

«`html
Исследование моделей зрительно-языковых связей
Исследования моделей зрительно-языковых связей (VLM) набирают обороты благодаря их потенциалу революционизировать различные приложения, включая визуальную помощь для людей с нарушениями зрения. Однако текущие оценки этих моделей часто требуют большего внимания к сложностям, внесенным множественными объектами и разнообразными культурными контекстами. Два значительных исследования проливают свет на эти вопросы, исследуя тонкости галлюцинации объектов в моделях зрительно-языковых связей и важность культурной инклюзивности в их применении.
Множественная галлюцинация объектов
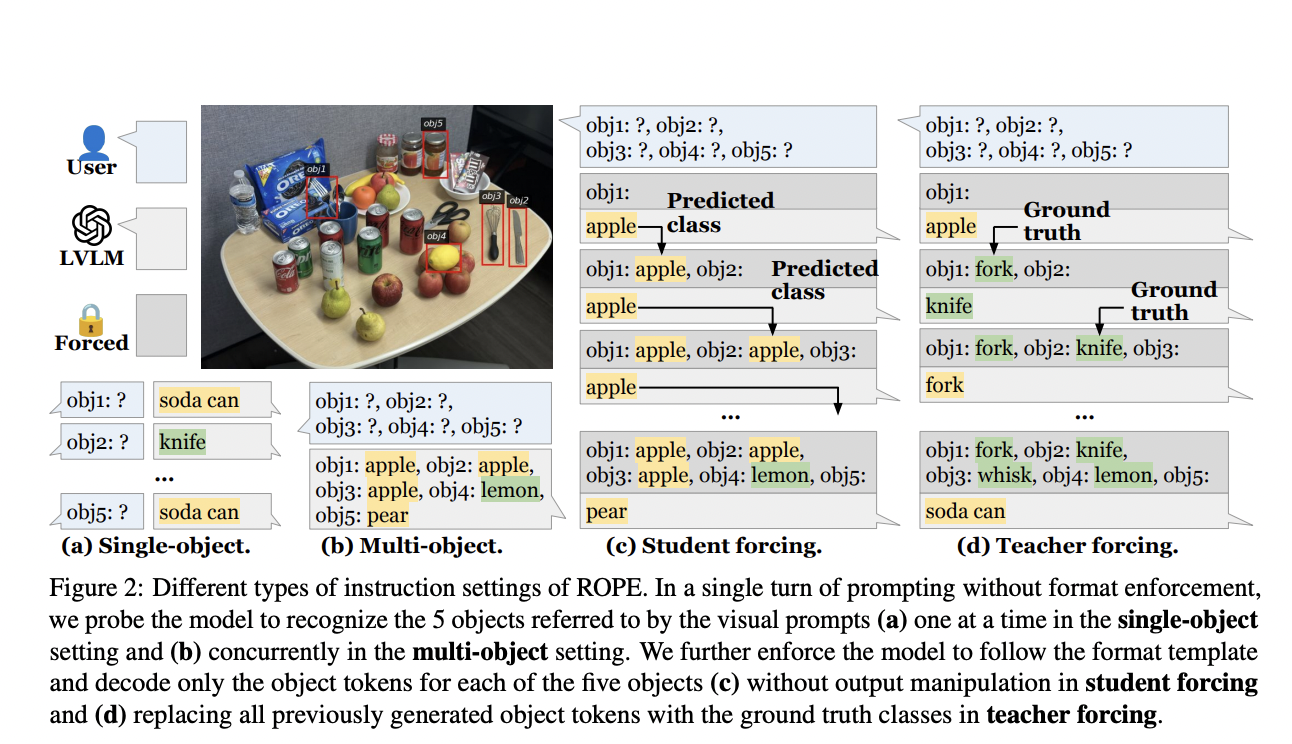
Галлюцинация объектов происходит, когда модели зрительно-языковых связей описывают объекты, которых нет на данном изображении. Это явление, впервые отмеченное в задачах описания изображения, особенно проблематично, когда модели должны распознавать несколько объектов одновременно. Исследование множественной галлюцинации объектов вводит протокол оценки, основанный на распознавании объектов (ROPE) — комплексная методика, разработанная для оценки того, как модели обрабатывают сценарии, включающие множество объектов. Оценка фокусируется на таких факторах, как распределение классов объектов на изображениях и влияние визуальных подсказок на производительность модели.
