

«`html
FlashSigmoid: новый подход к механизмам внимания
Большие языковые модели (LLM) приобрели значительное значение в современном машинном обучении, в основном благодаря механизму внимания. Этот механизм использует отображение последовательности-в-последовательность для создания контекстно-ориентированных токенов. Традиционно внимание основано на функции softmax (SoftmaxAttn) для генерации токенов как зависимые от данных выпуклые комбинации значений. Однако, несмотря на широкое применение и эффективность, SoftmaxAttn сталкивается с несколькими проблемами. Одна из ключевых проблем — склонность функции softmax сосредотачивать внимание на ограниченное количество признаков, возможно, упуская другие информативные аспекты входных данных. Также применение SoftmaxAttn требует уменьшения по строкам вдоль длины входной последовательности, что может значительно замедлить вычисления, особенно при использовании эффективных ядер внимания.
Альтернативы функции softmax в машинном обучении
Недавние исследования в машинном обучении исследовали альтернативы традиционной функции softmax в различных областях. В неконтролируемом обучении классификации изображений и самоконтролируемом обучении существует тенденция использования более богатых покомпонентных условных распределений Бернулли, параметризованных сигмоидными функциями, в отличие от условных категориальных распределений, обычно параметризованных softmax. Некоторые исследования рассматривали замену softmax активацией ReLU как в практических, так и в теоретических контекстах. Другие исследования включают использование активации ReLU2, чисто линейного внимания и механизмов внимания на основе косинусной схожести. Заметным подходом было масштабирование различных функций активации на n^(-α), где n — длина последовательности, а α — гиперпараметр, для замены softmax. Однако этот метод столкнулся с проблемами производительности без должной инициализации и использования LayerScale. Эти разнообразные подходы направлены на преодоление ограничений внимания, основанного на softmax, и поиск более эффективных альтернатив для контекстно-ориентированного представления токенов.
Новый подход к механизмам внимания от исследователей Apple
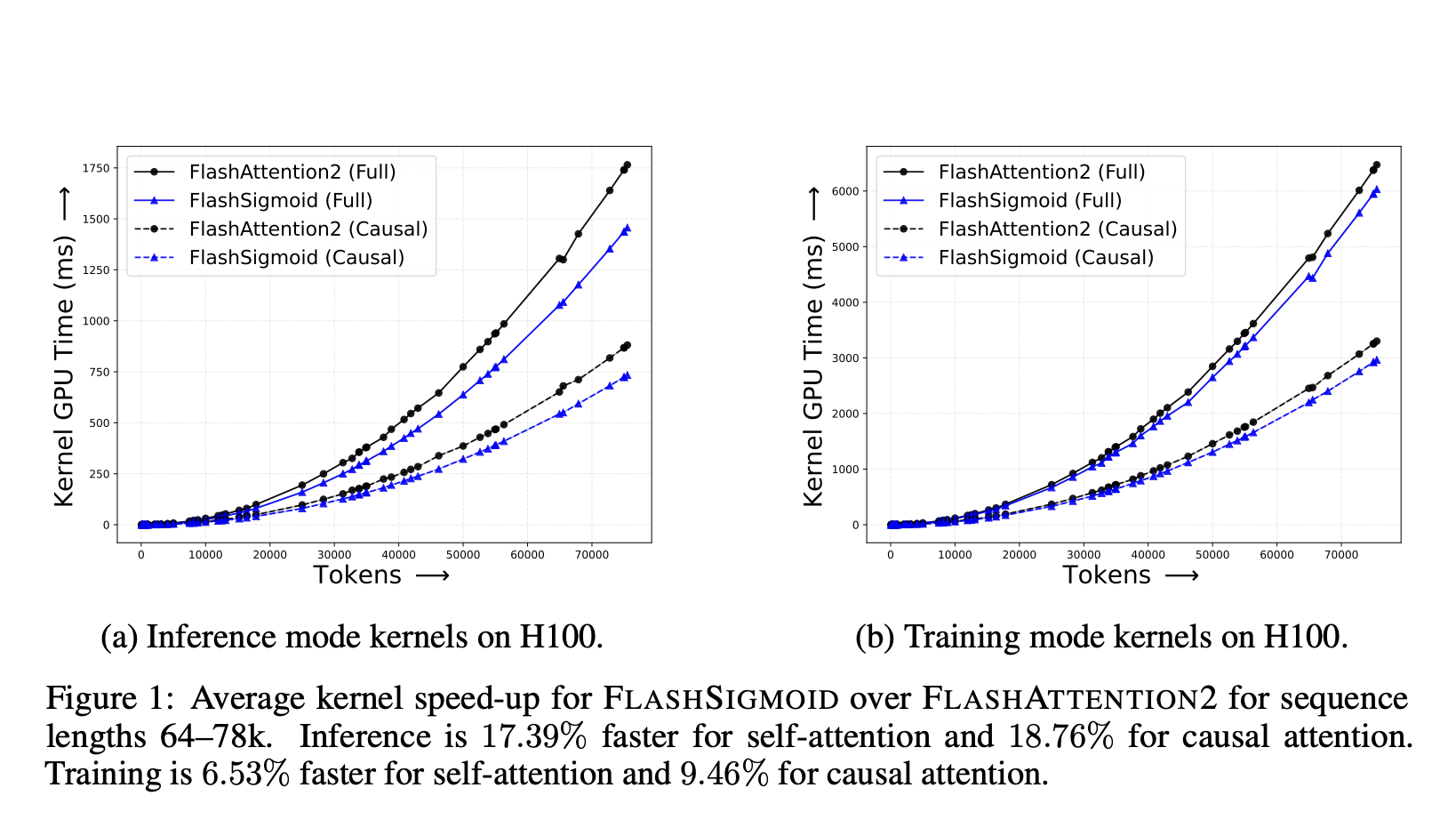
Исследователи из Apple представили надежный подход к механизмам внимания, заменив операцию softmax по строкам на покомпонентную сигмоидную нелинейность. Они выявили, что основной проблемой с наивным сигмоидным вниманием (SigmoidAttn) являются большие начальные нормы внимания. Для решения этой проблемы они предлагают несколько решений и вносят значительный вклад в область. Во-первых, они демонстрируют, что SigmoidAttn является универсальным аппроксиматором функций для задач последовательность-в-последовательность. Во-вторых, они проводят анализ регулярности SigmoidAttn и устанавливают его верхнюю границу Якобиана в худшем случае. В-третьих, они улучшают алгоритм FLASHATTENTION2 с сигмоидным ядром, что приводит к существенному снижению времени вывода ядра и реального времени вывода. Наконец, они показывают, что SigmoidAttn проявляет себя сравнимо с SoftmaxAttn в различных задачах и областях, подчеркивая его потенциал как жизнеспособной альтернативы в механизмах внимания.
