

«`html
Large Language Models’ Multi-Step Reasoning Capabilities Enhanced by Q*
Большие языковые модели (LLM) продемонстрировали выдающиеся способности в решении различных задач рассуждения, выраженных естественным языком, включая математические задачи, генерацию кода и планирование. Однако, по мере увеличения сложности задач рассуждения, даже самые передовые LLM сталкиваются с ошибками, галлюцинациями и несогласованностями из-за их авторегрессивной природы. Эта проблема особенно заметна в задачах, требующих нескольких этапов рассуждения, где «Система 1» мышления LLM – быстрое и инстинктивное, но менее точное – оказывается недостаточным. Необходимость более обдуманного и логического «Система 2» мышления становится критической для точного и последовательного решения сложных задач рассуждения.
Преодоление вызовов при помощи Q*
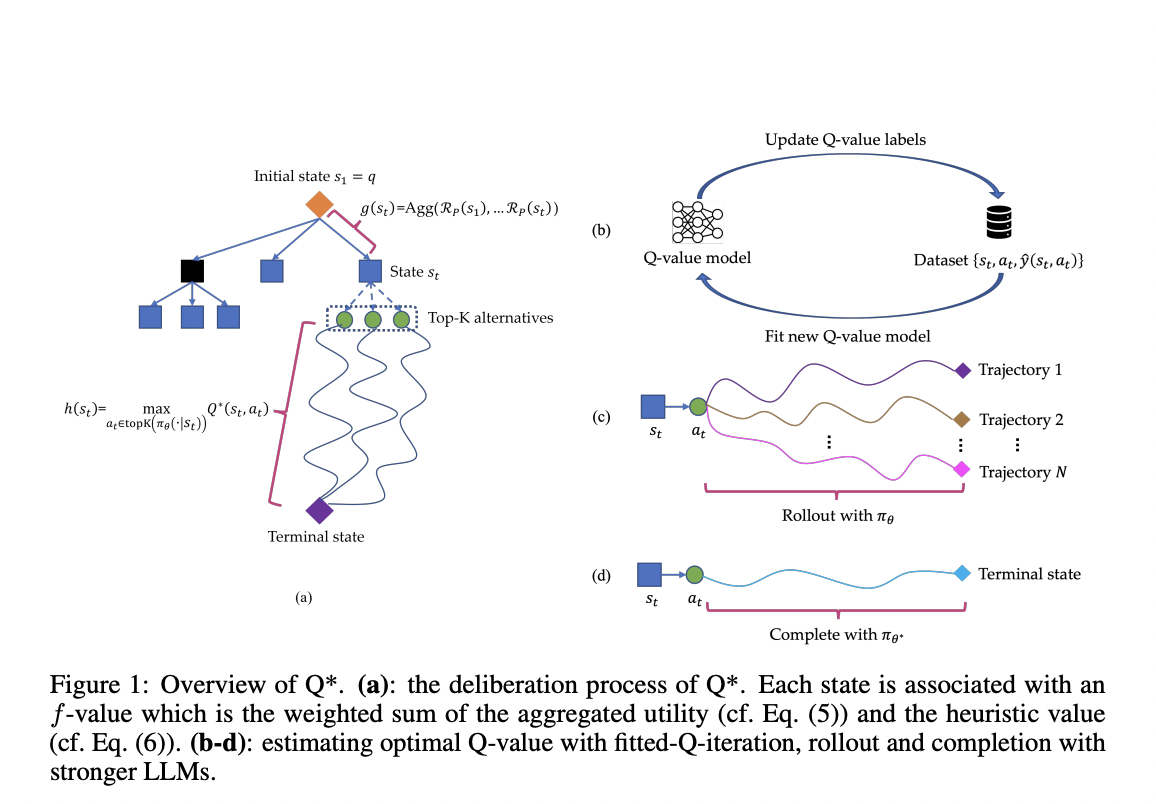
Исследователи из Skywork AI и Наньянгского технологического университета представляют Q*, устойчивую структуру, разработанную для улучшения многоэтапных рассуждений LLM через обдуманное планирование. Этот подход формализует рассуждение LLM в виде процесса принятия решений Маркова (MDP), где состояние объединяет входное подсказка и предыдущие этапы рассуждения, действие представляет следующий шаг рассуждения, а вознаграждение измеряет успех задачи. Q* вводит общие методы для оценки оптимальных Q-значений пар состояние-действие, включая оффлайн обучение с подкреплением, выбор лучшей последовательности из проходов и завершение с использованием более мощных LLM. Формализуя многоэтапное рассуждение как проблему эвристического поиска, Q* использует модели Q-значений «plug-and-play» в качестве функций эвристики в рамках алгоритма A* поиска, направляя LLM наиболее перспективными следующими шагами эффективно.
Эффективность Q* в практическом применении
Q* продемонстрировал значительное улучшение производительности при решении различных задач рассуждения. На наборе данных GSM8K он улучшил Llama-2-7b, достигнув точности 80,8%, превзойдя ChatGPT-turbo. Для набора данных MATH Q* улучшил Llama-2-7b и DeepSeekMath-7b, достигнув точности 55,4% и превзойдя модели, такие как Gemini Ultra (4-shot). В генерации кода Q* повысил точность модели CodeQwen1.5-7b-Chat до 77,0% на наборе данных MBPP. Эти результаты последовательно показывают эффективность Q* в повышении производительности LLM при решении задач математического рассуждения и генерации кода, превзойдя традиционные методы и некоторые закрытые модели.
Q* представляет собой эффективный метод преодоления вызовов многоэтапного рассуждения в LLM путем внедрения надежной структуры обдуманного планирования. Этот подход улучшает способности LLM решать сложные задачи, требующие глубокого, логического мышления, превышая простую авторегрессивную генерацию токенов. В отличие от предыдущих методов, использующих задаче-специфические функции полезности, Q* использует универсальную модель Q-значений, обученную исключительно на данных с истиной, что делает его легко адаптируемым к различным задачам рассуждения без модификаций. Структура Q* использует модели Q-значений «plug-and-play» в качестве функций эвристики, направляя LLM эффективно без необходимости задаче-специфической настройки, сохраняя производительность при разнообразных задачах. Гибкость Q* происходит от его подхода одноэтапного рассмотрения, в отличие от более ресурсоемких методов, таких как MCTS. Обширные эксперименты в области математического рассуждения и генерации кода демонстрируют превосходную производительность Q*, выявляя его потенциал для значительного улучшения способностей LLM в решении сложных проблем.
Познакомьтесь с исследованием. Вся честь за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему каналу Telegram и группе в LinkedIn.
Если вам нравится наша работа, вы полюбите нашу рассылку.
Не забудьте присоединиться к нашему сообществу ML, у нас уже есть более 45 тыс. подписчиков в ML SubReddit.
«`
















![13 способов, как ИИ может помочь вашему бизнесу [+ новые данные и подсказки по генеративному ИИ]](https://saile.ru/wp-content/uploads/2025/04/itinai.com_beautiful_Russian_high_fashion_Sales_representativ_a1922e6e-86c0-4f4f-ace3-d2864b5eacac_0-200x200.png)

