

«`html
Использование PAL для оптимизации производительности в машинном обучении на GPU
Исследователи из Университета Висконсин-Мэдисон рассмотрели проблему изменчивости производительности в рабочих нагрузках машинного обучения (ML), ускоренных с помощью графических процессоров (GPU) в крупных вычислительных кластерах. Изменчивость производительности в этих средах возникает из-за нескольких факторов, включая аппаратную неоднородность, оптимизацию программного обеспечения и зависимость алгоритмов ML от данных. Эта изменчивость может привести к неэффективному использованию ресурсов, непредсказуемому времени завершения задач и снижению общей производительности кластера, что затрудняет эффективную оптимизацию кластеров с большим количеством GPU для рабочих нагрузок ML.
Проблема существующих планировщиков кластеров
Текущие планировщики кластеров, такие как SLURM и Kubernetes, разработаны для управления и выделения ресурсов в кластерах. Однако эти методы часто не справляются с изменчивостью производительности, присущей рабочим нагрузкам ML. Они обычно не учитывают колебания производительности, вызванные аппаратными и рабочими факторами, что приводит к неоптимальному распределению ресурсов и неэффективности.
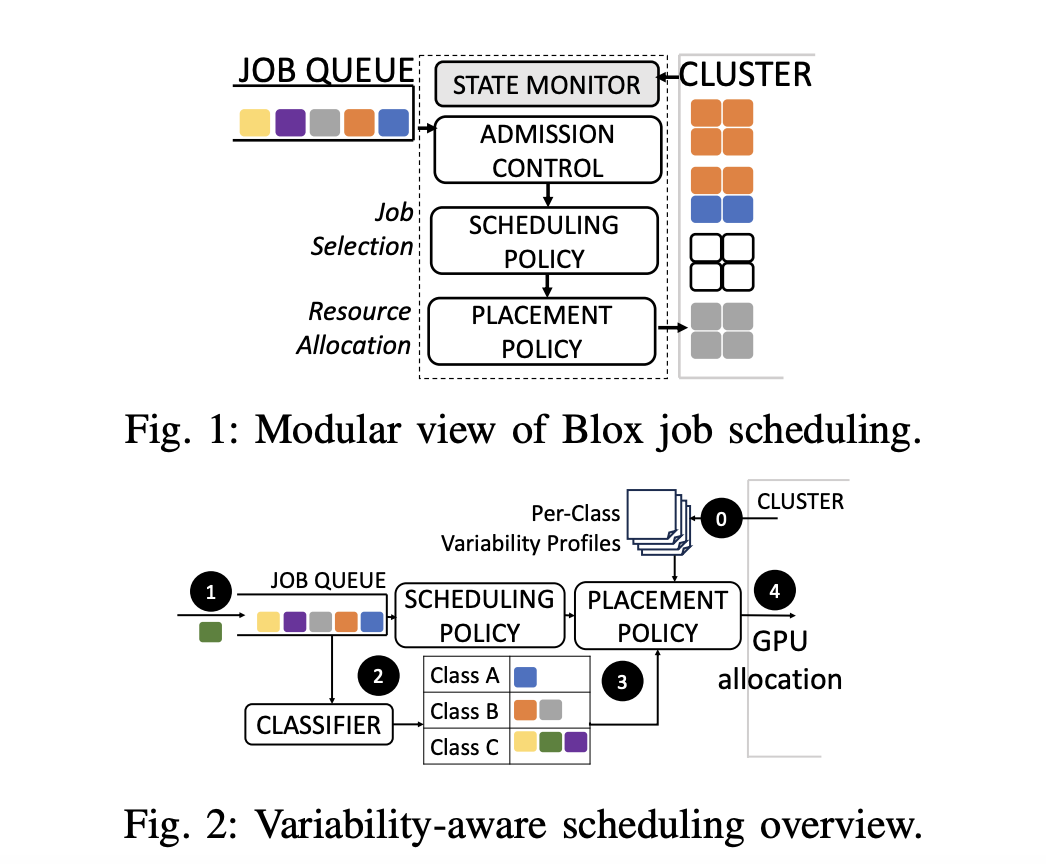
Решение: планировщик PAL
Исследователи предлагают новый планировщик под названием PAL (Performance-Aware Learning). PAL разработан для учета и смягчения влияния изменчивости производительности в кластерах с большим количеством GPU. Основное преимущество PAL заключается в его способности профилировать как задачи, так и узлы, что позволяет ему принимать обоснованные решения о планировании, учитывая изменчивость производительности. PAL направлен на улучшение времени завершения задач, использования ресурсов и общей эффективности кластера.
Эксперименты и результаты
Были проведены эксперименты для тестирования PAL на различных рабочих нагрузках ML, включая модели изображений, языка и видения. Результаты показали, что PAL значительно превосходит существующие планировщики, достигая улучшения времени завершения задач на 42%, увеличения использования кластера на 28% и сокращения времени выполнения на 47%. Эти улучшения подчеркивают эффективность PAL в смягчении изменчивости производительности и оптимизации планирования кластеров с большим количеством GPU.
Заключение
PAL представляет собой значительный прогресс в учете изменчивости производительности в рабочих нагрузках ML, ускоренных с помощью GPU. Путем использования детального профилирования производительности и адаптивного планирования PAL эффективно сокращает время завершения задач, улучшает использование ресурсов и общую производительность кластера. Это делает PAL ценным инструментом для оптимизации крупных вычислительных систем, особенно тех, которые все больше полагаются на GPU для ML и научных приложений.
Подробнее о статье можно узнать здесь.
«`

















