

«`html
Решение для обработки длинных текстовых последовательностей в NLP
В обработке естественного языка (NLP) эффективная работа с длинными текстовыми последовательностями представляет собой серьезное испытание. Традиционные модели трансформеров, широко используемые в больших языковых моделях (LLM), отлично справляются с многими задачами, но нуждаются в улучшении при обработке длинных входов. Эти ограничения в основном связаны с квадратичной вычислительной сложностью и линейными затратами памяти, связанными с механизмом внимания, используемым в трансформерах. По мере увеличения длины текста, требования к этим моделям становятся непозволительно высокими, что затрудняет поддержание точности и эффективности. Это привело к разработке альтернативных архитектур, направленных на более эффективное управление длинными последовательностями при сохранении вычислительной эффективности.
Основные проблемы моделирования длинных последовательностей в NLP
Одной из ключевых проблем моделирования длинных последовательностей в NLP является деградация информации при увеличении длины текста. Рекуррентные нейронные сети (RNN), часто используемые в основе этих моделей, особенно подвержены этой проблеме. По мере увеличения длины входных последовательностей эти модели нуждаются в помощи для сохранения важной информации из более ранних частей текста, что приводит к снижению производительности. Эта деградация является серьезным препятствием для разработки более продвинутых LLM, способных обрабатывать расширенные текстовые входы без потери контекста или точности.
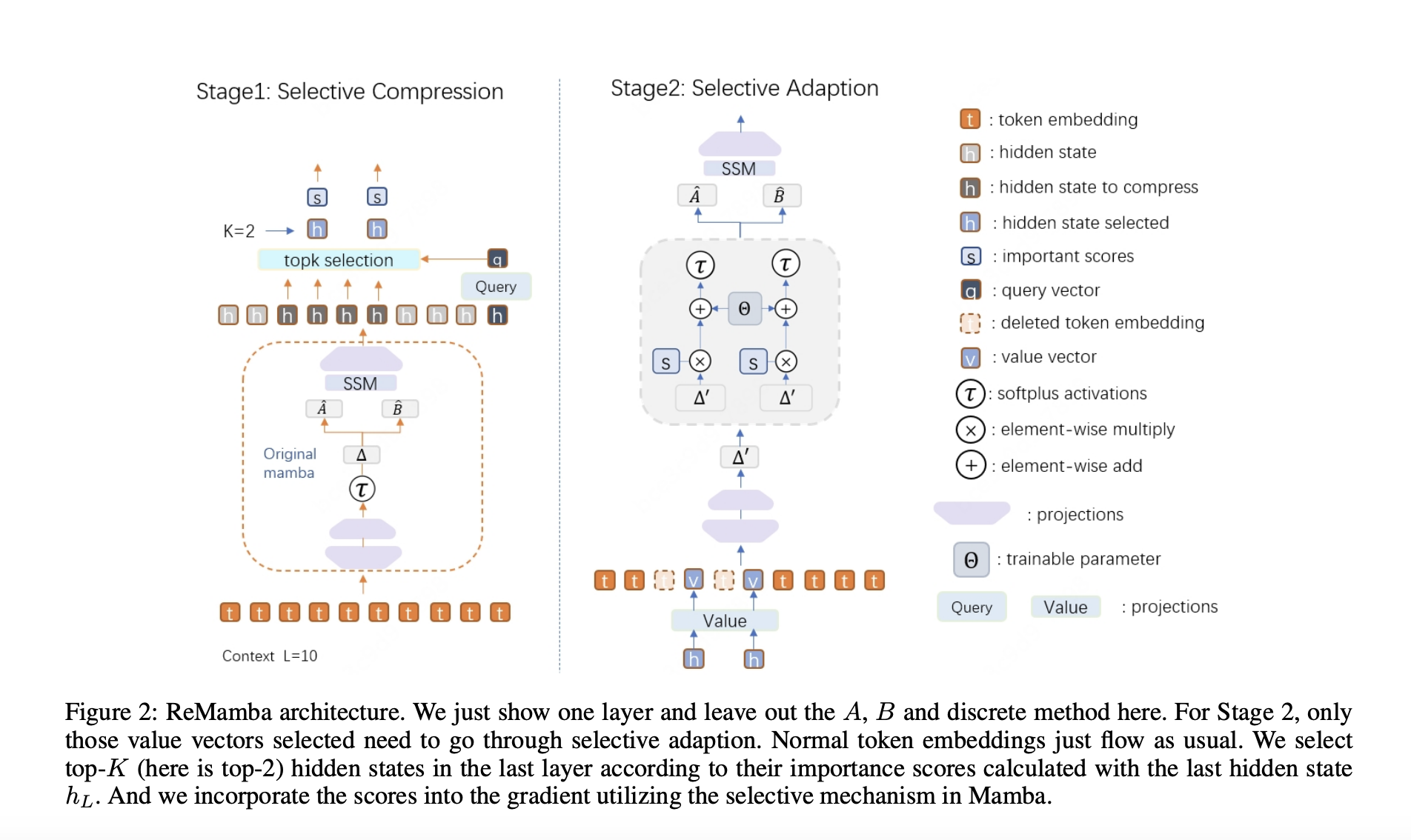
Решение ReMamba для улучшения обработки длинного контекста
Исследователи из Университета Пекина, Национальной ключевой лаборатории общего искусственного интеллекта, 4BIGAI и Meituan представили новую архитектуру под названием ReMamba, разработанную для улучшения возможностей обработки длинного контекста существующей архитектуры Mamba. В то время как Mamba эффективен для задач с коротким контекстом, он показывает значительное снижение производительности при работе с более длинными последовательностями. Исследователи стремились преодолеть это ограничение, реализовав метод селективной компрессии в рамках двухступенчатого процесса повторной передачи. Этот подход позволяет ReMamba сохранять важную информацию из длинных последовательностей без значительного увеличения вычислительной нагрузки, тем самым улучшая общую производительность модели.
Эффективность и результаты ReMamba
Эффективность ReMamba была продемонстрирована через обширные эксперименты на установленных бенчмарках. На бенчмарке LongBench ReMamba превзошел базовую модель Mamba на 3,2 пункта, а на бенчмарке L-Eval достиг улучшения на 1,6 пункта. Эти результаты подчеркивают способность модели приблизиться к уровню производительности моделей на основе трансформеров, которые обычно более мощны в обработке длинных контекстов.
Производительность ReMamba была особенно заметна в способности обрабатывать варьирующиеся длины входных данных. Модель последовательно превосходила базовую модель Mamba при различных длинах контекста, увеличивая эффективную длину контекста до 6000 токенов по сравнению с 4000 токенами для отрегулированной базовой модели Mamba. Это демонстрирует улучшенные возможности ReMamba обрабатывать более длинные последовательности без ущерба для точности или эффективности.
В заключение, модель ReMamba решает критическую проблему моделирования длинных последовательностей с помощью инновационного подхода к компрессии и селективной адаптации. Закрытие разрыва в производительности между Mamba и моделями на основе трансформеров при сохранении вычислительной эффективности делает эту разработку не только практичным решением для ограничений существующих моделей, но и заложило основу для будущих разработок в области обработки длинного контекста в обработке естественного языка.
Подробнее о статье можно найти здесь.
«`

















