

«`html
Улучшение возможностей проктивного общения крупных моделей языка и зрения (LVLMs) с помощью MACAROON
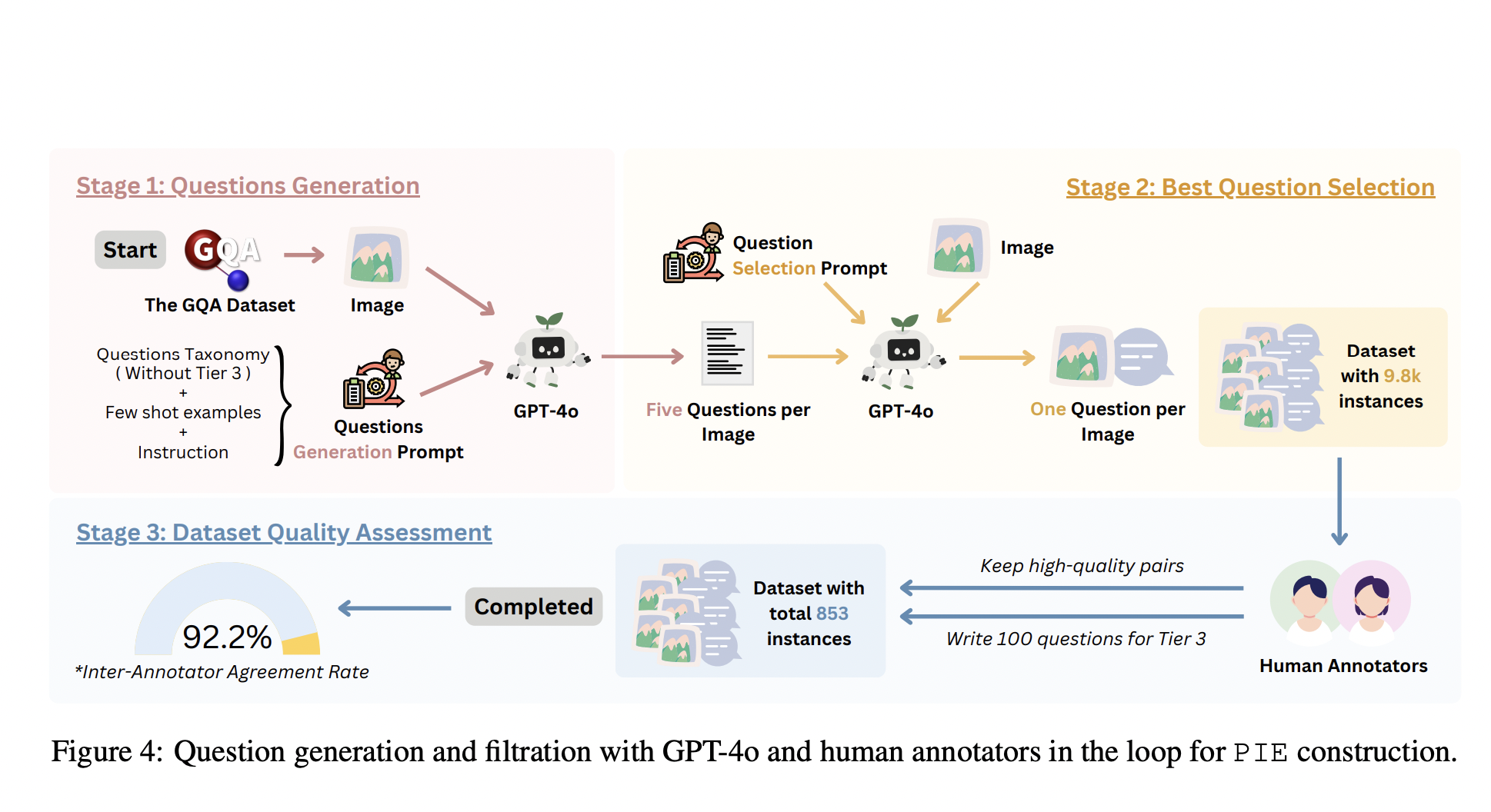
Крупные модели языка и зрения (LVLMs) отлично справляются с задачами, требующими визуального понимания и обработки языка. Однако они всегда готовы предоставлять ответы, что делает их пассивными поставщиками ответов. Часто LVLMs дают детальные и уверенные ответы, даже когда вопрос не ясен или невозможен. Например, LLaVA, одна из лучших открытых LVLMs, делает предположения при столкновении с неясными или недопустимыми вопросами, что приводит к предвзятым и неправильным ответам. Это происходит потому, что LVLMs не вступают в проактивное взаимодействие, которое должно включать в себя опротестование недопустимых вопросов, запрос уточнения сложных источников информации и поиск дополнительных данных при необходимости.
Решение:
Применение MACAROON для повышения проактивной способности общения LVLMs, путем создания пар контрастных ответов на основе описаний задач и критериев, определенных людьми. Это позволяет моделям отличать хорошие и плохие ответы и стандартизировать данные обучения, обеспечивая более динамичное и проактивное взаимодействие (0,84 AAR после MACAROON).
Практическое применение:
Применение MACAROON для улучшения проактивной способности общения LVLMs, путем создания пар контрастных ответов на основе описаний задач и критериев, определенных людьми. Это позволяет моделям отличать хорошие и плохие ответы и стандартизировать данные обучения, обеспечивая более динамичное и проактивное взаимодействие (0,84 AAR после MACAROON).
Значение:
Результаты предложенного метода показывают положительные изменения в поведении LVLMs, обеспечивая более динамичную и проактивную парадигму взаимодействия. MACAROON также демонстрирует сильную производительность в общих задачах языка и зрения, занимая второе место в SEEDBench и AI2D, а также третье место в разделах восприятия и рассуждения MME.
Рекомендации:
Использование MACAROON для улучшения проактивной способности общения LVLMs, путем создания пар контрастных ответов на основе описаний задач и критериев, определенных людьми. Это позволяет моделям отличать хорошие и плохие ответы и стандартизировать данные обучения, обеспечивая более динамичное и проактивное взаимодействие (0,84 AAR после MACAROON).
Для получения дополнительной информации ознакомьтесь с статьей и GitHub.
Все права на это исследование принадлежат его авторам. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему субреддиту ML SubReddit.
«`

