Анализ SigmoidAttn
Предложенная альтернатива традиционному вниманию softmax анализируется с двух ключевых точек зрения. Во-первых, исследователи демонстрируют, что трансформеры с использованием SigmoidAttn сохраняют универсальное свойство аппроксимации (UAP), обеспечивая их способность аппроксимировать непрерывные функции последовательность-в-последовательность с произвольной точностью. Это свойство важно для сохранения обобщаемости архитектуры и ее возможности представления. Доказательство адаптирует рамки, используемые для классических трансформеров, с ключевыми модификациями для адаптации сигмоидной функции. Следует отметить, что для аппроксимации необходимой селективной операции сдвига SigmoidAttn требует как минимум четыре внимательных головы и изменений как в определениях запроса, так и ключа, в отличие от требования внимания softmax двух голов и сдвигов только в определении запроса.
Во-вторых, исследование рассматривает регулярность SigmoidAttn путем вычисления его константы Липшица. Анализ показывает, что локальная константа Липшица SigmoidAttn значительно ниже, чем в худшем случае для внимания softmax. Это означает, что SigmoidAttn обладает лучшей регулярностью, что потенциально приводит к улучшению устойчивости и упрощению оптимизации в нейронных сетях. Граница для SigmoidAttn зависит от среднего квадрата нормы входной последовательности, а не от наибольшего значения, что позволяет применять ее к неограниченным распределениям с ограниченными вторыми моментами.
Результаты исследований
Обширные оценки SigmoidAttn в различных областях подтверждают его эффективность. Они включают контролируемую классификацию изображений с использованием vision transformers, самоконтролируемое обучение представления изображений с методами, такими как SimCLR, BYOL и MAE, а также автоматическое распознавание речи (ASR) и авторегрессионное языковое моделирование (LM). Также были проведены тесты обобщения длины последовательности на TED-LIUM v3 для ASR и в масштабных синтетических экспериментах.
Результаты показывают, что SigmoidAttn последовательно соответствует производительности SoftmaxAttn во всех протестированных областях и алгоритмах. Это достигается при улучшении скорости обучения и вывода, как подробно описано в предыдущих разделах. Ключевые наблюдения из эмпирических исследований включают:
- Для задач видения SigmoidAttn доказывает свою эффективность без необходимости в параметре смещения, за исключением случая MAE. Однако для достижения производительности, сравнимой с SoftmaxAttn, требуется использование LayerScale без гиперпараметров.
- Для языкового моделирования и задач ASR производительность чувствительна к начальной норме вывода внимания. Для решения этой проблемы необходима модуляция через относительные позиционные вложения, такие как ALiBi, которые сдвигают массу логитов к нулевому режиму под SigmoidAttn, или подходящая инициализация параметра b для достижения аналогичного эффекта.
Эти результаты свидетельствуют о том, что SigmoidAttn является жизнеспособной альтернативой SoftmaxAttn, предлагая сопоставимую производительность в широком диапазоне приложений, а также потенциальные вычислительные преимущества.
Заключение
Это исследование представляет собой всесторонний анализ сигмоидного внимания как потенциальной замены внимания softmax в архитектурах трансформеров. Исследователи предоставляют как теоретические основы, так и эмпирические доказательства в поддержку жизнеспособности этого альтернативного подхода. Они демонстрируют, что трансформеры, использующие сигмоидное внимание, сохраняют важное свойство универсального аппроксиматора функций, а также обладают улучшенной регулярностью по сравнению с их аналогами на основе softmax. Исследование выделяет два ключевых фактора для успешной реализации сигмоидного внимания: использование LayerScale и предотвращение больших начальных норм внимания. Эти идеи способствуют установлению лучших практик для применения сигмоидного внимания в моделях трансформеров. Также исследователи представляют FLASHSIGMOID, эффективный вариант сигмоидного внимания, который обеспечивает значительное ускорение работы ядра вывода на 17%. Обширные эксперименты, проведенные в различных областях, включая обработку языка, компьютерное зрение и распознавание речи, показывают, что правильно нормализованное сигмоидное внимание последовательно соответствует производительности внимания softmax в различных задачах и масштабах.