

«`html
Улучшение точности диагностики в LLM с помощью RuleAlign: исследование на примере набора данных UrologyRD
LLM, такие как GPT-4, MedPaLM-2 и Med-Gemini, хорошо справляются с медицинскими бенчмарками, но им требуется помощь для воссоздания диагностических способностей врачей. В отличие от врачей, собирающих информацию о пациентах через структурированные опросы и обследования, LLM часто нуждаются в большей логической последовательности и специализированных знаниях, что приводит к недостаточной диагностической логике. Хотя они могут помочь в начальном скрининге, используя медицинские корпуса, их ответы могут быть непоследовательными и не соответствовать профессиональным рекомендациям, особенно в сложных или специализированных случаях. Эта проблема подчеркивает их ограничения в предоставлении надежных медицинских диагнозов.
Применение RuleAlign для улучшения эффективности LLM в качестве AI-врачей
Исследователи из Университета Чжэцзян и Ant Group представили фреймворк RuleAlign, который направлен на выравнивание LLM с конкретными диагностическими правилами для улучшения их эффективности в качестве AI-врачей. Они разработали медицинский диалоговый набор данных, UrologyRD, с акцентом на правилах урологических взаимодействий. С использованием обучения предпочтений модель обучается таким образом, чтобы ее ответы соответствовали установленным протоколам без необходимости дополнительной человеческой аннотации. Экспериментальные результаты показывают, что RuleAlign улучшает производительность LLM как в однокруговых, так и в многокруговых оценках, демонстрируя их потенциал в медицинской диагностике.
Продвижение медицинских LLM в академии и индустрии
Медицинские LLM быстро развиваются в академии и индустрии, с усилиями, направленными на интеграцию медицинских данных в общие LLM через надзорное дообучение (SFT). Значительные примеры включают MedPaLM-2, Med-Gemini и китайские модели, такие как DoctorGLM и HuatuoGPT-II. Эти модели часто используют специализированные наборы данных, такие как BianQueCorpus, для балансировки способностей к вопросам и консультированию. Оптимизируйте LLM с помощью обучения предпочтений и моделей вознаграждения для улучшения подходов к выравниванию моделей, таких как RLHF и DPO. Техники, такие как SLiC и SPIN, улучшают выравнивание путем комбинирования функций потерь, аугментации данных и итеративного обучения.
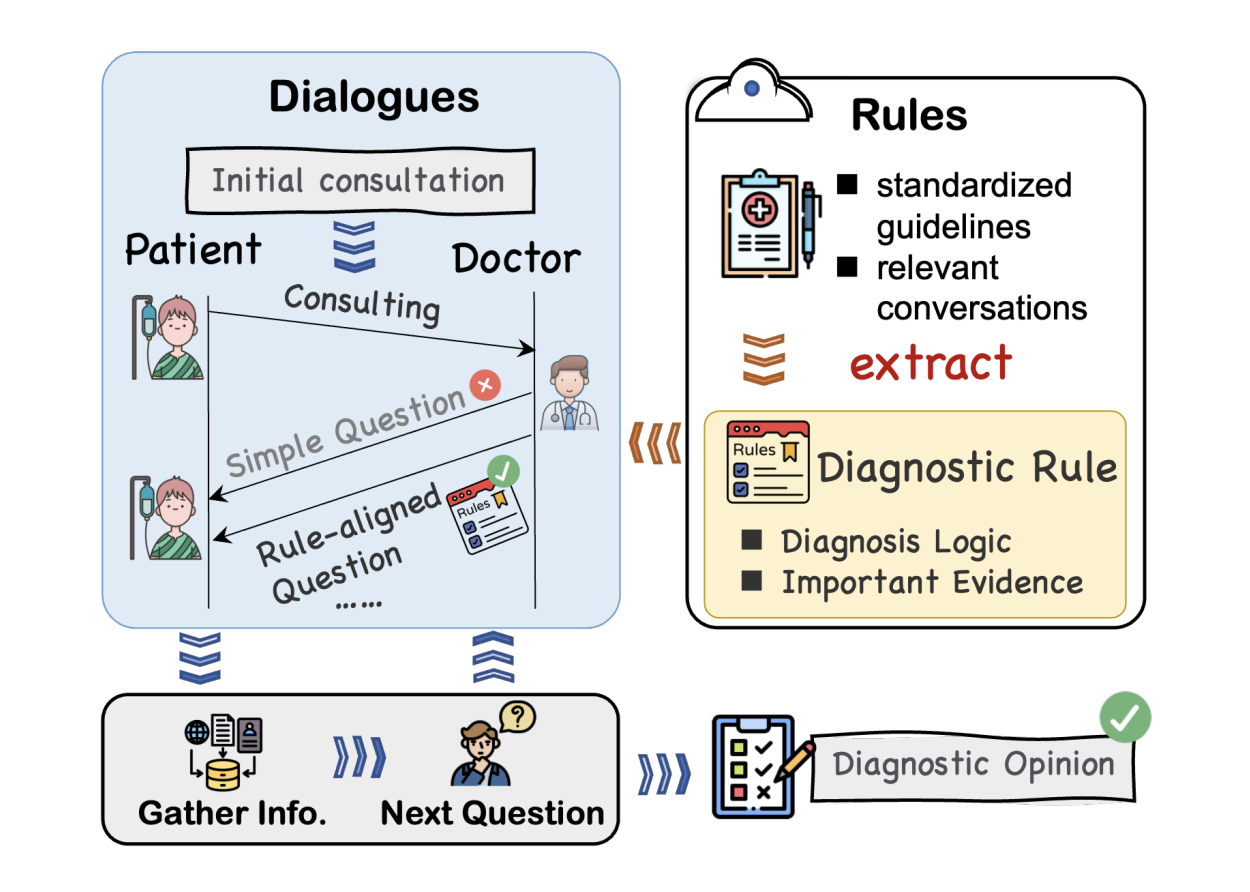
Создание набора данных UrologyRD и выравнивание LLM с человеческими целями
