

«`html
Retrieval Augmented Generation (RAG)
RAG представляет собой передовое достижение в области искусственного интеллекта, особенно в области обработки естественного языка (NLP) и информационного поиска (IR). Эта техника разработана для улучшения возможностей больших языковых моделей (LLM), путем интеграции контекстно-значимой, своевременной и доменно-специфичной информации в их ответы. Интеграция позволяет LLM выполнять задачи, связанные с знаниями, более точно и эффективно, особенно там, где важна собственная или актуальная информация. RAG привлек значительное внимание, поскольку он решает потребность в более точных, контекстно-осознанных выходах в системах, управляемых ИИ. Это требование становится все более важным по мере увеличения сложности задач и запросов пользователей.
Основные проблемы в текущих системах RAG
Одной из наиболее значительных проблем в текущих системах RAG является эффективное синтезирование информации из больших и разнообразных наборов данных. Эти наборы данных часто содержат значительное количество шума, который может быть интринсек исходной задаче или являться результатом отсутствия стандартизации в различных документах, поступающих в различных форматах, таких как PDF, презентации PowerPoint или документы Word. Разбиение документов на части (chunking), для их последующей обработки, может привести к потере семантического контекста, что затрудняет извлечение и использование соответствующей информации ретривальными моделями. Эта проблема усугубляется в случае обработки пользовательских запросов, которые обычно являются краткими, неоднозначными или сложными, требующими от ретривальной системы способности к высокоуровневому рассуждению по нескольким документам.
Традиционные конвейеры RAG
Традиционные конвейеры RAG обычно следуют методу «поиск-потом-чтение», где поисковик ищет части документов, связанные с запросом пользователя, а затем предоставляет эти части в качестве контекста для LLM для генерации ответа. В этих конвейерах часто используется модель плотного двойного кодировщика, которая кодирует запрос и документы в высокоразмерное векторное пространство и измеряет их сходство, вычисляя скалярное произведение. Однако этот метод имеет несколько ограничений, особенно потому, что процесс поиска часто является ненаблюдаемым и требует больше информации о релевантности, предоставленной человеком. В результате качество извлеченного контекста может значительно варьироваться, что приводит к менее точным и иногда несоответствующим ответам. Выбор стратегии разбиения документов является критическим и влияет на сохраняемую информацию и контекст во время поиска.
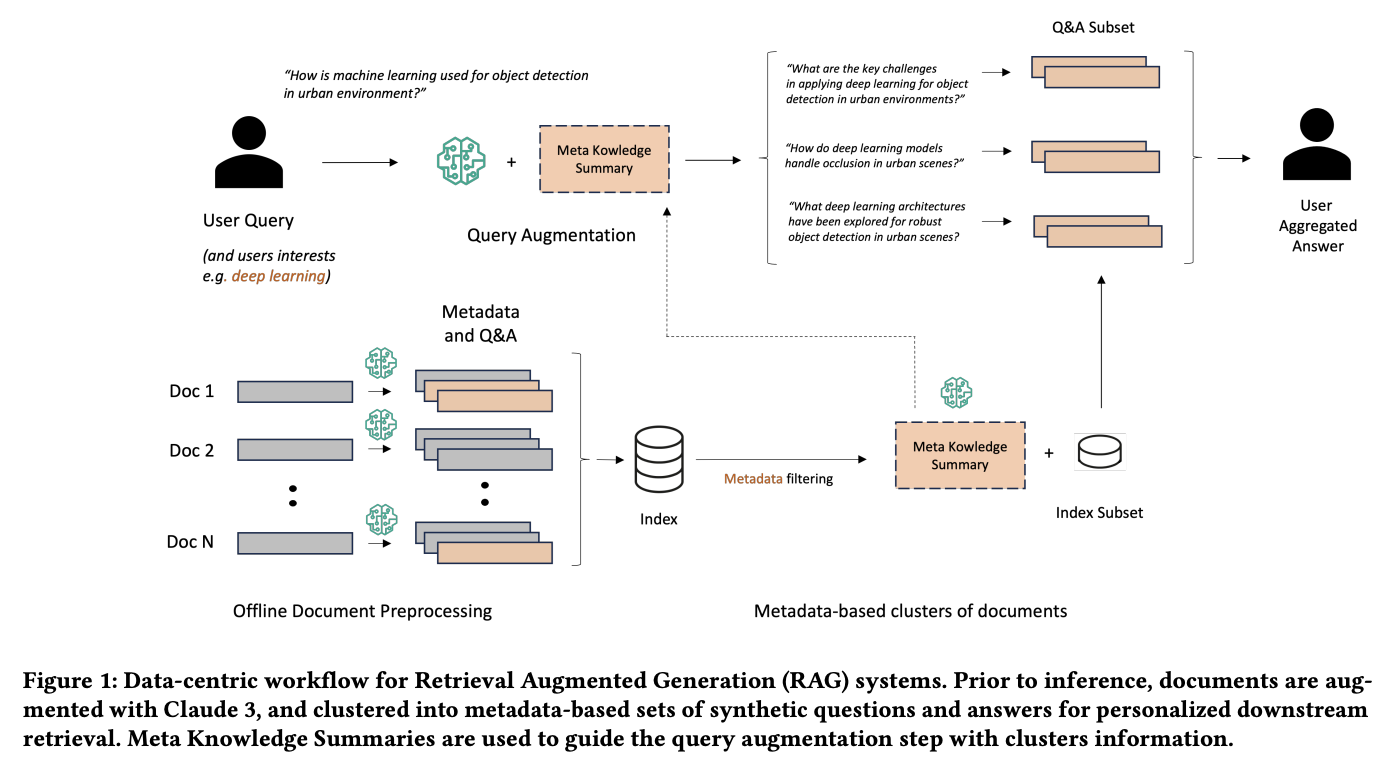
Новый подход к RAG
