

«`html
Эффективный подход к снижению потребления памяти и повышению пропускной способности в больших языковых моделях (LLM)
Эффективное использование больших языковых моделей (LLM) требует высокой производительности и низкой задержки. Однако значительное потребление памяти LLM, особенно кэшем ключ-значение (KV), препятствует достижению больших размеров пакета и высокой производительности. Кэш KV, хранящий ключи и значения во время генерации, потребляет более 30% памяти GPU. Различные подходы, такие как сжатие последовательностей KV и динамические политики вытеснения кэша, направлены на облегчение этого бремени памяти в LLM.
Практические решения и ценность:
- Внедрение пагинированного внимания для снижения фрагментации памяти.
- Сжатие подсказок, удаление избыточности входного контекста и инкрементное сжатие токенов.
- Прореживание неважных токенов, применение различных стратегий прореживания кэша внимания и хранение только важных токенов.
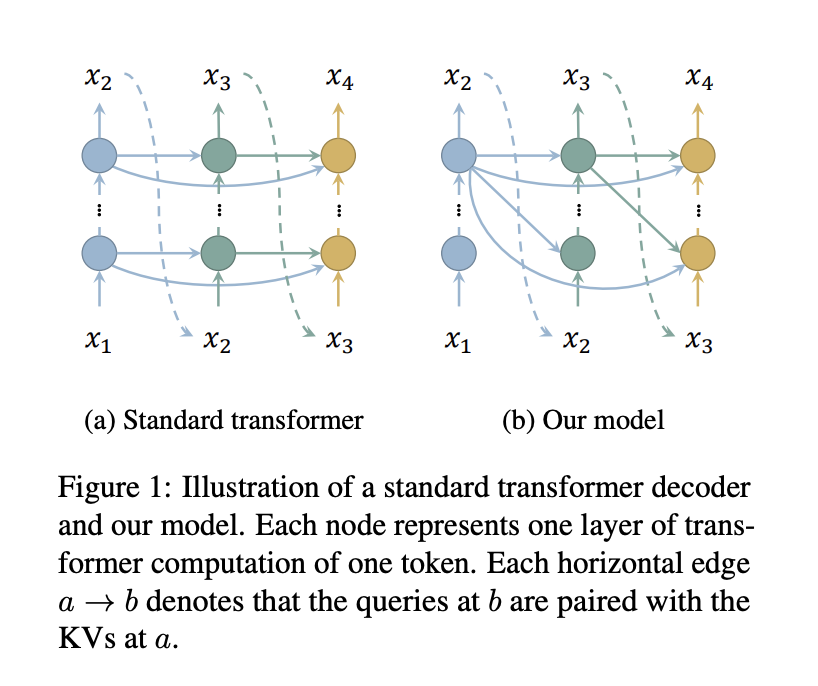
- Парное связывание запросов всех слоев с ключами и значениями только верхнего слоя, что значительно экономит память без дополнительной вычислительной нагрузки.
Исследователи из Школы информационных наук и технологий Университета ШанхайТек и Шанхайского инженерного исследовательского центра интеллектуального зрения и изображений представляют эффективный подход к снижению потребления памяти в кэше KV декодеров трансформаторов за счет уменьшения количества кэшированных слоев. Модель внедряет стандартное внимание для нескольких слоев для снижения потери производительности.
Практические решения и ценность:
- Уменьшение количества кэшированных слоев для сокращения потребления памяти и улучшения производительности.
- Интеграция стандартного внимания для нескольких слоев для поддержания синтаксическо-семантического шаблона, обеспечивая конкурентоспособную производительность с обычными моделями.
Исследователи оценили свой метод с использованием моделей с 1,1 млрд, 7 млрд и 30 млрд параметров на различных GPU, включая NVIDIA GeForce RTX 3090 и A100. Реализация использует HuggingFace Transformers с FlashAttention 2, объединенным нормированием RMS, объединенной кросс-энтропией и объединенным SwiGLU. Оценка включает задержку и пропускную способность, результаты показывают значительно большие размеры пакета и более высокую пропускную способность по сравнению с обычными моделями Llama в различных настройках.
Практические решения и ценность:
- Сравнимая точность при решении задач на основе здравого смысла с TinyLlama.
- Интеграция с StreamingLLM снижает задержку и потребление памяти, обеспечивая эффективную обработку токенов бесконечной длины.
- Достижение конкурентоспособной производительности и более высокой эффективности вывода.
Данное исследование представляет надежный метод снижения потребления памяти и увеличения производительности в LLM за счет минимизации числа слоев, требующих вычисления и кэширования ключей и значений. Эмпирические результаты демонстрируют значительное снижение потребления памяти и улучшение производительности с минимальной потерей производительности.
Практические решения и ценность:
- Безперебойная интеграция с другими методами экономии памяти, такими как StreamingLLM.
Подробнее см. Статью и GitHub. Все права на это исследование принадлежат его авторам. Также не забудьте подписаться на нас в Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вас заинтересовала наша работа, вам понравится наш информационный бюллетень.
Не забудьте присоединиться к нашему ML SubReddit.
Источник: MarkTechPost.
«`

