Для создания набора данных UrologyRD исследователи сначала собрали подробные диагностические правила, суммируя соответствующие медицинские разговоры и извлекая ключевые рекомендации. Эти правила фокусируются на урологии, указывая ограничения, связанные с заболеваниями, и необходимые доказательства для диагностики. Набор данных был сгенерирован путем сопоставления названий заболеваний более широким категориям и адаптации диалогов с использованием этих правил. Для выравнивания LLM с человеческими целями фреймворк RuleAlign использует обучение предпочтений. Он оптимизирует выводы LLM путем обучения на основе диалогов, отличающих предпочтительные и непредпочтительные ответы, и улучшения через семантическую схожесть и нарушение порядка диалога для улучшения диагностической точности.
Оценка производительности LLM для медицинской диагностики
Однокруговые и многокруговые тесты используются для оценки производительности LLM при медицинской диагностике. Метрики, такие как перплексия, ROUGE и BLEU, применяются в однокруговых тестах. В то же время SP-тестирование оценивает модели по полноте информации, логической последовательности руководства, диагностической логичности, клинической применимости и логичности лечения. RuleAlign демонстрирует превосходную производительность, улучшая оценки ROUGE и BLEU и снижая перплексию. Он эффективно выравнивает ответы LLM с диагностическими правилами, хотя иногда сталкивается с галлюцинациями и логической последовательностью. Оптимизационные стратегии метода, включая семантическую схожесть и нарушение порядка, значительно улучшают точность модели и последовательность в генерации медицинских диалогов.
Заключение
Исследование представляет набор данных UrologyRD, основанный на диагностических правилах, и предлагает RuleAlign, инновационный метод для автоматического синтеза и выравнивания предпочтительных пар. Эксперименты демонстрируют эффективность RuleAlign в различных настройках оценки. Несмотря на прогресс в LLM, таких как GPT-4, MedPaLM-2 и Med-Gemini, которые конкурируют с человеческими экспертами, остаются проблемы в их диагностических способностях, особенно в сборе информации о пациентах и рассуждениях. RuleAlign нацелен на решение этих проблем путем выравнивания LLM с диагностическими правилами, что потенциально продвигает исследования в области медицинских приложений на основе ИИ и улучшает роль LLM в качестве AI-врачей.
«`
