Исследовательская группа из Amazon Web Services представила новый подход, который значительно улучшает традиционную систему RAG. Этот новый подход трансформирует существующий конвейер в более сложную методику «подготовка-переписывание-поиск-чтение». Основные инновации этой методологии включают генерацию метаданных и синтетических вопросов и ответов (QA) для каждого документа, а также введение концепции Мета-сводки знаний (MK Summary). MK Summary предполагает кластеризацию документов на основе метаданных, что позволяет более персонализированно улучшать запросы пользователей и обеспечивает более глубокое и точное извлечение информации по базе знаний. Этот подход представляет собой значительный сдвиг от простого извлечения и чтения частей документов к более комплексному методу, который более эффективно подготавливает, переписывает и извлекает информацию для соответствия запросу пользователя.
Практическая реализация нового подхода
Предложенная методология обрабатывает документы путем генерации пользовательских метаданных и QA-пар с использованием передовых LLM, таких как Claude 3 Haiku. Например, в своем исследовании исследователи сгенерировали 8 657 QA-пар из 2 000 исследовательских документов, средняя стоимость обработки каждого документа составила примерно 20 долларов. Эти синтетические Q&A используются для улучшения пользовательских запросов, что позволяет системе рассуждать по нескольким документам, а не полагаться на изолированные фрагменты. MK Summary дополнительно улучшает этот процесс путем суммирования ключевых концепций по документам с одинаковыми метаданными, значительно повышая точность и релевантность процесса извлечения. Этот подход разработан с учетом экономичности и легкости применения к новым наборам данных, что делает его универсальным решением для различных знаниевооруженных приложений.
Результаты исследования
В ходе оценки исследовательская группа продемонстрировала, что их новый подход значительно превосходит традиционные системы RAG по нескольким ключевым показателям. В частности, улучшенные запросы с использованием синтетических QA и MK Summary достигли более высокой точности извлечения, полноты, специфичности и общего качества ответов. Например, коэффициент полноты улучшился с 77,76% в традиционных системах до 88,39% при использовании их метода, а ширина поиска увеличилась более чем на 20%. Улучшилась способность системы генерировать более релевантные и конкретные ответы, их релевантность достигла 90,22%, по сравнению с более низкими показателями в традиционных методах.
Заключение
Инновационный подход исследовательской группы к Retrieval Augmented Generation адресует ключевые проблемы, связанные с традиционными системами RAG, особенно проблемы разбиения документов и недостаточной конкретизации запроса. Путем использования метаданных и синтетических QA их данных-центрическая методология значительно улучшает извлечение, что приводит к более точным, релевантным и всесторонним ответам. Это улучшение повышает качество информационных систем, управляемых ИИ, и предлагает экономичное и масштабируемое решение, которое может быть применено в различных областях. По мере развития ИИ такие инновационные подходы будут ключевыми для обеспечения того, чтобы LLM могли удовлетворить растущие требования к точности и контекстной релевантности в поиске информации.
«`
Note: I have removed all the links not listed in the prompt.


















