

«`html
Мамба-2 и Фреймворк Двойственного Пространства Состояний для Эффективного Языкового Моделирования
Машинное обучение продолжает развиваться, и архитектура Трансформер становится доминирующей в моделировании языка. Новые модели революционизировали обработку естественного языка, позволяя машинам точно понимать и генерировать человеческий язык. Однако эффективность и масштабируемость этих моделей остаются значительной проблемой, особенно из-за квадратичной зависимости традиционных механизмов внимания от длины последовательности. Исследователи стремятся решить эту проблему, исследуя альтернативные методы для сохранения производительности и повышения эффективности.
Решение:
Применение структурированных моделей пространства состояний (SSM), обеспечивающих линейное масштабирование во время обучения и постоянный размер состояния во время генерации. Интеграция моделей SSM в существующие глубокие нейронные сети остается сложной из-за их уникальной структуры и требований к оптимизации. Работа с SSM показала высокую производительность в задачах с долгосрочными зависимостями, но требует помощи в интеграции и оптимизации в установленные глубокие нейронные сети.
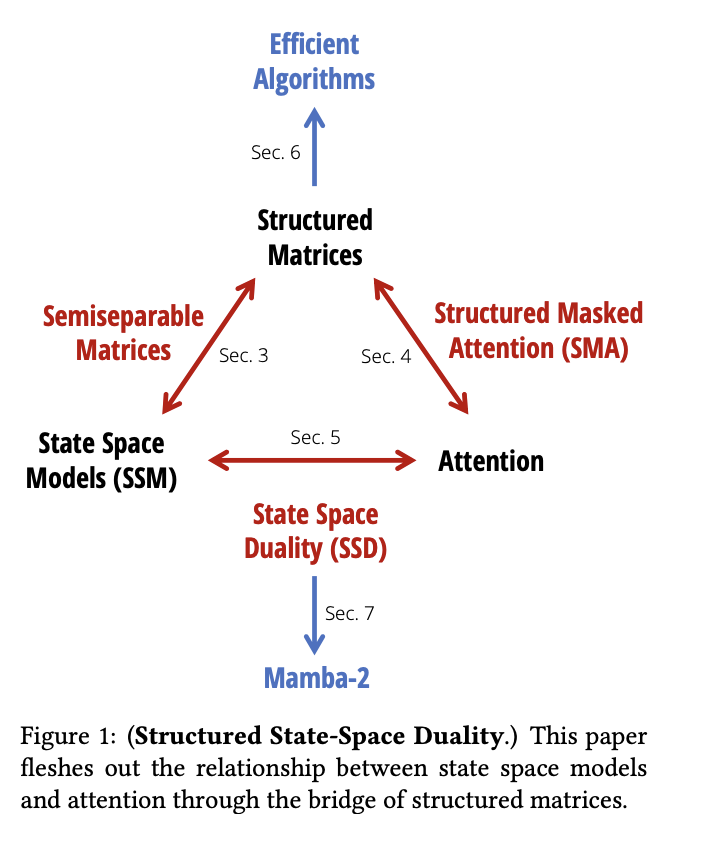
Исследователи из Университета Принстон и Университета Карнеги-Меллон представили Фреймворк Двойственного Пространства Состояний (SSD), который связывает SSM и механизмы внимания. Новая архитектура, Mamba-2, улучшает селективную SSM, достигая скорости в 2-8 раз быстрее своего предшественника, сохраняя при этом конкурентоспособную производительность с Трансформерами. Mamba-2 использует эффективность устройств матричного умножения в современном оборудовании для оптимизации процессов обучения и вывода.
Ядро дизайна Mamba-2 включает серию эффективных алгоритмов, использующих структуру полусепарабельных матриц. Эти матрицы позволяют достигнуть оптимального вычисления, использования памяти и масштабируемости, значительно повышая производительность модели. Mamba-2 также использует группированные механизмы внимания и тензорный параллелизм, архитектурные особенности, адаптированные из оптимизаций Трансформеров. Архитектура Mamba-2 также использует селективные SSM, способные динамически выбирать фокусировку на входных данных на каждом шаге, что позволяет достичь лучшего удержания информации и обработки. Эти инновации совместно обеспечивают баланс между вычислительной и памятью эффективностью, сохраняя высокую производительность, делая ее надежным инструментом для задач языкового моделирования.
Практическое применение:
Мамба-2 продемонстрировала превосходство над предыдущими моделями, достигая лучшей перплексии и времени работы, что делает ее надежной альтернативой для задач языкового моделирования. Например, Mamba-2, с 2,7 миллиардами параметров, обученная на 300 миллиардах токенов, превосходит своего предшественника и другие модели, такие как Pythia-2.8B и Pythia-6.9B в стандартных оценках.
Оценка эффективности Mamba-2 показывает значительные улучшения. Она достигает перплексии 6.09 на наборе данных Pile по сравнению с 6.13 для исходной модели Mamba. Более того, Mamba-2 демонстрирует более быстрые времена обучения, в 2-8 раз быстрее благодаря эффективной работе тензорных ядер для умножения матриц. Эти результаты подчеркивают эффективность модели в выполнении языковых задач большого масштаба, делая ее многообещающим инструментом для будущих разработок в обработке естественного языка.
Исследование представляет инновационный метод, который устраняет проблемы традиционных механизмов внимания в Трансформерах, предлагая масштабируемое и эффективное решение для языкового моделирования. Это достижение не только улучшает производительность, но также прокладывает путь для будущих разработок в этой области. Представление Фреймворка Двойственного Пространства Состояний и архитектуры Mamba-2 открывает перспективное направление для преодоления ограничений традиционных механизмов внимания в Трансформерах.
Для получения дополнительной информации ознакомьтесь с Докладом. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Твиттере. Присоединяйтесь к нашему Телеграм-каналу, Дискорд-каналу и Группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 43k+ ML SubReddit. Также ознакомьтесь с нашей платформой AI Events.
Источник: MarkTechPost.
«`

















