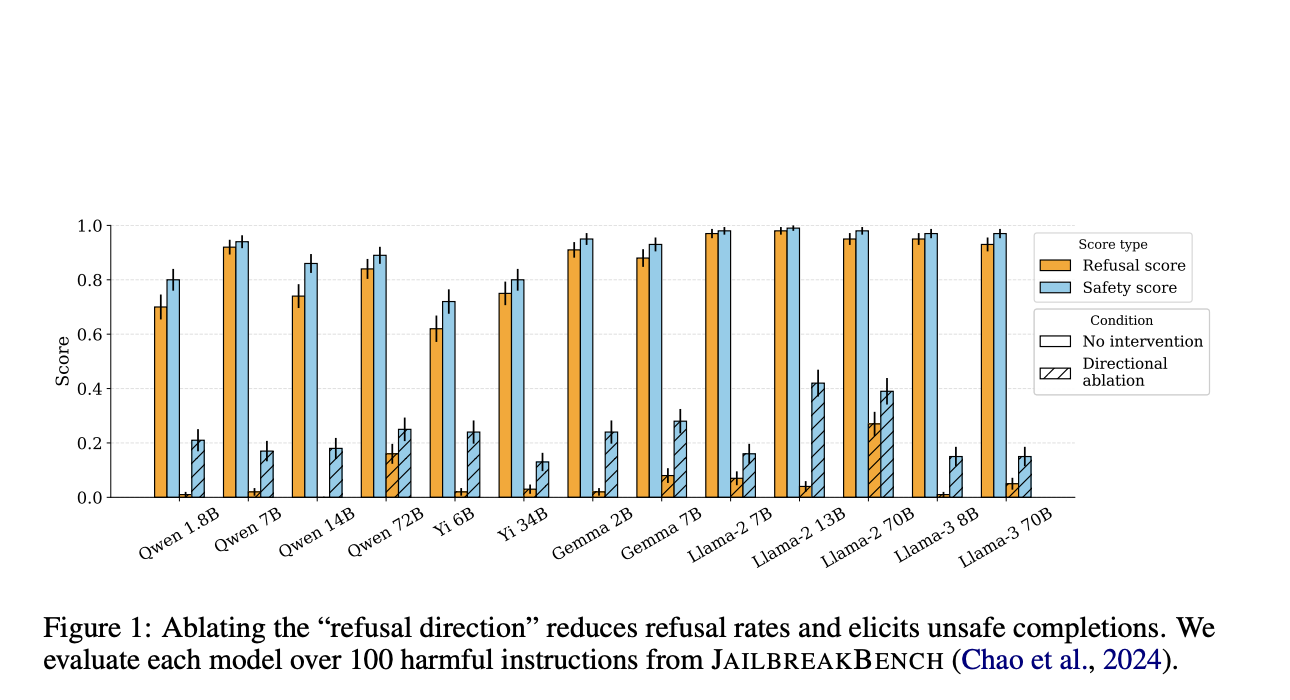
Оценка производительности
Эксперименты с использованием тестового набора HARMBENCH показывают, что метод ортогонализации весов демонстрирует высокий уровень успешности атаки (ASR) на различных моделях, включая семейства LLAMA-2 и QWEN, даже если системные запросы разработаны для обеспечения безопасности и этических принципов.
Этические соображения
Предложенный метод значительно упрощает процесс обхода защиты LLM, однако он также вызывает важные этические вопросы. Исследователи признают, что этот метод немного снижает барьер для обхода защиты моделей с открытым исходным кодом, потенциально способствуя злоупотреблению. Однако они утверждают, что это не существенно изменяет риск открытия моделей. Работа подчеркивает хрупкость текущих механизмов безопасности и призывает к научному консенсусу относительно ограничений этих методов для информирования будущих решений в области политики и исследований.
Заключение
Это исследование выявляет критическую уязвимость в механизмах безопасности LLM и представляет эффективный метод для эксплуатации этой слабости. Исследователи демонстрируют простую, но мощную технику обхода механизмов отказа путем ортогонализации направления отказа в весах модели. Эта работа не только продвигает понимание уязвимостей LLM, но также подчеркивает необходимость надежных и эффективных механизмов безопасности для предотвращения злоупотребления.
Проверьте статью и GitHub. Вся заслуга за это исследование принадлежит его ученым. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе LinkedIn.
Если вам нравится наша работа, вам понравится наш рассылка.
Не забудьте присоединиться к нашему 45k+ ML SubReddit.
Источник: MarkTechPost.
«`



















