

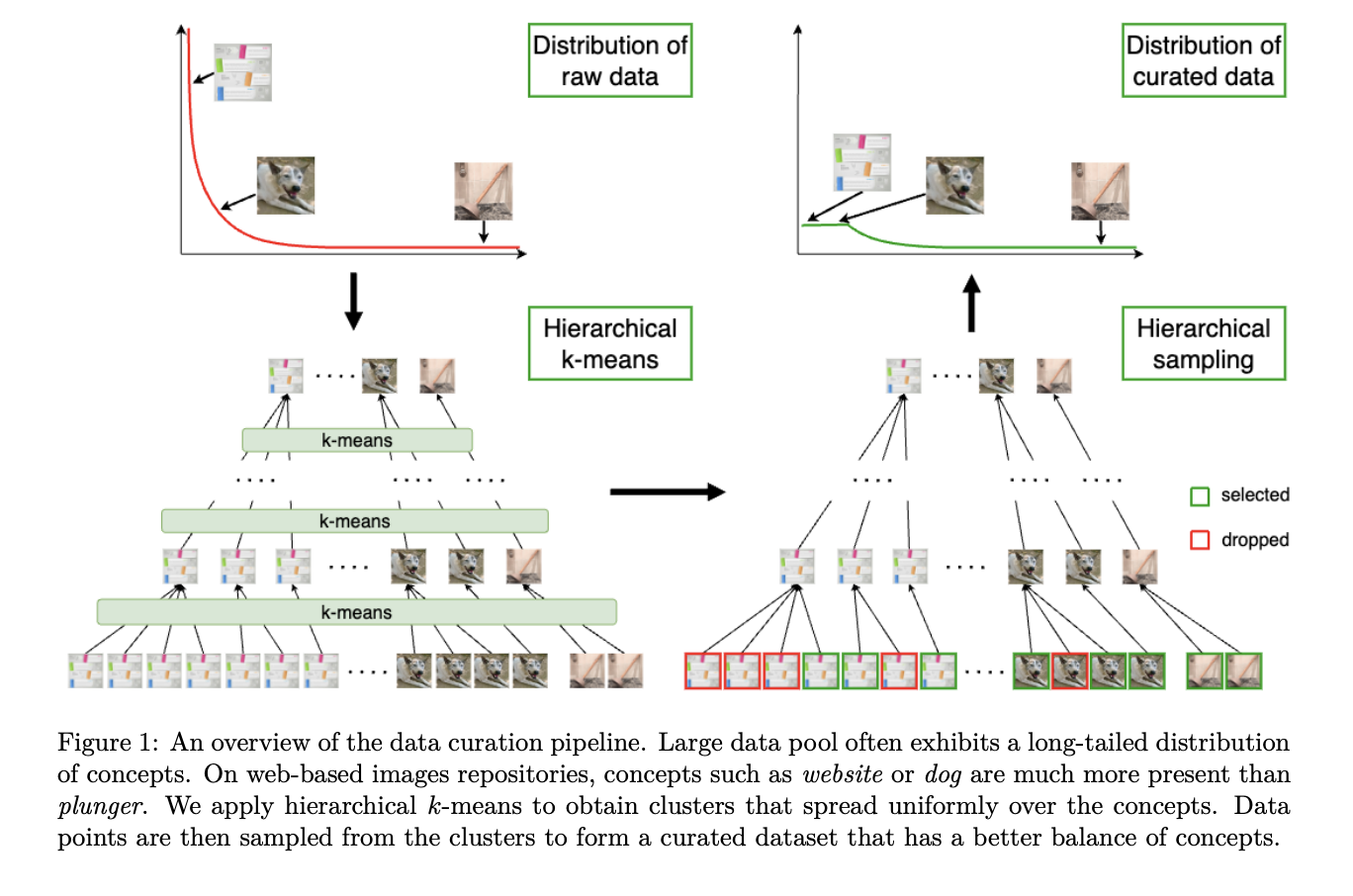
«`html
Улучшение самообучения с помощью автоматической куратории данных: подход на основе иерархического к-средних
Самообучаемые функции являются основой современного машинного обучения и, как правило, требуют обширных усилий человека по сбору и куратории данных, аналогично обучению с учителем. Самообучение позволяет моделям обучаться без аннотаций человека, обеспечивая масштабируемость данных и расширение моделей. Однако усилия по масштабированию иногда приводят к недостаточной производительности из-за проблем, таких как длиннохвостое распределение понятий в необработанных наборах данных. Успешные применения самообучения требуют тщательной куратории данных, такой как фильтрация интернет-данных для соответствия высококачественным источникам, таким как Википедия для языковых моделей или балансировка визуальных концепций для моделей изображений. Эта куратория улучшает стабильность и производительность в последующих задачах.