Протокол ROPE категоризирует тестовые сценарии на четыре подмножества: In-the-Wild, Homogeneous, Heterogeneous и Adversarial. Эта классификация позволяет тонкий анализ поведения моделей в различных условиях. Исследование выявляет, что большие модели зрительно-языковых связей (LVLM) чаще всего галлюцинируют, когда фокусируются на нескольких объектах, чем на одном. Исследование выявляет несколько ключевых факторов, влияющих на поведение галлюцинации, включая атрибуты, специфичные для данных, такие как выразительность и частота объектов, а также внутреннее поведение модели, такое как энтропия токенов и визуальный вклад.
Эмпирические результаты исследования показывают, что множественные галлюцинации объектов распространены в различных LVLM, независимо от их масштаба или данных обучения. Протокол ROPE предоставляет надежный метод оценки и количественного измерения этих галлюцинаций, подчеркивая необходимость более сбалансированных наборов данных и продвинутых протоколов обучения для уменьшения этой проблемы.
Культурная инклюзивность в моделях зрительно-языковых связей
В то время как техническая производительность моделей зрительно-языковых связей крайне важна, их эффективность зависит от их способности учитывать разнообразные культурные контексты. Второе исследование решает эту проблему, предлагая культурно-центричный бенчмарк для оценки VLM. Это исследование подчеркивает разрыв в текущих методах оценки, которые часто должны учитывать культурный контекст пользователей, особенно тех, кто страдает от нарушений зрения.
В рамках исследования создается опрос для сбора предпочтений от лиц с нарушениями зрения относительно включения культурных деталей в описания изображений. На основе результатов опроса исследователи фильтруют набор данных VizWiz — коллекцию изображений, сделанных слепыми людьми — чтобы выявить изображения с неявными культурными отсылками. Этот отфильтрованный набор данных служит в качестве бенчмарка для оценки культурной компетентности современных моделей VLM.
Несколько моделей, как открытые, так и закрытые, оцениваются с использованием этого бенчмарка. Результаты показывают, что, хотя закрытые модели, такие как GPT-4o и Gemini-1.5-Pro, показывают лучшие результаты в генерации культурно значимых описаний, все еще существует значительный разрыв в их способности полностью улавливать тонкости различных культур. Исследование также показывает, что автоматические метрики оценки, часто используемые для оценки производительности моделей, часто должны соответствовать человеческому суждению, особенно в культурно разнообразных средах.
Сравнительный анализ
Сопоставление результатов обоих исследований позволяет понять проблемы, с которыми сталкиваются модели зрительно-языковых связей в реальных приложениях. Проблема множественной галлюцинации объектов подчеркивает технические ограничения текущих моделей, в то время как акцент на культурной инклюзивности подчеркивает необходимость более ориентированных на человека методик оценки.
Технические улучшения:
Протокол ROPE: Введение автоматизированных протоколов оценки, учитывающих распределение классов объектов и визуальные подсказки.
Разнообразие данных: Обеспечение сбалансированных распределений объектов и разнообразных аннотаций в обучающих наборах данных.
Культурные аспекты:
Опросы, ориентированные на пользователей: Включение обратной связи от лиц с нарушениями зрения для определения предпочтений при описании.
Культурные аннотации: Дополнение наборов данных культурно-специфическими аннотациями для улучшения культурной компетентности VLM.
Заключение
Интеграция моделей зрительно-языковых связей в приложения для лиц с нарушениями зрения обещает большие возможности. Однако решение технических и культурных проблем, выявленных в этих исследованиях, крайне важно для реализации этого потенциала. Исследователи и разработчики могут создать более надежные и удобные для пользователей модели зрительно-языковых связей, приняв комплексные методики оценки, такие как ROPE, и интегрировав культурную инклюзивность в обучение и оценку моделей. Эти усилия улучшат точность этих моделей и обеспечат их лучшее соответствие разнообразным потребностям пользователей.
Посмотрите Статью 1 и Статью 2. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашим сообществам в Telegram и LinkedIn.
Если вас интересует партнерство в продвижении (контент/реклама/рассылка), заполните эту форму.
Оригинальная статья: Enhancing Vision-Language Models: Addressing Multi-Object Hallucination and Cultural Inclusivity for Improved Visual Assistance in Diverse Contexts на MarkTechPost.
«`
















