

«`html
Оптимизация крупных языковых моделей (LLM) на процессорах: техники для улучшения вывода и эффективности
Большие языковые модели (LLM), построенные на архитектуре Transformer, недавно достигли важных технологических достижений. Улучшенные навыки этих моделей в понимании и создании текстов, похожих на человеческие, существенно повлияли на различные приложения искусственного интеллекта (ИИ).
Однако, несмотря на отличную работу этих моделей, существует множество препятствий для успешной их реализации в условиях ограниченных ресурсов. В индустрии уделяется большое внимание этой проблеме, особенно в ситуациях ограниченного доступа к аппаратным ресурсам GPU. В таких случаях альтернативы на базе ЦП становятся необходимыми.
Решение
Улучшение производительности вывода имеет важное значение для снижения затрат и преодоления ограничений ограниченных аппаратных ресурсов. В недавнем исследовании команда ученых представила простой внедряемый подход, который улучшает производительность вывода LLM на процессорах. Одной из основных особенностей этого решения является его реализация практичного способа снижения размера кэша KV без ущерба точности. Для обеспечения эффективной работы LLM даже при ограниченных ресурсах эта оптимизация является важной.
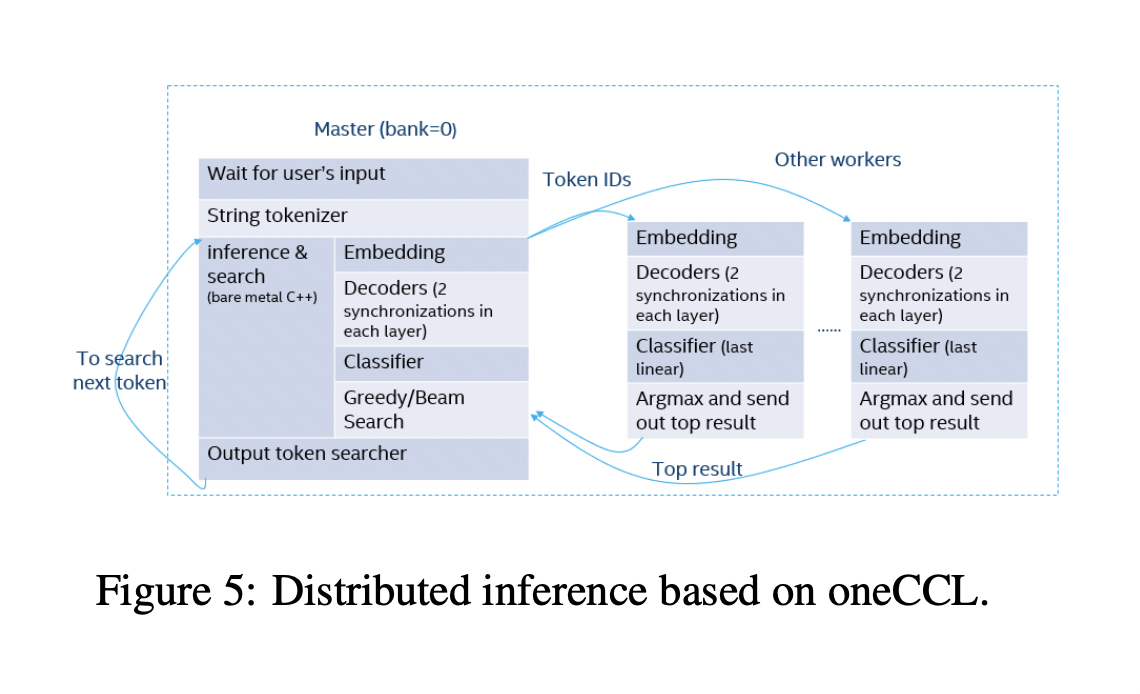
Исследование также предложило метод оптимизации распределенного вывода, который использует библиотеку коллективных коммуникаций oneAPI. Путем обеспечения эффективного обмена информацией и обработки между несколькими ЦП, этот метод значительно повышает масштабируемость и производительность LLM. Кроме того, рассмотрены индивидуальные оптимизации для наиболее популярных моделей, гарантируя, что решение является гибким и подходит для различных LLM. Целью внедрения этих оптимизаций является ускорение работы LLM на ЦП, что увеличит их доступность и доступность для развертывания в условиях ограниченных ресурсов.
Основные преимущества
- Уникальные методы оптимизации LLM на ЦП, такие как SlimAttention, совместимые с популярными моделями, такими как Qwen, Llama, ChatGLM, Baichuan и серия Opt, включают различные оптимизации для процедур и слоев LLM.
- Была предложена работоспособная стратегия для снижения размера кэша KV без ущерба точности. Этот метод улучшает эффективность использования памяти без значительного снижения качества выходных данных модели.
- Специально для LLM на ЦП команда разработала метод оптимизации распределенного вывода. Этот метод подходит для приложений крупномасштабного применения, поскольку гарантирует масштабируемость и эффективность вывода с низкой задержкой.
Посмотрите статью и GitHub. Вся заслуга за это исследование принадлежит ученым проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш информационный бюллетень.
Не забудьте присоединиться к нашему сабреддиту по МL.
Исходный пост опубликован на MarkTechPost.
«`



















