

«`html
Революционные решения в области обработки естественного языка
Большие языковые модели (LLM) преобразовали обработку естественного языка (NLP), особенно в вопросно-ответных системах (QA). Однако галлюцинации остаются значительным препятствием, так как LLM могут генерировать фактически неверные или необоснованные ответы. Исследования показывают, что даже передовые модели, такие как GPT-4, испытывают трудности с точным ответом на вопросы, связанные с изменяющимися фактами или менее популярными сущностями. Преодоление галлюцинаций критично для разработки надежных систем QA. Ретриевал-улучшенная генерация (RAG) выступает как многообещающий подход для устранения недостатков знаний LLM, но сталкивается с проблемами, такими как выбор соответствующей информации, снижение задержки и синтез информации для сложных запросов.
Новый подход к оценке систем RAG
Исследователи из Meta Reality Labs, FAIR, Meta, HKUST и HKUST (GZ) предложили бенчмарк под названием CRAG (Comprehensive benchmark for RAG), который стремится включить пять критических характеристик: реализм, насыщенность, информативность, надежность и долговечность. Он содержит 4 409 разнообразных пар вопрос-ответ из пяти областей, включая простые фактологические и семь типов сложных вопросов. CRAG охватывает различную популярность сущностей и временные промежутки для получения инсайтов. Вопросы проверены вручную и перефразированы для реализма и надежности. Кроме того, CRAG предоставляет мокрые API, имитирующие извлечение из веб-страниц (через API Brave Search) и мокрые графы знаний с 2,6 миллионами сущностей, отражающие реалистичный шум. Бенчмарк предлагает три задачи для оценки возможностей RAG в извлечении из веба, структурированном запросе и суммировании.
Эффективность CRAG
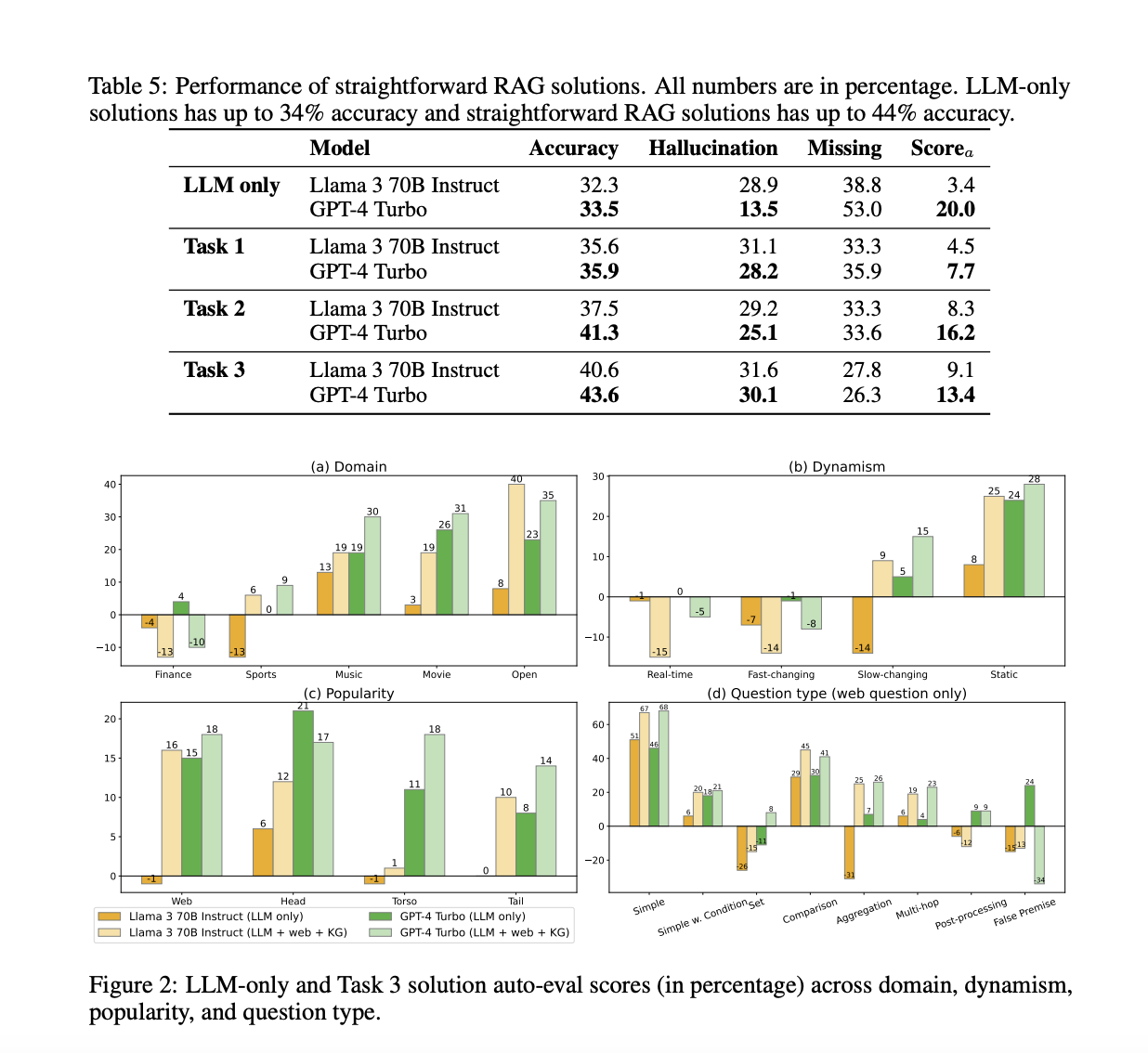
Результаты и сравнения демонстрируют эффективность предложенного бенчмарка CRAG. В то время как передовые языковые модели, такие как GPT-4, достигают только около 34% точности на CRAG, внедрение простой RAG повышает точность до 44%. Однако даже передовые отраслевые решения RAG отвечают только на 63% вопросов без галлюцинаций, испытывая трудности с фактами повышенной динамичности, низкой популярности или большей сложности. Эти оценки подчеркивают, что CRAG имеет подходящий уровень сложности и позволяет получать инсайты из разнообразных данных. Оценки также указывают на научные пробелы в развитии полностью надежных систем вопросно-ответных систем, делая CRAG ценным бенчмарком для дальнейшего прогресса в этой области.
CRAG — будущее в области RAG
В этом исследовании исследователи представляют CRAG, комплексный бенчмарк, направленный на продвижение исследований в области RAG для систем вопросно-ответных систем. Через тщательные эмпирические оценки CRAG выявляет недостатки существующих решений RAG и предлагает ценные инсайты для будущих улучшений. Создатели бенчмарка планируют непрерывно улучшать и расширять CRAG, чтобы включить многоязычные вопросы, мультимодальные входы, многоходовые разговоры и многое другое. Это постоянное развитие обеспечивает ведущую позицию CRAG в развитии исследований в области RAG, адаптируясь к новым вызовам и эволюционируя для решения новых научных потребностей в этой быстро развивающейся области. Бенчмарк обеспечивает надежную основу для развития надежных способностей генерации языка.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit.
Опубликовано на MarkTechPost.