Кластерный подход к автоматической куратории качественных наборов данных для предварительного самообучения
Исследователи из FAIR at Meta, INRIA, Université Paris Saclay и Google рассматривают автоматическую кураторию высококачественных наборов данных для предварительного самообучения. Они предлагают кластерный подход для создания больших, разнообразных, сбалансированных наборов данных. Этот метод включает иерархическую кластеризацию по методу k-средних на обширном репозитории данных и сбалансированную выборку из этих кластеров. Эксперименты с веб-изображениями, спутниковыми изображениями и текстом показывают, что функции, обученные на этих отобранных наборах данных, превосходят те, которые были обучены на необработанных данных, соответствуя или превосходя вручную отобранные данные. Этот подход решает проблему балансировки данных для улучшения производительности модели в предварительном самообучении.
Значимость автоматической куратории данных для самообучения
Предварительный набор данных должен быть большим, разнообразным и сбалансированным для эффективного обучения моделей с помощью предварительного самообучения. Сбалансированные наборы данных обеспечивают равное представление каждого концепта, избегая предвзятости в пользу доминирующих концепций. Создание таких наборов данных включает выбор сбалансированных подмножеств из больших онлайн-репозиториев, часто с использованием методов кластеризации, таких как k-средних. Однако стандартный метод k-средних может перегружать доминирующие концепции. Для решения этой проблемы можно использовать иерархический метод k-средних с повторной выборкой, обеспечивающий равномерное распределение центроидов. Этот процесс, в сочетании с конкретными стратегиями выборки, помогает поддерживать баланс на различных уровнях концепций в наборе данных, способствуя лучшей производительности модели.
Результаты экспериментов и выводы
Было проведено четыре эксперимента для изучения предложенного алгоритма. Изначально использовались симулированные данные для иллюстрации иерархической кластеризации методом k-средних, показывающие более равномерное распределение кластеров, чем другие методы. Затем были подготовлены веб-изображения, в результате чего был создан набор данных из 743 миллионов изображений, и модель ViT-L была обучена и оценена на различных показателях, демонстрируя улучшенную производительность. Затем алгоритм был применен для куратории текстовых данных для обучения больших языковых моделей, что привело к значительным улучшениям по различным показателям. Наконец, спутниковые изображения были отобраны для прогнозирования высоты кроны деревьев, улучшая производительность модели на всех оцениваемых наборах данных.
В заключение, в исследовании представлен автоматический конвейер куратории данных, который генерирует большие, разнообразные, сбалансированные наборы данных для обучения самообучаемых функций. Применение последовательной кластеризации k-средних и повторной выборки обеспечивает равномерное распределение кластеров по концептам. Обширные эксперименты показывают, что такой подход улучшает обучение функций среди веб-изображений, спутниковых изображений и текстовых данных. Отобранные наборы данных превосходят обрабатываемые данные и ImageNet1k в устойчивости, но немного уступают вручную отобранным данным ImageNet22k по некоторым показателям. Этот подход выделяет важность куратории данных в самообучении и предполагает иерархический метод k-средних как ценную альтернативу в различных зависящих от данных задачах. Дальнейшая работа должна рассмотреть качество наборов данных, зависимость от предварительно обученных функций и масштабируемость. Автоматизированное создание наборов данных несет риски, такие как усиление предвзятостей и нарушение приватности, чему здесь противодействует смазывание человеческих лиц и стремление к балансу концепций.
Источник. Любая благодарность за это исследование должна быть направлена исследователям этого проекта.
Применение искусственного интеллекта в маркетинговых и продажных решениях
Если вы хотите, чтобы ваша компания продолжала развиваться с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте информацию об улучшении самообучения с помощью автоматической куратории данных. Проанализируйте, как ИИ может изменить вашу работу и определите возможности для автоматизации, где ваши клиенты могут извлечь выгоду из применения ИИ. Определите KPI, которые вы хотите улучшить с помощью ИИ, и подберите подходящие решения, внедряя их постепенно и анализируя результаты и KPI. Вам могут потребоваться консультации по внедрению ИИ — обращайтесь к нам для помощи и следите за новостями о ИИ в нашем Телеграм-канале и Twitter.
AI Sales Bot – инструмент, который поможет снижать нагрузку на отдел продаж и улучшать обслуживание клиентов. Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru!
Если вам нужна помощь по внедрению ИИ, пишите нам на Telegram и следите за новостями в нашем Телеграм-канале или в Twitter.
«`



















