

«`html
Оценка будущих вознаграждений в RL: практические решения и ценность
Оценка будущих вознаграждений критична в RL, так как предсказывает накопительные вознаграждения, которые агент может получить, обычно через Q-значения или функции значения состояния. Однако эти скалярные выходы не дают подробностей о том, когда или какие конкретные вознаграждения агент ожидает. Это ограничение значимо в приложениях, где важны человеческое сотрудничество и пояснимость. Например, в ситуации, где дрон должен выбрать между двумя путями с разными вознаграждениями, только Q-значения не раскрывают характер вознаграждений, что важно для понимания процесса принятия решений агента.
Решение
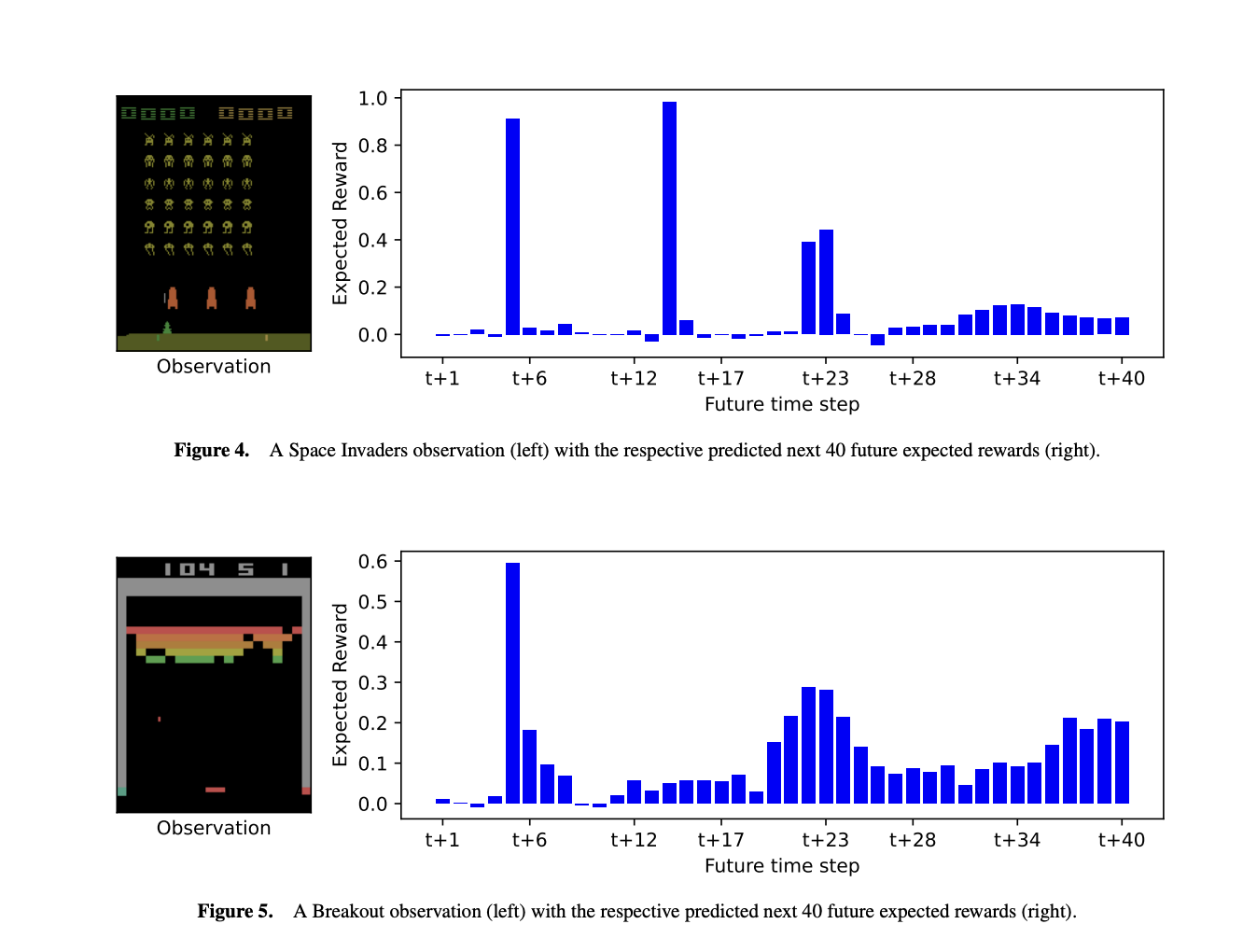
Ученые из Университета Саутгемптона и Королевского Колледжа Лондона представили Темпоральное Разложение Вознаграждения (TRD) для улучшения пояснимости в обучении с подкреплением. TRD модифицирует оценщик будущих вознаграждений агента для предсказания следующих N ожидаемых вознаграждений, раскрывая, когда и какие вознаграждения ожидаются. Этот подход позволяет лучше интерпретировать решения агента, объясняя время и значение ожидаемых вознаграждений и влияние различных действий. С минимальным влиянием на производительность TRD может быть интегрирован в существующие модели RL, такие как агенты DQN, предлагая ценные исследования поведения агента и процессов принятия решений в сложных средах.
Исследование
Исследование сосредоточено на существующих методах объяснения принятия решений агентами RL на основе вознаграждений. Предыдущие работы исследовали разложение Q-значений на составляющие вознаграждения или будущие состояния. Некоторые методы контрастируют источники вознаграждений, такие как монеты и сундуки с сокровищами, в то время как другие разлагают Q-значения по важности состояния или вероятностям перехода. Однако эти подходы должны учитывать время вознаграждений и могут не масштабироваться до сложных сред. Альтернативы, такие как формирование вознаграждения или карты выдающихся вознаграждений, предлагают объяснения, но требуют модификаций среды или фокусируются на визуальных областях, а не на конкретных вознаграждениях. TRD представляет подход путем разложения Q-значений по времени, позволяя новые методы объяснения.
Ключевые методы
В исследовании представлены три метода объяснения будущих вознаграждений и процессов принятия решений агента в средах обучения с подкреплением. Во-первых, описывается, как TRD предсказывает, когда и какие вознаграждения агент ожидает, помогая понять поведение агента в сложных средах, таких как игры Atari. Во-вторых, используется GradCAM для визуализации, какие особенности наблюдения влияют на прогнозы ближних и отдаленных вознаграждений. Наконец, используются контрастные объяснения для сравнения влияния различных действий на будущие вознаграждения, выявляя, как немедленные и отсроченные вознаграждения влияют на принятие решений. Эти методы предлагают новые идеи для понимания поведения агента и процессов принятия решений.
Заключение
TRD улучшает понимание агентов обучения с подкреплением, предоставляя подробные исследования будущих вознаграждений. TRD может быть интегрирован в предварительно обученные агенты Atari с минимальной потерей производительности. Он предлагает три ключевых инструмента объяснения: предсказание будущих вознаграждений и уверенности агента в них, выявление изменения важности особенностей с течением времени вознаграждения и сравнение влияния различных действий на будущие вознаграждения. TRD раскрывает более детальные сведения о поведении агента, такие как время вознаграждения и уверенность, и может быть расширен с помощью дополнительных методов разложения или вероятностных распределений для будущих исследований.
Интересное чтение
Познакомьтесь с документом. Вся заслуга за это исследование принадлежит исследователям этого проекта.
«`



















